
Large Language Model (LLM)
A large language model can be used for a wide variety of tasks:
- Text Generation: Generate realistic and coherent text on a wide range of topics, from short phrases to longer essays and even entire books.
- Content Analysis: Analyze large volumes of text data to identify patterns, extract insights, and generate reports.
Our Usage: To enhance the semantic information of the input text description, we leverage the large language model to paraphrase the input sentence in more action detail. We will use both the original text and the paraphrased text to aid in the synthesis of 3D human motion at a later stage. This method is inspired by the following paper.
Generative Model (Diffusion Model)
Diffusion Model is a type of latent variable model that utilizes a fixed Markov chain to map to the latent space. This Markov chain incrementally adds noise to the data in order to estimate the approximate posterior distribution of the latent variables x1 to xT, which have the same dimensionality as x0. The figure below illustrates how this Markov chain is applied to image data.
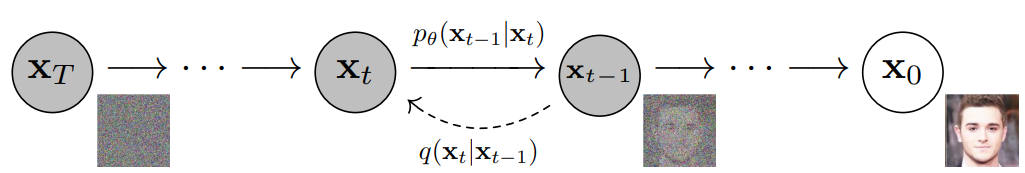
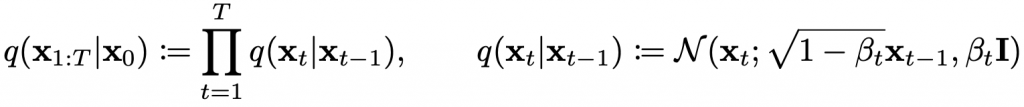
At the end of the diffusion process, the image is gradually transformed into pure Gaussian noise. The primary objective of training a diffusion model is to learn the reverse process of this transformation, i.e., training the model to predict p(xt-1|xt). This enables us to generate new data by traversing backwards along the Markov chain.
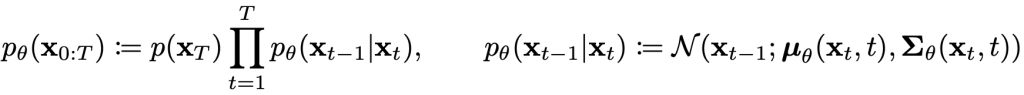
Our Usage: Our framework adopt the reverse process of diffusion model to acquire a sequence of SMPL parameters. These SMPL parameters are then transform to mesh via pre-defined rendering process, producing 3d human motion.
Human Motion Diffusion Model
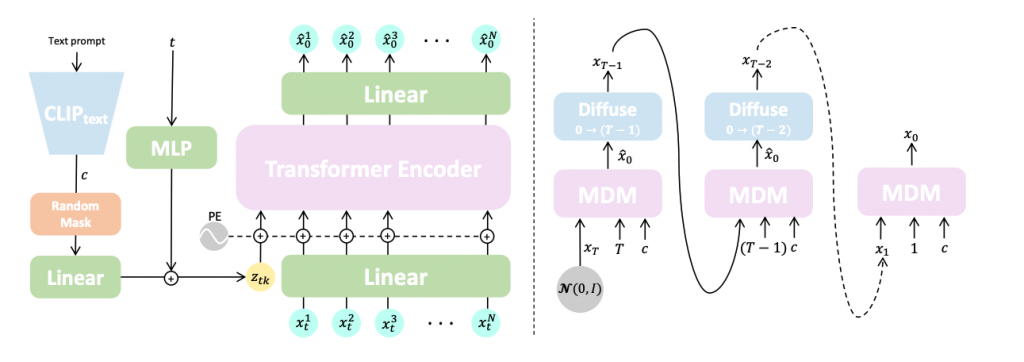
Motion Diffusion Model (MDM) is a diffusion-based text-driven human motion generative model with a transformer-based architecture. A key aspect of MDM is its focus on predicting the sample directly at each step of the diffusion rather than the noise. The model applies geometric losses on the locations and velocities of the motion to improve the quality of the generated motions. MDM achieves state-of-the-art results on leading benchmarks for text-to-motion.
Our Usage: MDM is the main baseline for our MotionGPT, and our model is built upon it.
IMoS: Intent-Driven Full-Body Motion Synthesis for Human-Object Interactions
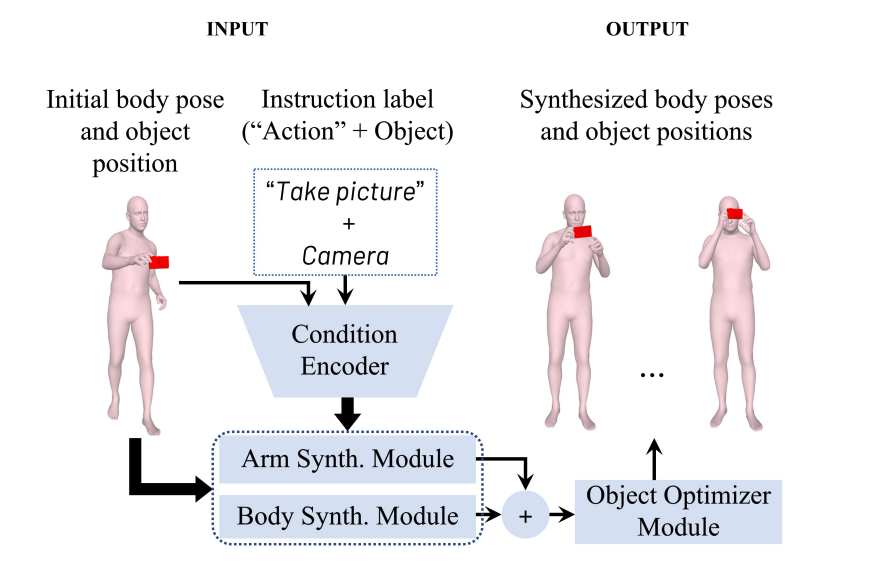
IMOS consists of two modules: the Arms Synthesis Module and the Body Synthesis Module, which are responsible for generating the arm movements and the rest of the body’s motion, respectively. These modules are controlled by a Condition Encoder, which leverages instruction labels and body shape parameters to generate the condition token. In the final stage, an Object Optimizer Module refines the object’s six degrees of freedom parameters to ensure that the model’s output adheres to the physical constraints of grasping. The final result of this process is a complete, full-body motion sequence that aligns with the object’s optimized positions. IMOS achieves state-of-the-art results for the task of intent-driven motion synthesis.
Our Usage: IMOS is one of the few works that address human-object interactions. Since it is most related to our goal, it is chosen as our main baseline.
Hand-Object Contact Consistency Reasoning for Human Grasps Generation
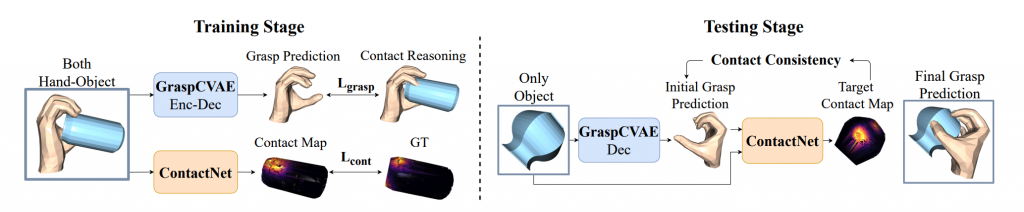
This work introduces a new approach GraspTTA for generating human hand grasps for objects. It focuses on ensuring the realism and stability of these grasps by considering the consistency of contact between the hand and the object. Two distinct networks are created: one for generating the grasp and another for predicting the contact map. During inference, these networks work together through contact consistency to refine the grasps on unseen objects. This framework produces more realistic and stable grasps and also exhibits strong generalization to unseen object.
Our Usage: Our hand-object contactness module is inspired by this work. The difference is this work generates a static hand pose, while ours generates a motion sequence.