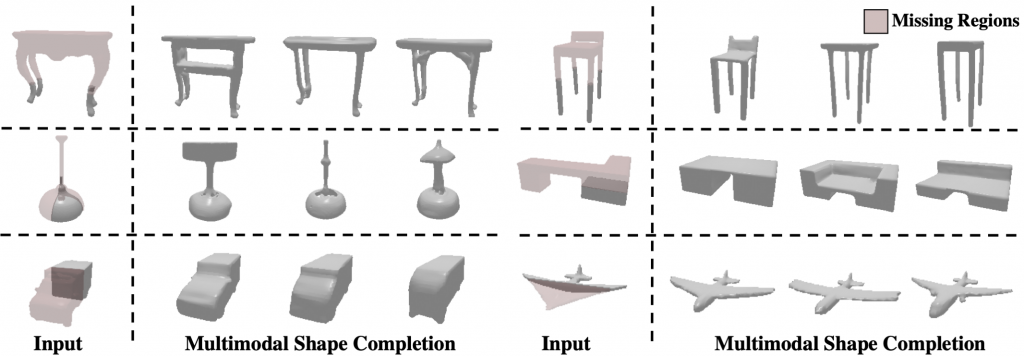
Qualitative Comparisons for Shape Completion
Qualitative Comparisons for Single View Reconstruction

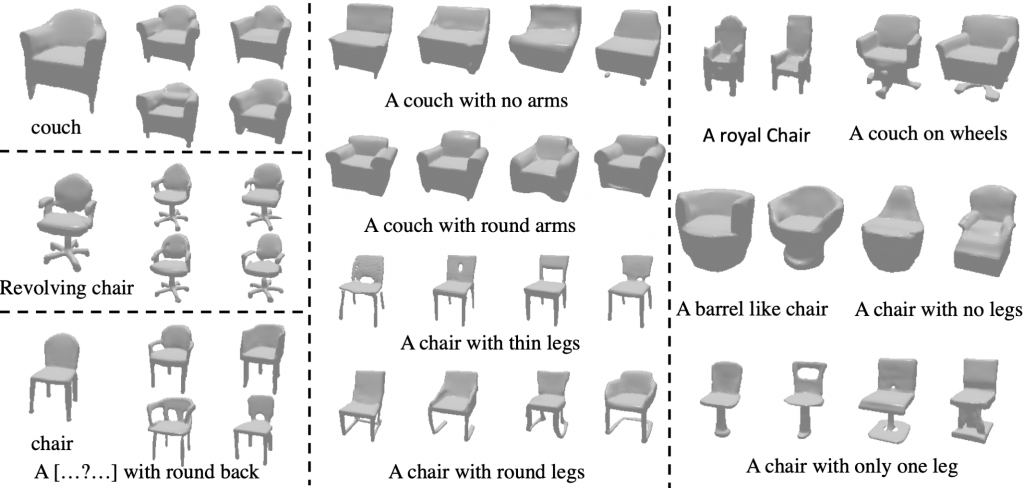
Qualitative Comparisons for Language based Generations
For more of our amazing results please visit here.
Autoregressive Conditional Generation using Transformers
Students: Yen-Chi Cheng, Paritosh Mittal | Advisors: Maneesh Singh (Verisk), Shubham Tulsiani (CMU) | Sponsor: Verisk
For more of our amazing results please visit here.