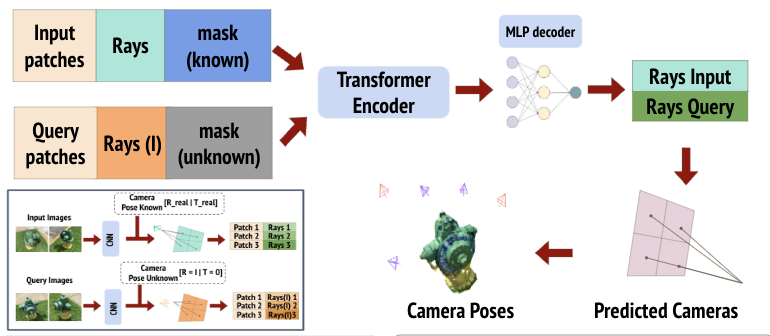
Overview
Structure from Motion(SfM) is a powerful technique that leverages a collection of multiview images of a scene or object to reconstruct its 3-dimensional structure. It finds various applications in fields such as Geosciences, virtual reality, and autonomous vehicles. However, traditional SfM methods demand a dense set of images with multiple viewpoints to generate an accurate 3D reconstruction of the scene. In practice, obtaining such dense sets of images can be challenging or even impractical. Recent research has focused on developing sparse-view 3D reconstruction methods to overcome this challenge of generating accurate 3D reconstructions from a limited set of views. Building upon the success of the SRT in scene representation, we propose a novel method for sparse view 3D reconstruction inspired by the SRT. Our method aims to achieve accurate 3D reconstruction from a sparse set of images, which can significantly reduce the acquisition costs and time in real-world scenarios.
Structure from Motion
Structure from Motion (SfM) is a technique that utilizes a set of images from multiple views of a scene or an object to reconstruct its 3-dimensional structure.
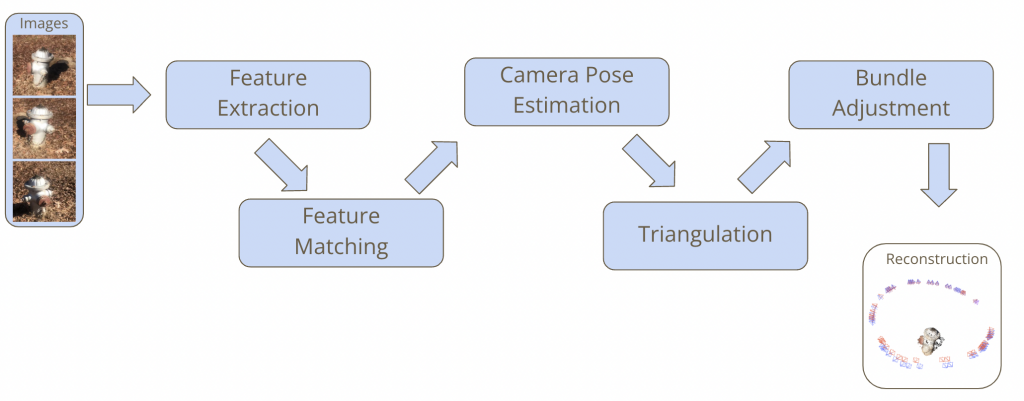
A general SfM pipeline includes 5 steps:
- Feature Extraction: Extracting interest points from each image
- Feature Matching: Generating correspondences between pairs of images
- Pose Estimation: Determining the position and orientation of the camera relative to a reference
- Triangulation: Determining points in 3D space given their projections onto two or more images
- Bundle Adjustment: Jointly refining the 3D reconstructed points and the camera parameters by minimizing a reprojection error
Problem Setup
Upon implementing the general Structure from Motion (SfM) pipeline with the HLOC library, we observed that for the traditional SfM pipeline to effectively reconstruct the 3D models, two critical requirements must be met:
- A significant number of images must be available.
- The images must exhibit good overlap with each other.
This brings us to a problem setup:
Given a set of few images, can we estimate good cameras poses and generate accurate 3D points?