Model Diagnosis
Given a target CV model of interest and a pretrained diffusion model, our goals for model diagnosis:
- Can we evaluate the sensitivity of the target model to arbitrary visual attributes without a test set?
- Better yet, can we discover relevant attributes in an unsupervised manner?
Our work builds on the Zero-shot Model Diagnosis paper published in CVPR 2023 [4]. In this paper, the authors measure sensitivity of user given attributes using StyleGAN. We hope to extend this work by proposing a methodology that is completely unsupervised and that leverages the high expressive power of diffusion models.
We are actively exploring three different approaches:
- #1: Hyperplane optimization for attribute boundary
- #2: Implicit function edit of diffusion h-space and/or e-space
- #3: LLM-aided attribute discovery
Hyperplane Optimization for attribute boundary
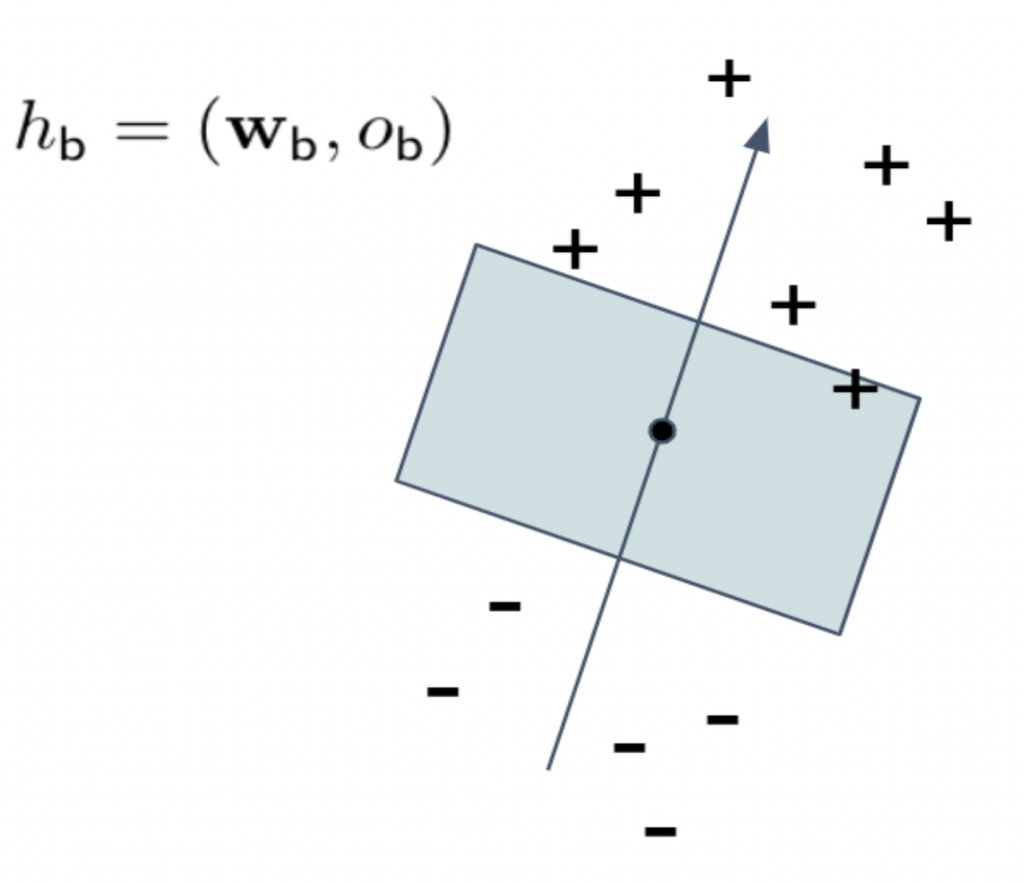
The key insight for this approach motivated by [1] and [3], where arbitrary attributes can be found in the latent space (of the generative model) through a hyperplane that separates the positive and negative examples. For our purpose, we want to optimize this hyperplane to find the most adversarial attributes given a target model.
Implicit Function edit of diffusion h-space and/or e-space
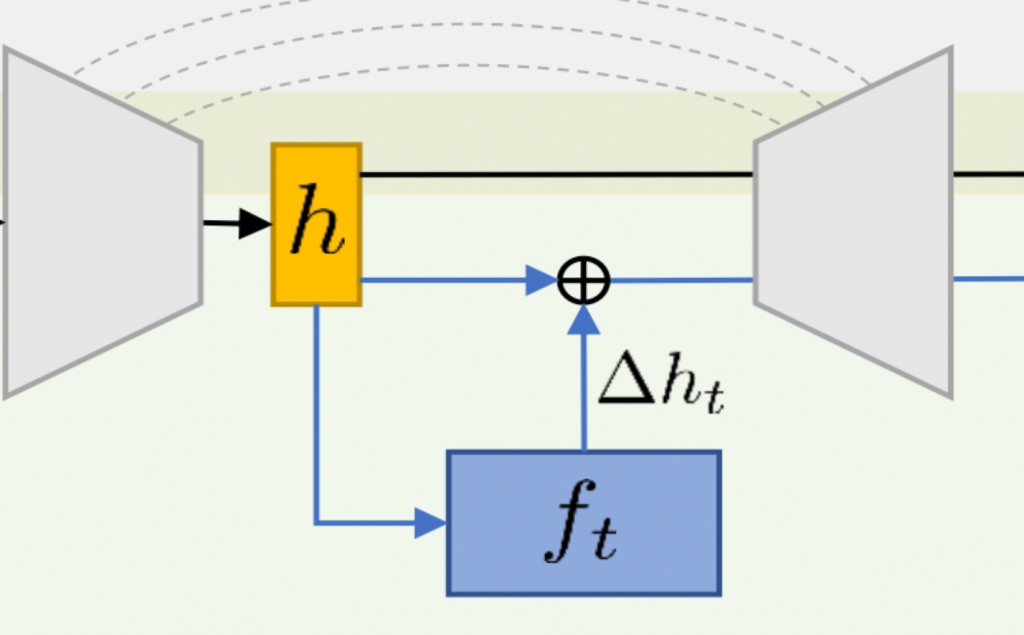
This approach is motivated by [2], where the authors show that the latent space of diffusion models can be manipulated by training an implicit function to find the edit in the bottleneck layer of U-Net (delta_h). We want to build on this by training the implicit function to be adversarial.
LLM-aided attribute Discovery
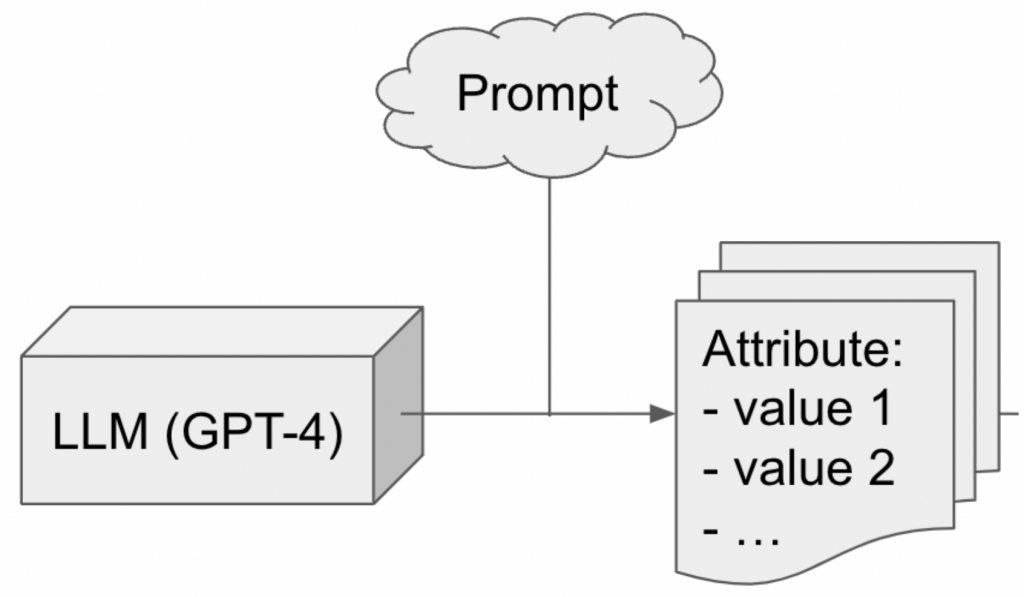
While we hope to achieve purely unsupervised discovery of adversarial attributes, we recognize the difficulty in this goal and hope to hedge our bets by pursuing a parallel approach using LLMs for attribute discovery. In summary, we will prompt GPT-4 to output relevant attributes for some given domain, and feed these candidates to adversarial analysis downstream.
Data Augmentation
In this research direction, we are trying to achieve the following goals:
- Can we use targeted domain data generation to bridge the gap between the train and test image data domains?
- Better yet, can we address long-tail problems by leveraging synthetic images to augment scarce data?
To accomplish this, we are leveraging state-of-the-art text-to-image models, which have been trained on millions of images and can serve as a strong foundation for bridging the domain gap in a few-shot manner.
However, off-the-shelf models that have not been fine-tuned on the target dataset may generate images that are not readily usable, as seen in the example of chest X-ray images below:
Prompt: “A photo of a lung x-ray”
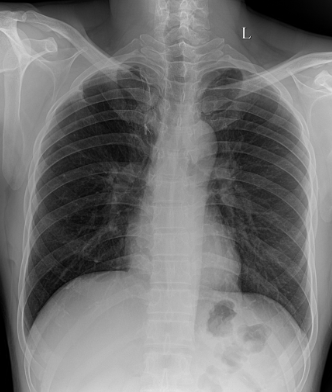
Therefore, we are actively exploring multiple approaches based on two recent related works that achieve personalization in a few-shot manner (Gal et al. 2022, Ruiz et al. 2022).
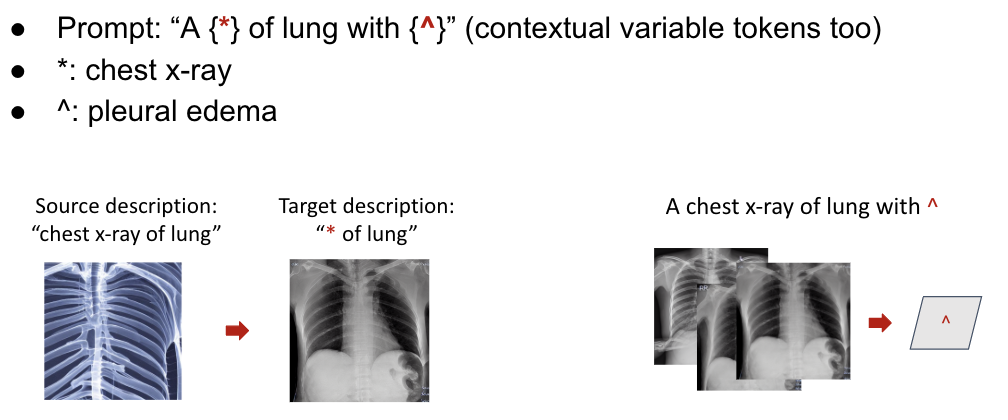
- Method 1: Hierarchical textual inversion
This involves expanding textual inversion to employ multiple tokens in a hierarchical fashion.
This two-step methodology can be adopted whereby a representation capable of bridging the gap in chest X-ray image generation is initially acquired as the primary task, followed by a secondary and more granular task of developing a separate representation that concentrates solely on generating specific diseases in the chest X-rays.
- Method 2: Prompt-assisted generation
This involves constructing prompts that explicitly furnish the specifics of the target domain via text. For instance, in the case of chest X-rays, suppose we wish to produce images with pleural effusion. Rather than generating images using a straightforward prompt such as “A lung x-ray with pleural effusion”, we can incorporate more explicit visual characteristics such as “A lung x-ray with perihilar ground-glass opacities, peribronchial thickening, and interstitial and alveolar opacities in the mid to lower…”, where these characteristics can be automatically extracted from models like ChatGPT.