VISUAL ODOMETRY MODULE

We implement PoseNet with InceptionNet backbone with appropriate changes to the final fully-connected layers to regress the 7D pose i.e. 3D position (x, y, z) and 4D quaternion.
We train this model on the dataset collected in the basement of Smith Hall using Aria Glasses. For establishing our baseline, we have also tested our model on the King’s College Dataset in order to compare it against PoseNet[1] implementation.
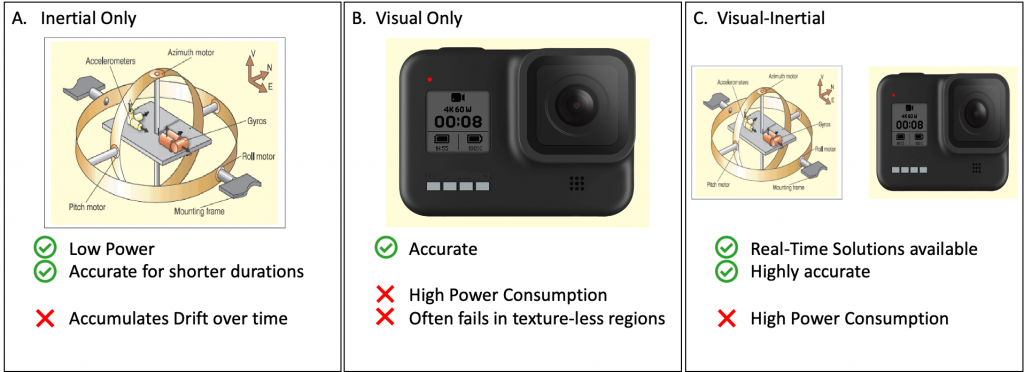
Using the RGB camera ensures that the predicted pose is quite accurate with the only downside of a higher power consumption.
INERTIAL ODOMETRY MODULE
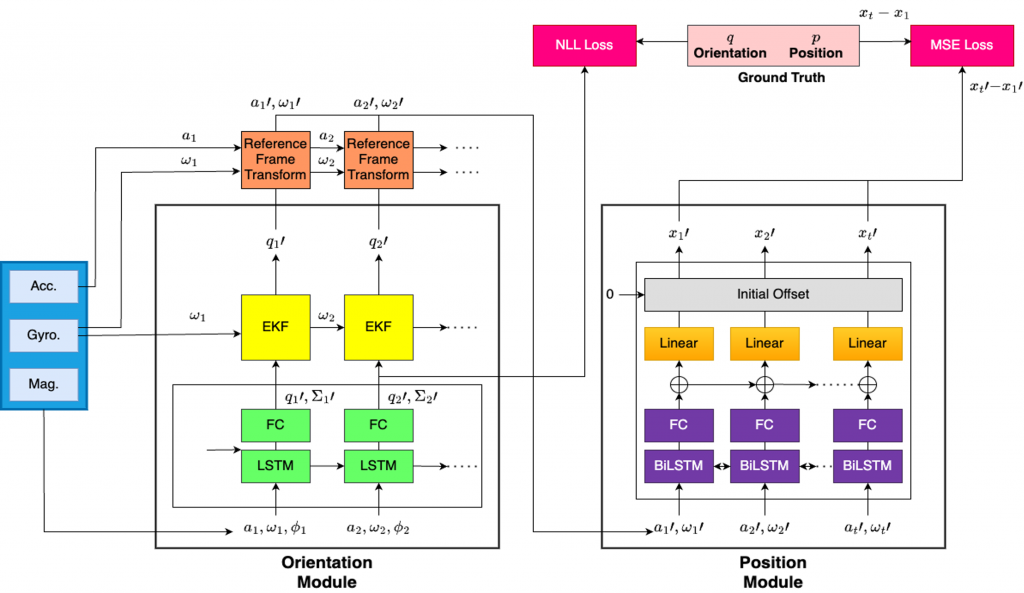
We use IDOL: Inertial Deep Orientation-Estimation and Localization[2] architecture as our baseline. We have trained this model on IDOL dataset and also on our dataset collected using Aria glasses.
This model aims to regress the pose using IMU readings.
These sensors can operate using very low power consumption but they accumulate drift quickly over time. Hence, they are accurate only for a short duration.
COMBINED LOW-POWER VISUAL-INERTIAL ODOMETRY MODULE
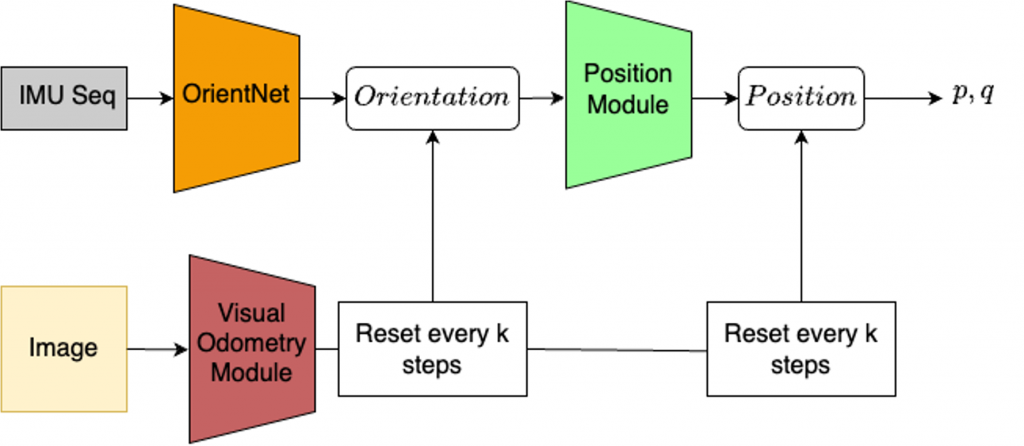
In order to find a balance between the pros and cons of the visual odometry system and the inertial odometry system, we combine the inertial odometry model with the visual odometry model. We use the visual odometry prediction after every kth timestep such that we can reset the inertial odometry system which has collected drift till this timestep.
We try to find the best possible ‘k’ value which strikes the balance between power consumption i.e. frequency of RGB frames used v/s the accuracy of the overall predictions.
OVERVIEW OF THE ABOVE METHODS
REFERENCES
[1] Kendall, Alex, et al. “PoseNet: A Convolutional Network for Real-Time 6-DOF Camera Relocalization”, IEEE International Conference on Computer Vision (ICCV), 2015
[2] Sun, Scott, et al. “IDOL: Inertial Deep Orientation-Estimation and Localization“, AAAI Conference on Artificial Intelligence, 2021