Our work AutoSDF is accepted in CVPR-22
Useful Links:
Spring 22 Final Presentation [slides][video]
Mid-term Progress Presentation [slides]
Autoregressive Conditional Generation using Transformers
Students: Yen-Chi Cheng, Paritosh Mittal | Advisors: Maneesh Singh (Verisk), Shubham Tulsiani (CMU) | Sponsor: Verisk
Our proposed approach AutoSDF can faithfully capture the geometry of shapes from the ShapeNet dataset. However, it is limited by the need for volumetric 3D shape representations for training or fine-tuning.
We propose to learn the appearance of objects (color) together with geometry (vanilla AutoSDF) to enable extension to novel categories where volumetric 3D is not available (but 2D image based guidance is).
To enable this, we first leverage the ability of Plenoxels to learn a voxel-like 3D representation of objects from images using volume rendering. For each voxel, appearance information is stored as spherical harmonic coefficients.
Rendering of a chair instance from ShapeNet using the voxel-based representation from Plenoxel.
We are generating the grids for all object instances for categories in ShapeNet following which we plan to train our AutSDF on such 3D representations
Using an autoregressive transformer over a set of latent symbols can be thought of as learning a language of shapes. Inspired by this thought, we plan to use shape-primitives (cylinder, cone, plane, etc.) as building blocks of modern shapes. The aim is to learn an autoregressive model (similar to the shape prior in AutoSDF) over such primitives. We first use the 3D CAD models from the ABC dataset and aim to extract surfaces of primitive categories.
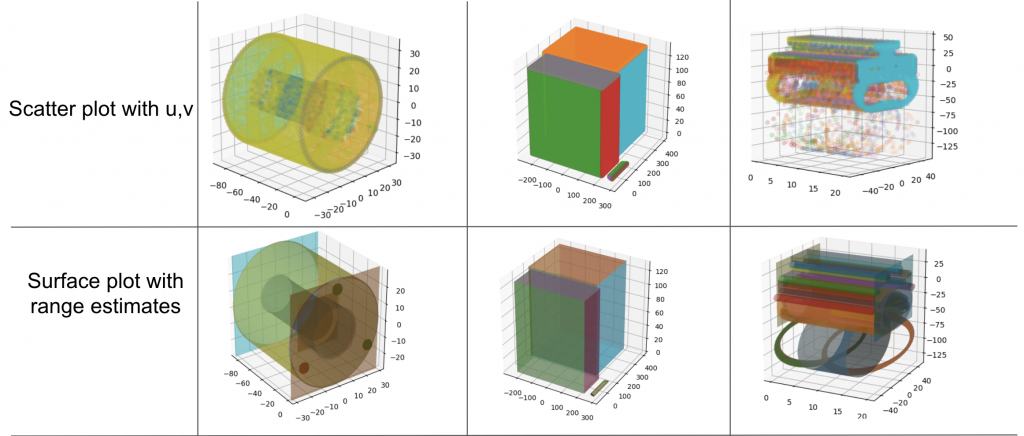
We are still finding a way to extract a tree-like generative sequence to create shapes from primitives. Once extracted, we can restructure the data and train a shape prior based on such primitives.