
We proposes a new approach, called MotionGPT, to address the limitations of previous text-based human motion generation methods by utilizing the extensive semantic information available in large language models (LLMs).
Framework of MotionGPT
We first pretrain a doubly text-conditional motion diffusion model on both high-level (such as “greeting a friend”) and low-level (such as “hug” or “wave hand”) ground truth text data. Then during inference, we improve motion diversity and alignment with the training set, by zero-shot prompting GPT-3 for additional “low-level” details.
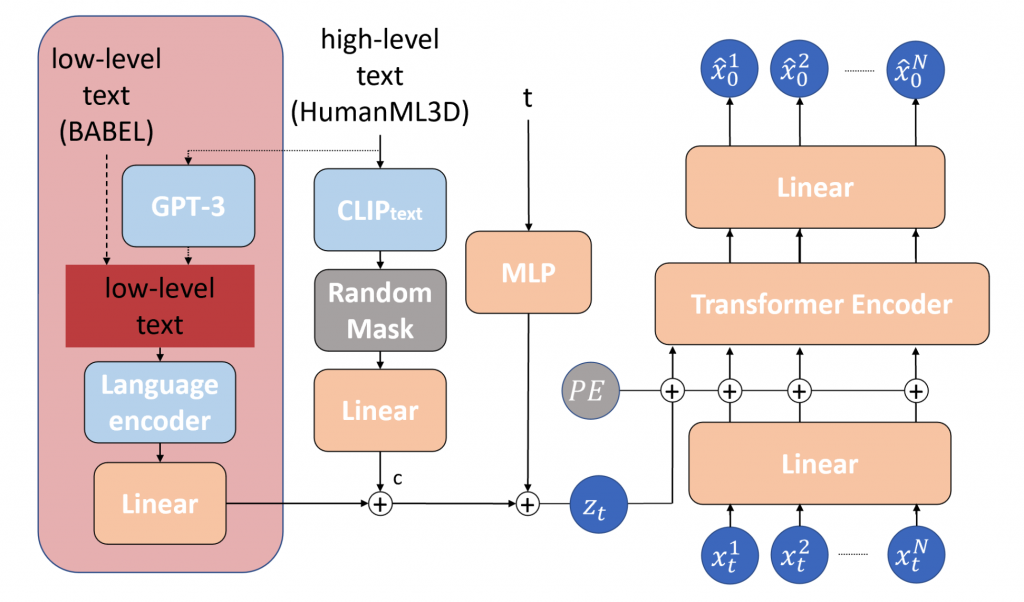
Our denoising network architecture is based on MDM and employs a transformer with four inputs: the training motion sample x of variable length, the encoding of the denoising step index t, the positional embedding of the temporal ordering of motion frames, and the conditioning vector x. These inputs are linearly projected into a common 512-dimension space and added together to form the input of the transformer encoder.
GPT-3 Prompting
During inference, we utilize zero-shot prompting for the GPT-3 LLM to generate “low-level” descriptions for each “high-level” test query.
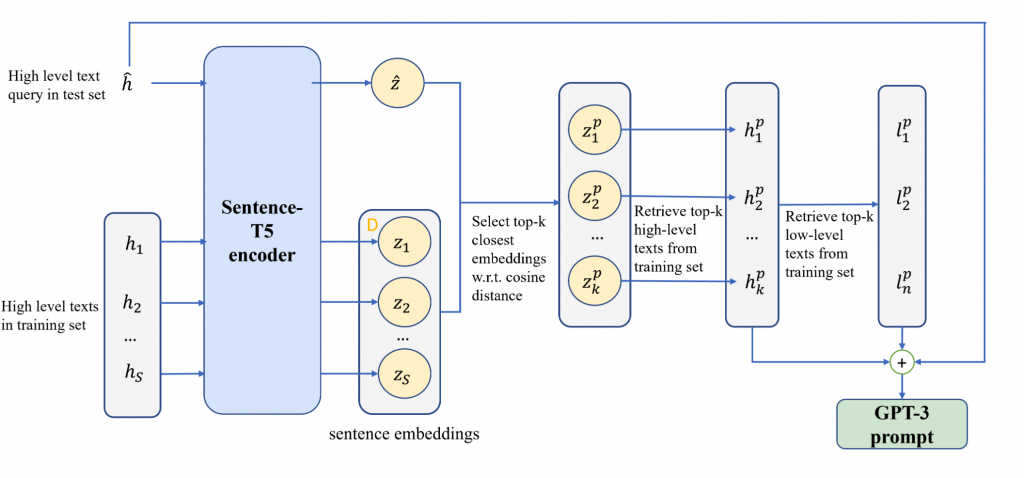
The Sentence-T5 encoder is used to map the “high-level” test query and the “high-level” texts of the training set to the embedding space. We retrieve the top-k “high-level” training texts that are closest to the test query in terms of cosine distance, as well as their respective “low-level” counterparts. The GPT-3 prompt is formed by concatenating the retrieved “high-” and “low-level” training texts and the test query.
This approach has two benefits:
- it increases the diversity of text prompts, resulting in a wider range of generated motions.
- it allows for better generalization by achieving greater similarity to the training data distribution. This is done by breaking down hard “high-level” test set descriptions into similar “low-level” actions found in the training set.
Physics-based Regulator
To make the synthesized human motion more natural, we enforce the following physical constraint as extra learning objective. Here we use the same ones as MDM, metioned in Related Work Section.
Foot Contact Constraint:
Goal: Make the foot contact the ground appropriately.
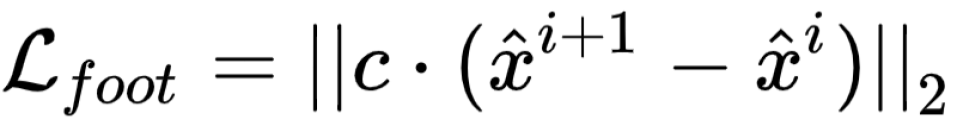
c is the ground truth mask indicating whether the feet contact the ground. If there is contact, we should stop the movement of the feet.
Temporal Constraint:
Goal: Make the human motion smooth.
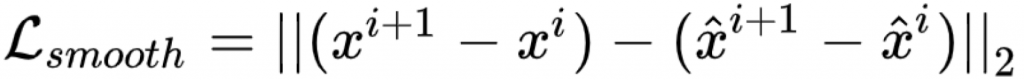
This constraint enforce the velocity of the synthesized motion should be the same as the ground truth velocity.