
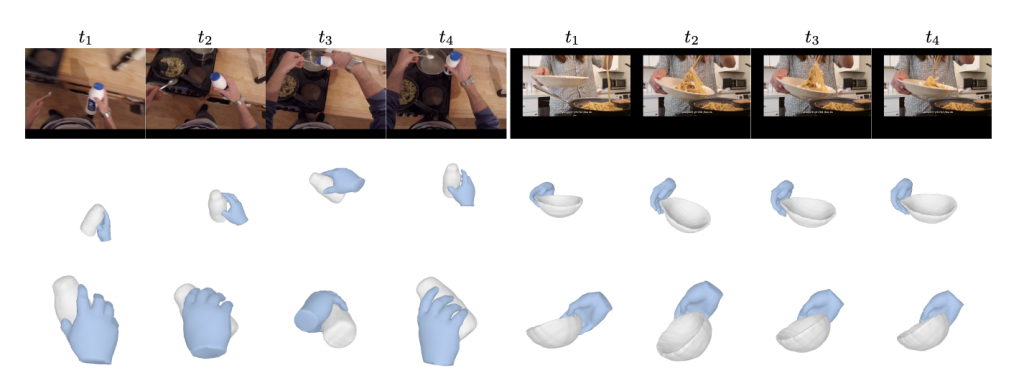
Given a video clip depicting a hand interacting with a rigid object, we aim to infer the underlying 3D shape of both the hand and the object, i.e:
- 3D shape of the object (ϕ)
- Texture of the hand (β)
- Intrinsics of the camera (Kt)
- Per frame articulation of the hand (θtA)
- Per frame object pose (Th→o)
- Per frame camera pose (Tc→h)
Idea: Hand a visual cue for Object Shape
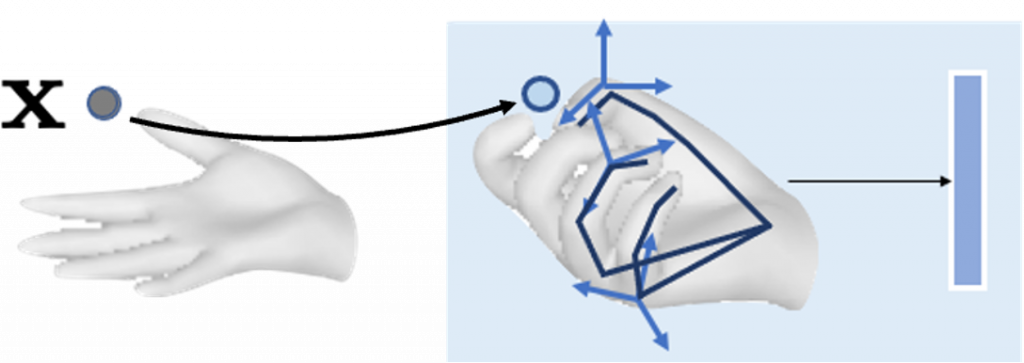
Hand can actually be thought of as a special occluder. There are 2 reasons behind this idea:
- Hand pose is predictive of the object’s shape. For example, When we pinch our fingers together, we are very likely to hold thin sticks, (like pens, nails, and brushes.)
- The current hand pose reconstruction system is quite robust to occlusion and their prediction can often be trusted.
Given an image (a single frame), we therefore try to simultaneously optimize 2 things for a good reconstruction: i) Estimate the underlying hand pose and ii) infer the object shape in a normalized hand-centric coordinate frame. We anticipate explicit articulation conditioning to help the inference. Extending it to a dynamic setting, we intend to consider the Neural Field of the scene and fit a prior about the understanding of the possible valid shapes of the object.
Given the model, we can then get a per-frame prediction of the interaction and since the NeRF belongs to a valid human-object pair, we expect the frame predictions to be consistent.