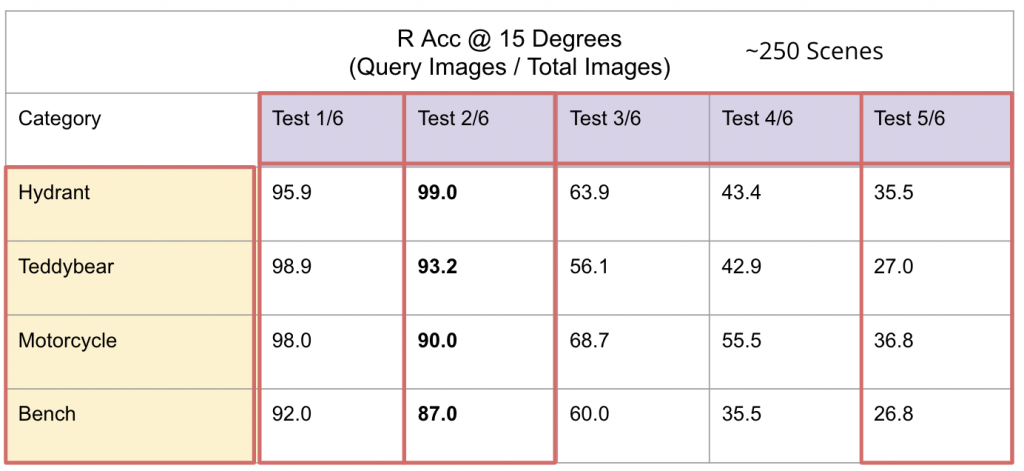
Overview
SRT has a limitation in that it utilizes a rudimentary approach to concatenate the camera pose with the image features. Specifically, every patch receives the same pose encoding, which is suboptimal, given that we can leverage geometric information. Moreover, it is possible to enhance the model further by eliminating the transformer decoder and opting for an encoder-only architecture that directly regresses the pose. This architecture is akin to mask auto-encoders and can yield significant improvements.
Pipeline
Our approach involves computing input patches while appending patch-specific ray encodings to process a given set of input and query images. Similarly, we repeat the process for query images, but we use identity pose cameras. We further augment the encoding by including a set that helps the model distinguish between rays from known cameras and those from the query. The resulting query features are concatenated with the input features and encoded together. At the end of the model, a 2-layer MLP is used to regress the patch rays. Subsequently, the rays are employed to retrieve the cameras. During training, the model is exposed to six images, where the pose for two of them is masked.
Results
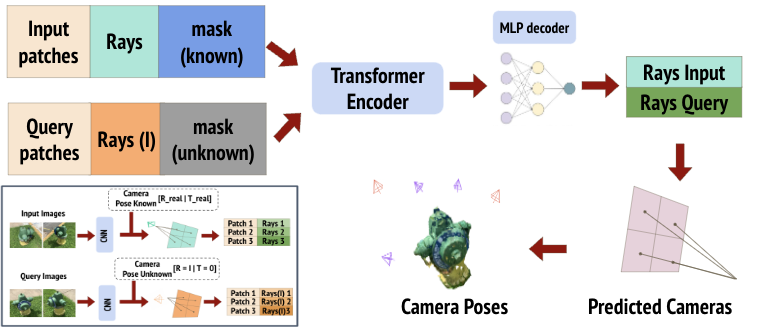
Qualitative Results
We present some qualitative findings from our study, comparing the input images (in green) and query images (in blue) against the model’s predictions. Remarkably, the model demonstrates an impressive ability to accurately predict the query cameras.
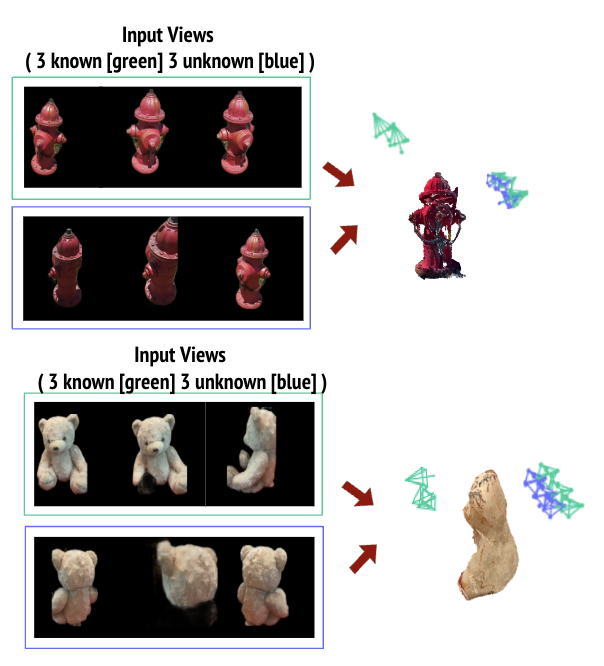
Quantitative Results
We evaluated the performance of our model using the Co3d v2 dataset, which comprises approximately 250 sequences from four object categories. To test the robustness of the model, we varied the number of query views from one to five. Notably, the scenario with two query views and four input views yielded the best results, given that this was the method used for training. Intriguingly, we discovered that reducing the number of query images to just one resulted in better performance on average, as one would expect, given the reduced unknown information. However, an unexpected finding was that the model still achieved an accuracy of around 30%, even with just one input view. We attribute this impressive outcome to the utilization of data-driven priors.