Visual odometry

We remodel our visual odometry module such that it can be used in unseen environments as well. To this end, we take 2 RGB frames from different timesteps and find the relative pose of the glasses at the 2 timesteps.
We utilize the general Structure from Motion pipeline for this purpose starting with finding robust matched correspondences. We use Superpoint (and SuperGlue) for finding reliable correspondences between the 2 image frames. Using these matched correspondences, we find the Essential matrix. The E matrix is now decomposed to find the relative rotation and translation between the 2 frames.
We observe that the error in rotation and translation increases with increasing the timestep gap between 2 frames.
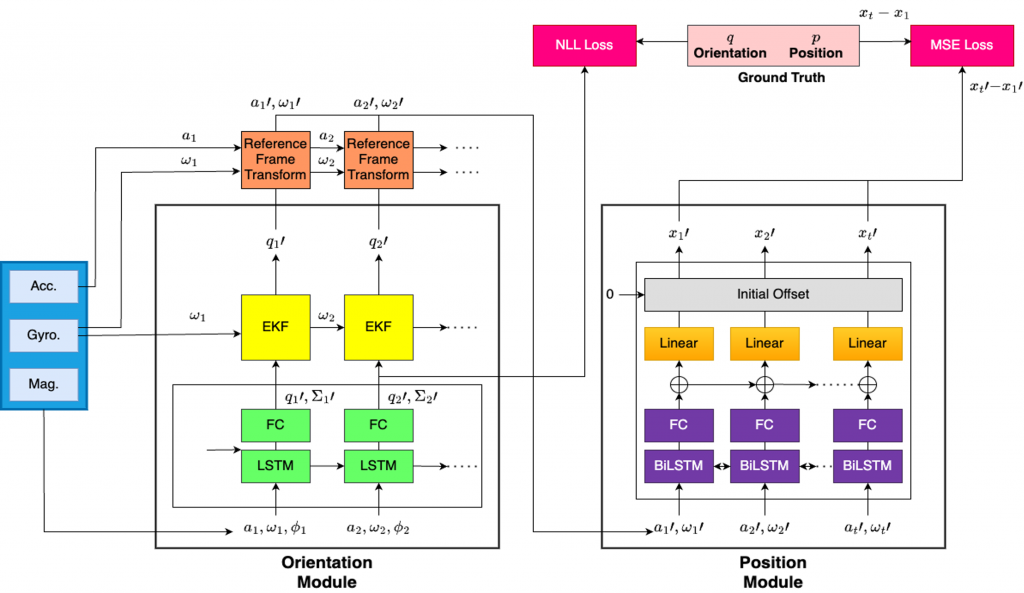
Inertial odometry

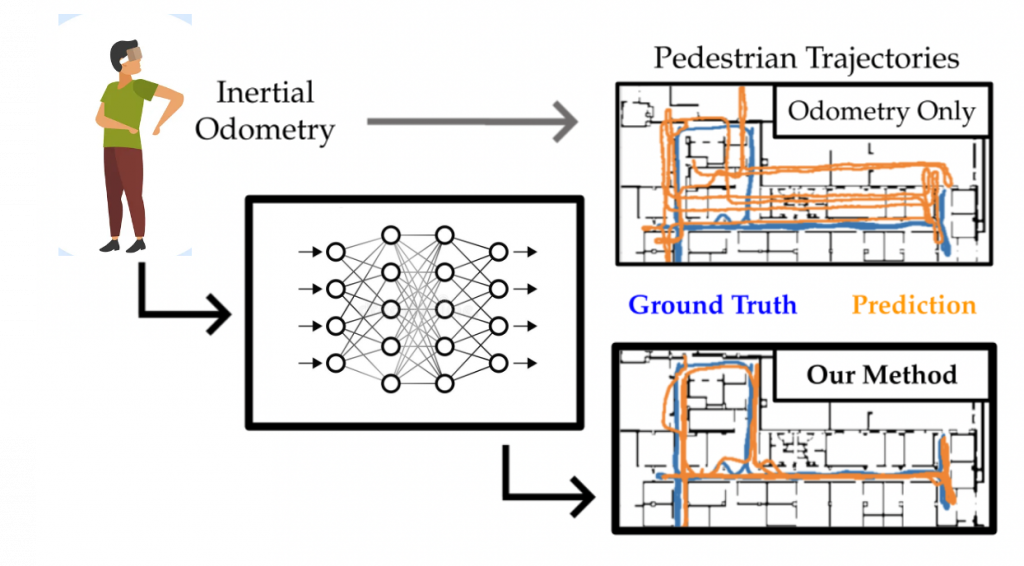
We use the IDOL model with extension to 6-D pose instead of 5-D pose to be used with the visual odometry predictions.
Classifier

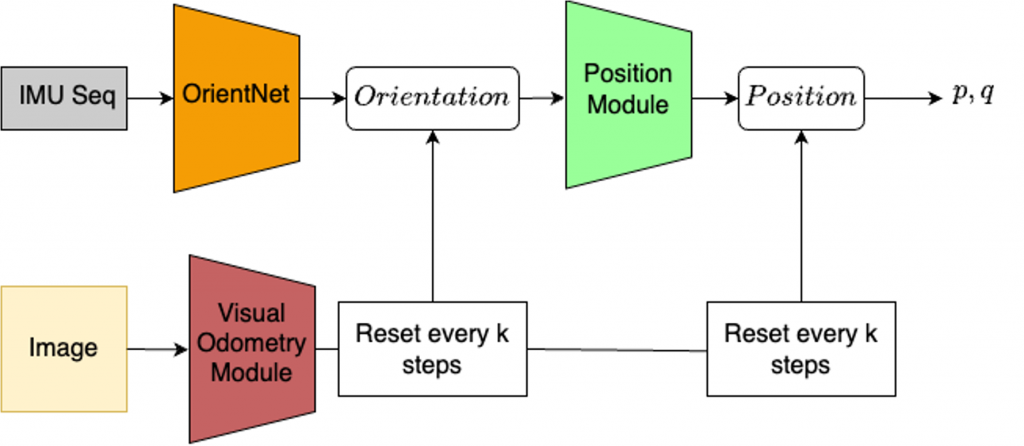
We aim to use the visual odometry module only when there is a major drift in the inertial odometry module. We use a classifier for this purpose. The classifier is trained on ground truth poses and the IDOL’s pose predictions using a hyperparameter threshold. The model architecture is a simple 3-layered MLP.
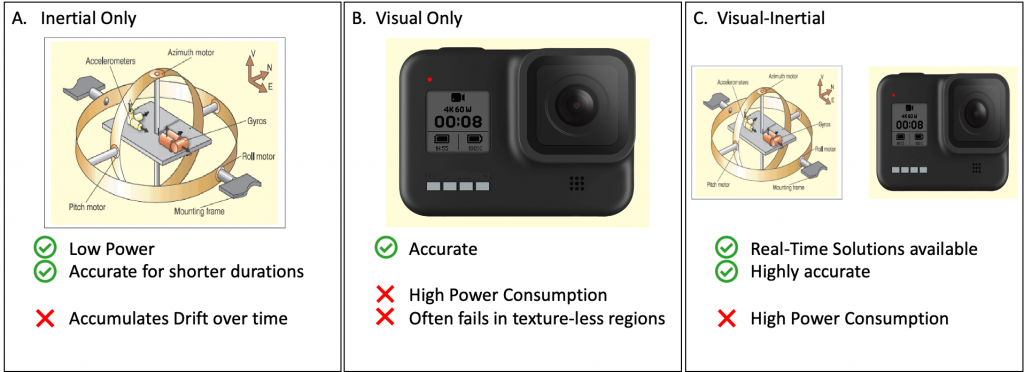
Visual-Inertial odometry

When we combine the VO and IO predictions in a weighted fashion and turn on the camera based on the classifier’s predictions, we are able to get accurate pose predictions with very low power consumption.