
Text, Paraphrase, and Synthesize

Large Language Model (LLM)
A large language model can be used for a wide variety of tasks:
- Text Generation: Generate realistic and coherent text on a wide range of topics, from short phrases to longer essays and even entire books.
- Content Analysis: Analyze large volumes of text data to identify patterns, extract insights, and generate reports.
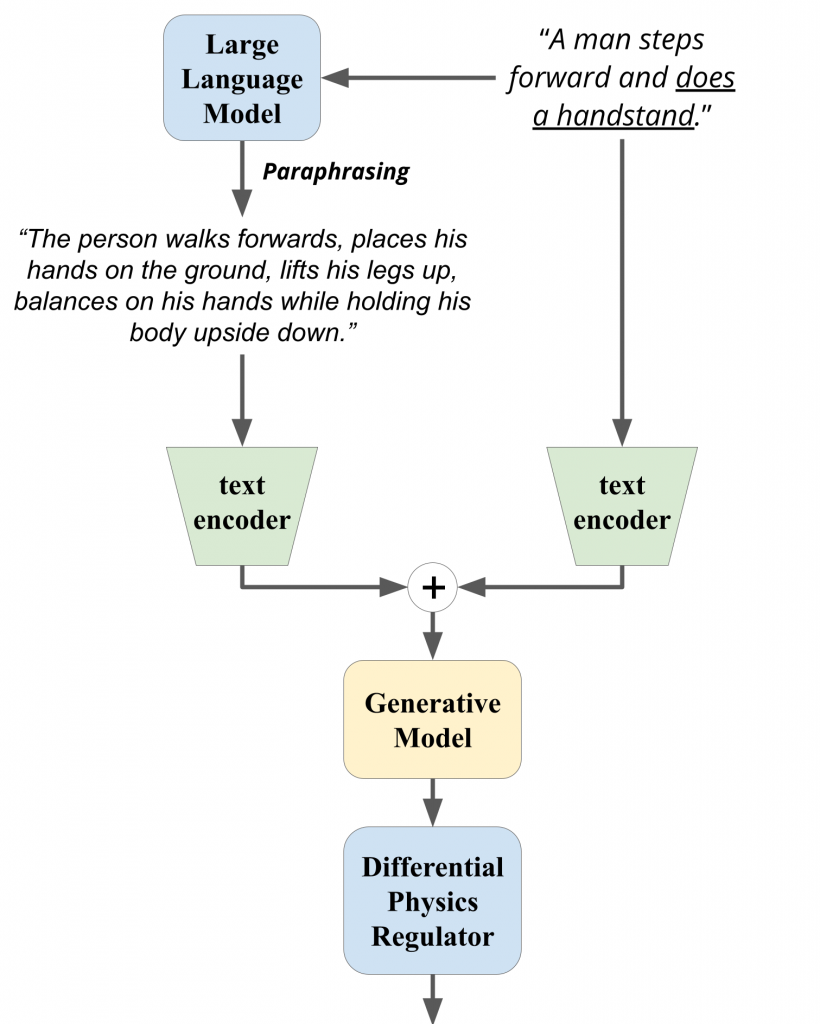
Our Usage: To enhance the semantic information of the input text description, we leverage the large language model to paraphrase the input sentence in more action detail. We will use both the original text and the paraphrased text to aid in the synthesis of 3D human motion at a later stage. This method is inspired by the following paper.
Generative Model (Diffusion Model)
Diffusion Model is a type of latent variable model that utilizes a fixed Markov chain to map to the latent space. This Markov chain incrementally adds noise to the data in order to estimate the approximate posterior distribution of the latent variables x1 to xT, which have the same dimensionality as x0. The figure below illustrates how this Markov chain is applied to image data.
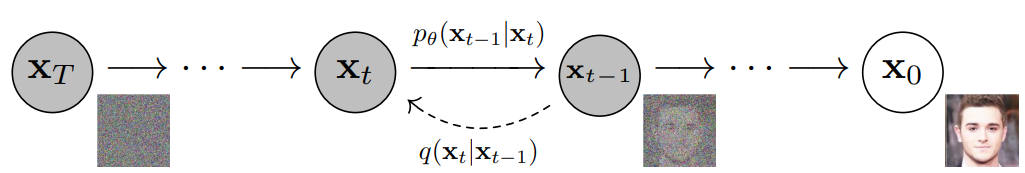
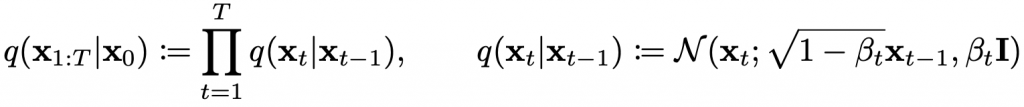
At the end of the diffusion process, the image is gradually transformed into pure Gaussian noise. The primary objective of training a diffusion model is to learn the reverse process of this transformation, i.e., training the model to predict p(xt-1|xt). This enables us to generate new data by traversing backwards along the Markov chain.
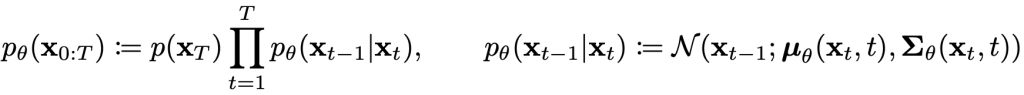
Our Usage: Our framework adopt the reverse process of diffusion model to acquire a sequence of SMPL parameters. These SMPL parameters are then transform to mesh via pre-defined rendering process, producing 3d human motion.
Physics-based Regulator
To make the synthesized human motion more natural, we enforce the following physical constraint as extra learning objective.
Foot Contact Constraint:
Goal: Make the foot contact the ground appropriately.
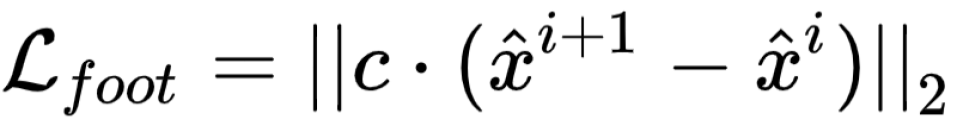
c is the ground truth mask indicating whether the feet contact the ground. If there is contact, we should stop the movement of the feet.
Temporal Constraint:
Goal: Make the human motion smooth.
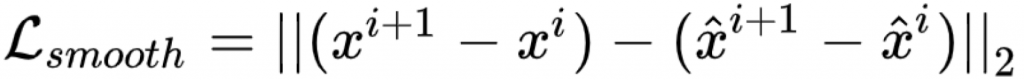
This constraint enforce the velocity of the synthesized motion should be the same as the ground truth velocity.