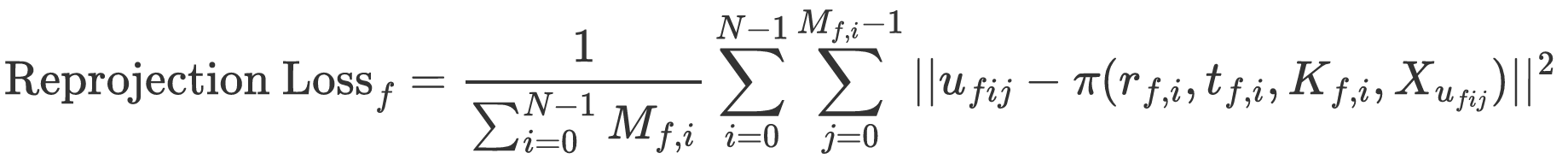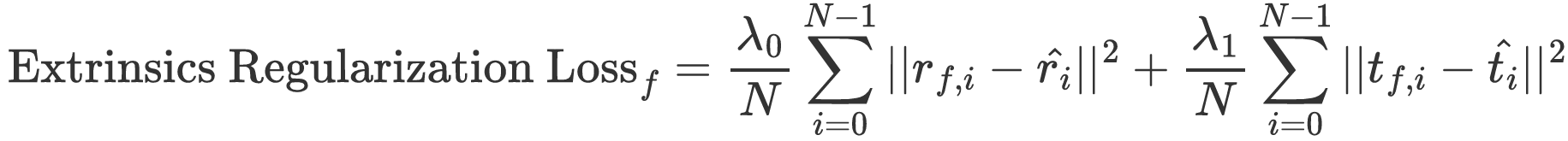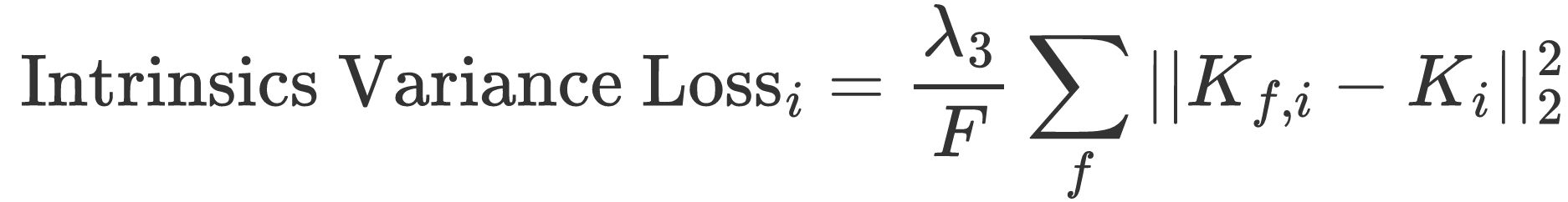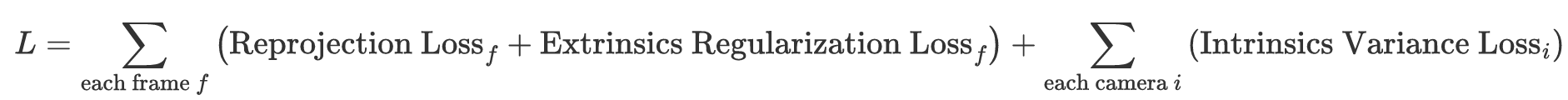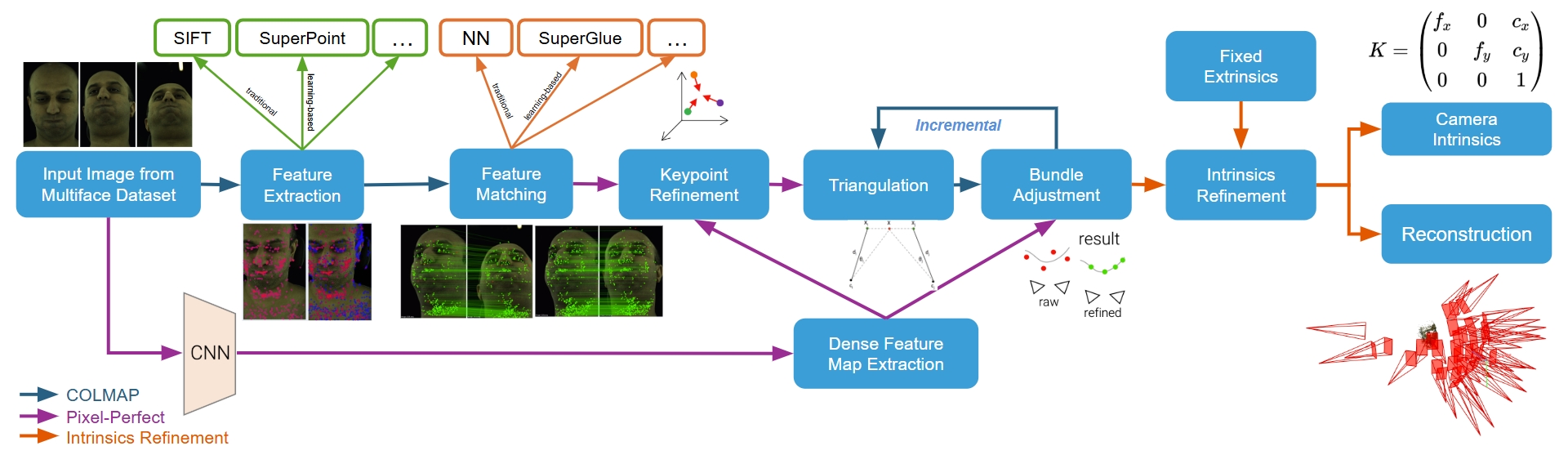
Our method is based on COLMAP. We use SuperPoint and SuperGlue for feature extraction and matching. We apply Pixel-Perfect refinement to COLMAP to refine the detected keypoints before triangulation and reconstructed 3D points in bundle adjustment. We also implement an intrinsics refinement stage after the bundle adjustment stage to improve the recovered camera intrinsics and reconstructed scene using ground-truth extrinsics.
Input RGB Images
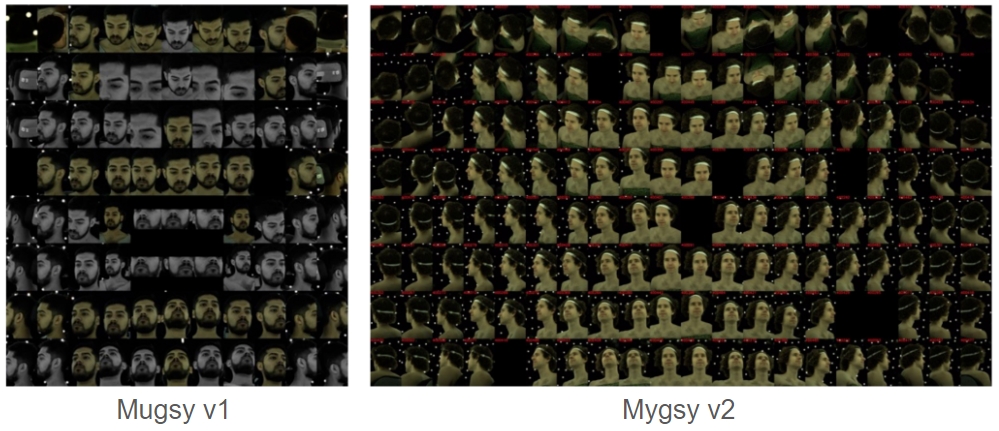
Input images are from Multiface dataset, which are captured by multiple cameras from multiple views.
Feature Extraction
Firstly, 2D keypoints and their feature descriptors are extracted from the input images. We experimented with both traditional (e.g. SIFT) and learning-based (e.g. SuperPoint) feature extractors. Compared to SIFT, SuperPoint can yield more robust and accurate results.
Feature Matching

The keypoints detected in the previous step are matched using feature matching algorithms. We experimented with both traditional (e.g. Nearest Neighbour) and learning-based (e.g. SuperGlue) matching algorithms. SuperGlue uses a Graph Neural Network with self- and cross-attention to improve feature representations, and yield better matching results.
Keypoint Refinement
A dense feature map is computed for each input image by a deep CNN. Then, these feature maps are used to refined the 2D keypoints. Specifically, we use Pixel-Perfect to adjust the locations of 2D keypoints belonging to the same track by optimizing its featuremetric consistency along tentative matches with a cost function:
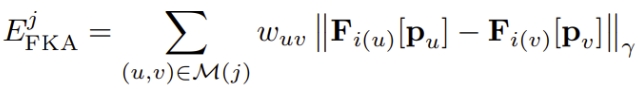
Triangulation
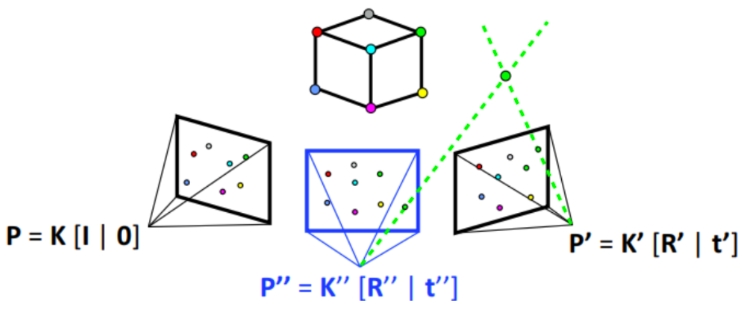
In the triangulation stage, 3D points are computed from predicted camera intrinsics and extrinsics and keypoint positions.
Bundle Adjustment
In the bundle adjustment stage, camera intrinsics and extrinsics and triangulated points are jointly optimized. We also use aforementioned dense feature maps produced by Pixel-Perfect. Specifically, they are refined using a featuremetric cost:
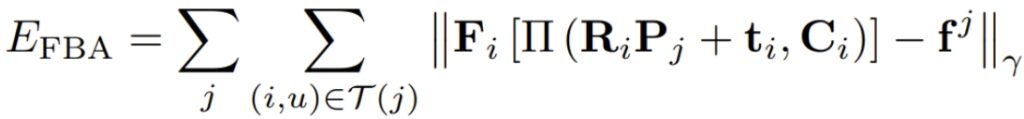
Intrinsics Refinement
An additional refinement stage is applied to optimize intrinsic parameters using known ground-truth extrinsics.
Instead of directly replacing estimated extrinsics with ground-truth values, we introduce an extrinsics regularization term with a gradually increasing coefficient during optimization. This approach converts the constraint from a hard replacement to a more flexible adjustment, thereby mitigating the risk of local minima.
We also introduce an intrinsics variance term to jointly optimize intrinsics across all frames, resulting in a more global and consistent calibration. This contrasts with COLMAP and PixelSfM, where intrinsics are refined independently for each frame.