
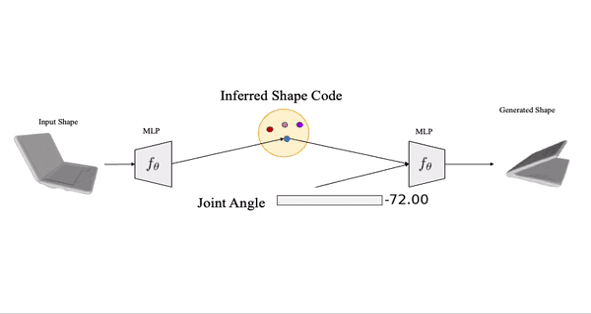
Now that we had satisfactory reconstruction results for rigid objects, we would like to look into extending it to articulating hand-held objects, i.e given some degrees of freedom for the object how can we reconstruct the underlying HOI.
Motivation:
Reconstructing the geometry, kinematics, and appearance of articulated objects is another fundamental CV problem with important applications in robotics, AR, and VR.
Objective:
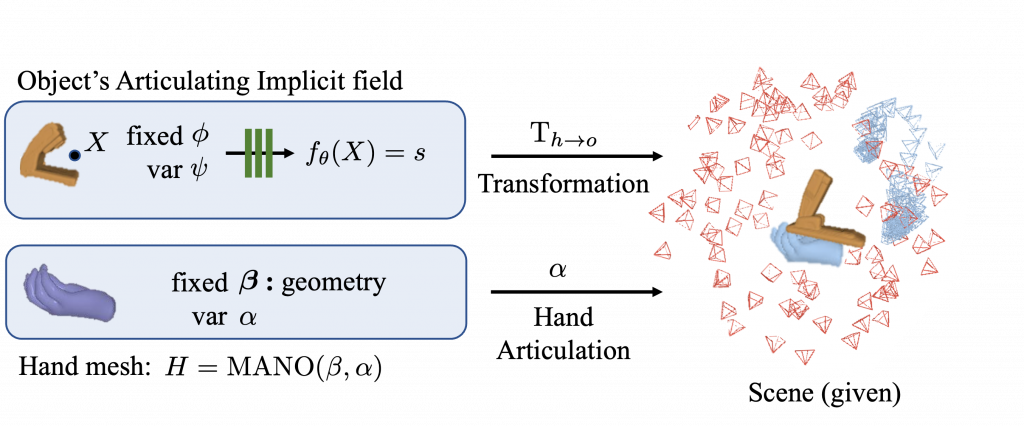
Given an RGBD video of a hand interacting with an articulating object along with the camera intrinsics, we aim to reconstruct the underlying hand-object interactions, i.e.,
- The 3D shape of the object
- Per-frame camera pose
- Per-frame articulation of the object
Prior Work:
Most Prior works are on static objects:
- Learn to map shape codes to 3D objects
- Recover geometry and appearance for a single scene via differentiable rendering
For articulated objects, many of the prior works (including A-SDF sota approach) model shapes with strong priors and large datasets like human bodies, but we aim for more generic objects.
Issues with Prior work (A-SDF):
- Uses Ground truth Extrinsics and scale for every frame: We intend to optimize for it as well
- Optimizes for shape for every frame individually and doesn’t share a common shape, scale across the video -> leads to inconsistent objects throughout the video.
We therefore intend to:
- Optimize for the camera extrinsics as well.
- Share a common shape code across all the frame reconstructions and allow only the articulation, and extrinsics to vary in the video.
Expected Approach:
The approach would be the same as before except that there would be an extra articulation parameter for every frame and the objects implicit field would no longer be time persistent it would have a shape code and a separate time varying articulation code.
Methodology:
While training, given ѱ and sdf values, we optimize for Φ and the model θ. (Inspired by ASDF)
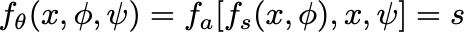
During inference, given instance X, we recover Φ and ѱ. We then can interpolate and extrapolate in the articulation space for ѱ to generate unseen instances.
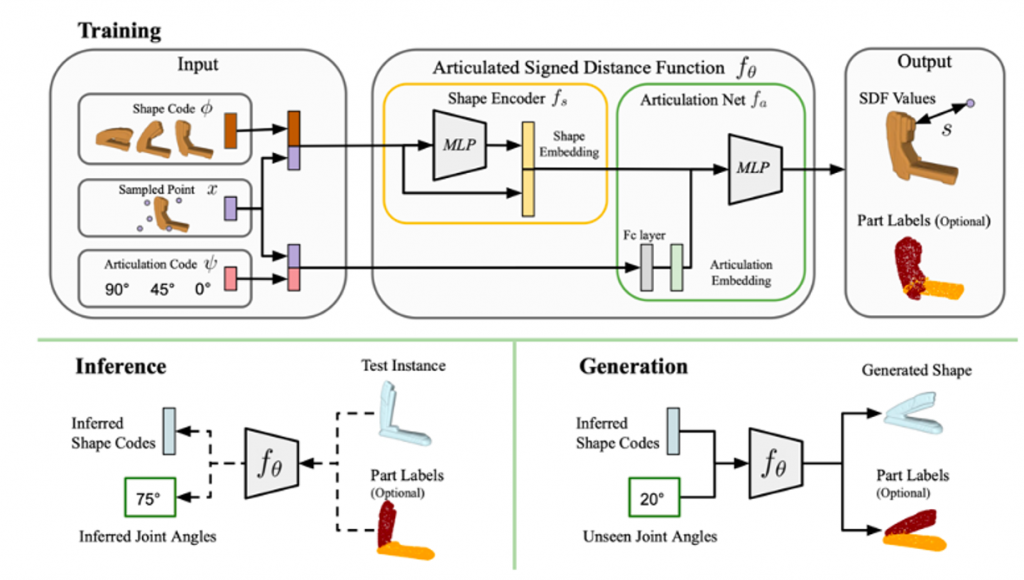
We tweak the A-SDF Framework to accept a Depth image instead of a SDF instance by basicaly perturbing the surface point cloud with the surface normal to get sdf values for points near the surface (See pseudocode below).

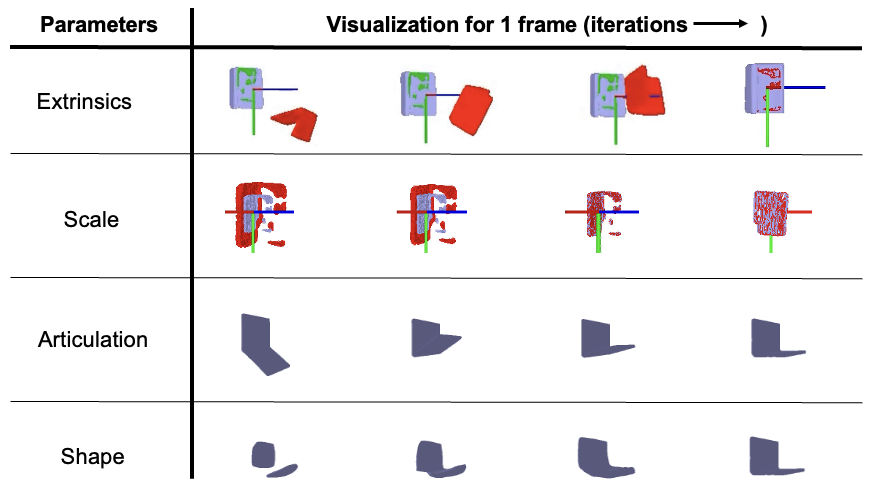
Stage-wise optimization:
We optimize for each of the extrinsics, scale, articulation, shape of the articulating object per frame of the video. While the scale and the shape of the object are time persistent, the camera intrinsics and the object articulation is not. The rows below depict the role every parameter plays in improving the reconstruction.
Note: The optimizations above are isolated just for visualizations. We optimize for multiple parameters in some stages.
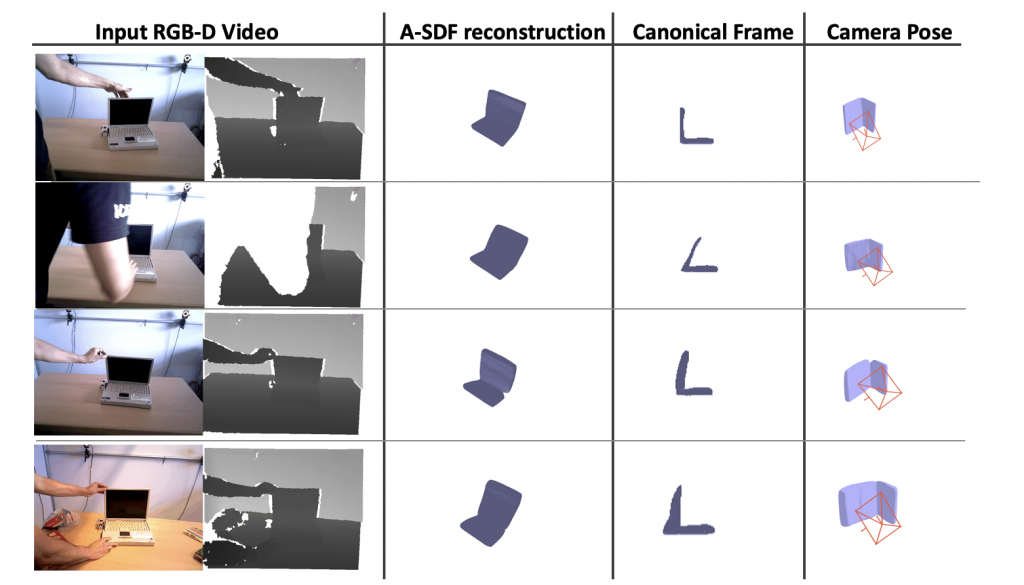
Results:
- Some reconstruction results in image view and canonical view for some articulating laptop instances from RBO dataset are as follows:
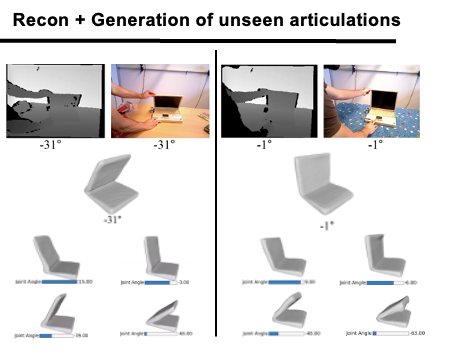
2. Generation results of unseen articulations of the same laptop by interpolating/ extrapolating in the articulation space:
3. For few other articulating classes from shape2motion dataset, the results are as follows (rows: laptop, spectacles, door, stapler):

Some tricks:
For achieving the above consistent and improved results (compared to prior SOTA works), we employ specific tricks:
- Initialize with multiple extrinsics, articulations and rank to chose the best one using a proxy task with lesser optimization stages and lesser iterations
- Trajectory smoothness: We employ a constraint on the first derivative for the camera extrinsics trajectory and the articulation of the object since the velocity with which the camera is moving and the articulation of the object is changing is usually approximately constant.
Future Work:
We intend to extend this pipeline to run on multiple datasets like
I also intend to work on the following in the Winter Break:
- Better Visualizations
- Interpolating, extrapolating articulations
- Wrap it as a tool that given an RGBD video, extracts the parameters and reconstructs the sequence
- Possibly combine it with Yufei’s work and add hands and predicting grasp points, affordances to the framework
- Documentation and making the codebase usable for others
Possible directions the project can take:
- Remove depth from the pipeline: Reconstruct articulating objects only using monocular RGB videos.
- Reconstructing in-the-wild articulating objects using monocular videos (currently it is object-specific)
- Reconstruct any in-the-wild deformable object
- Adding hand to the scene: Predicting contact points and affordances for reconstructing and synthesizing possible human object interactions given a video of an articulating object.