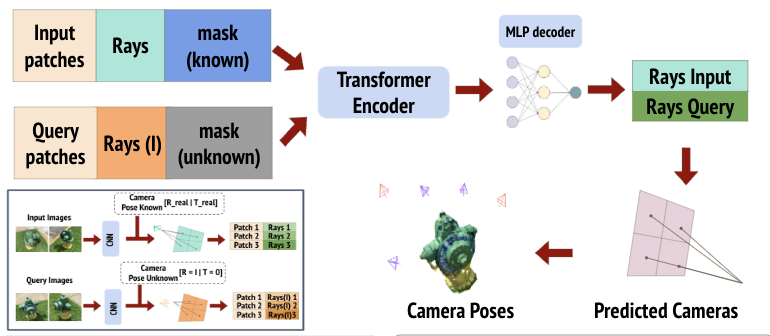
Data-Driven SfM pipeline
As mentioned in the introduction, we want to solve SfM using data-driving priors. We created a driver which utilizes different learning feature extractions and learning feature matching methods to see how the data-driven priors can help with sets of few Images.
Datasets
Custom Daily Common Objects
We created our own dataset which consists of 360-degree images of 11 objects that are found in our day-to-day activities. Each category consists of multi-view images with 10-23 viewpoints. To establish a baseline we first tested the data-driven SfM pipeline on our own datasets. Link to the dataset.

Results

We tested the data-driven SfM pipeline on the Co3D v2 dataset. The Co3D V2 dataset is designed for learning category-specific 3D reconstruction and new-view synthesis using multi-view images of common object categories.
The dataset contains a total of 1.5 million frames from nearly 19,000 videos capturing objects from 50 MS-COCO categories, and, as such, it is significantly larger than alternatives both in terms of the number of categories and objects.

We chose one of the hydrant categories from the Co3D v2 dataset and ran the data-driven SfM pipeline on it. We randomly sampled different numbers of images from the dataset with the provided ground-truth cameras and compared the average rotation error and the number of estimated poses with different inputs.
Results
| Number of images | Average rotation error | Number of poses estimated |
| 50 | 0.056 | 50 |
| 20 | 0.665 | 14 |
| 10 | Not Converged | 0 |

the blue cameras are the ground truth cameras provided in the dataset, and the red ones are predictions from the SfM pipeline.