
Our framework consists of two modules, a human-object interaction synthesis module to generate the full-body motion and a hand-object interaction synthesis module to refine hand pose and hand-object interaction.
Human-Object Interaction Synthesis
We propose a framework controlling existing diffusion-based text-driven human motion synthesis model to perform hand-object interaction by prompt engineering.
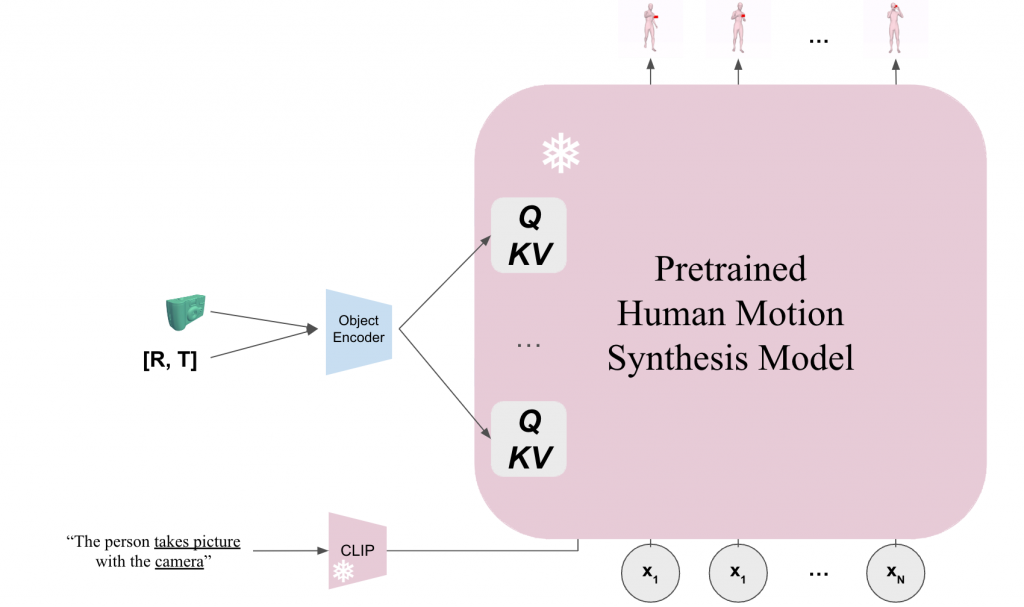
A CLIP text encoder is first used to process the text prompt to text embedding, which is used as an input for the human motion synthesis model. We use an object encoder with an initial object mesh as input and the output embedding is used to control the synthesis process of the frozen pretrained diffusion-based human motion synthesis model.
Hand-Object Contactness Module
Our hand-object contactness module contains two networks: a hand pose CVAE model, which generates the hand pose, and a Contactnet, which generates the contact region on the object. A contact consistency optimization module is designed to use the contact region prediction to further refine the hand pose. This framework is inspired by the GraspTTA model mentioned in the related work.
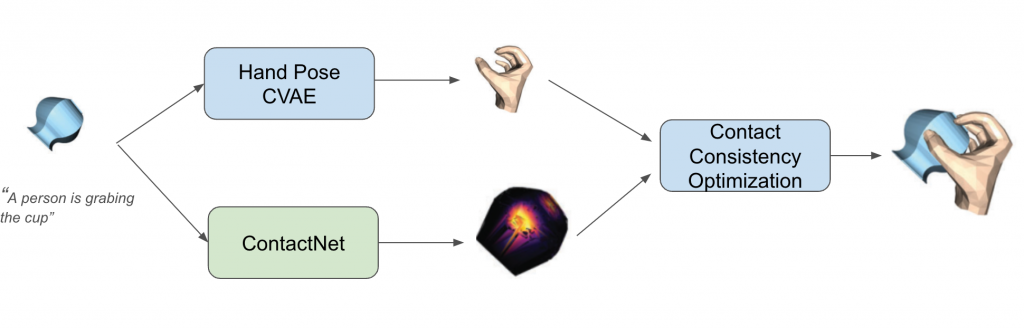
The ContactNet is a ConvNet with text and object point cloud as input, and the contact region is predicted as a 2-class (contact/not-contact) classification task.
The other parts of this framework are still under refinements so they are not elaborated. We present preliminary results in the Experiments Section.