Resources
Unsupervised Model Diagnosis (UMO)
- We propose an unsupervised framework for model diagnosis, named UMO, that bypasses the tedious and expensive requirement of human annotation and user inputs.
- UMO utilizes the parametric knowledge from foundation models to ensure accurate analysis of model vulnerabilities. The framework does not require a manually-defined list of attributes to generate counterfactual examples.

Method Overview

- Counterfactual Optimization: directly optimizing the latent edit directions that can mislead prediction of target model
- Counterfactual Analysis: generate pairs of (original, counterfactual) to discover semantic attributes
Experiments
Experiment: Generate counterfactuals for target models of known biases
This section evaluates UMO through experiments with classifiers trained on imbalanced data.
Our experiments consistently highlight that the diagnosis from UMO can reliably pinpoint these intentional biases, confirming the reliability of our unsupervised detection.


Experiment: Cross-Method Diagnosis Consistency
We performed three distinct experiments: two using our framework with different generative model backbones (Diffusion model and StyleGAN), and the other using the ZOOM approach. We should expect to discover the same counterfactual attributes for a given target model, across all three experiments.

Experiment: Generalization to Other vision Tasks
We expanded our experiments to encompass image segmentation and keypoint detection tasks. As shown, we are able to successfully attack the target model using our method.

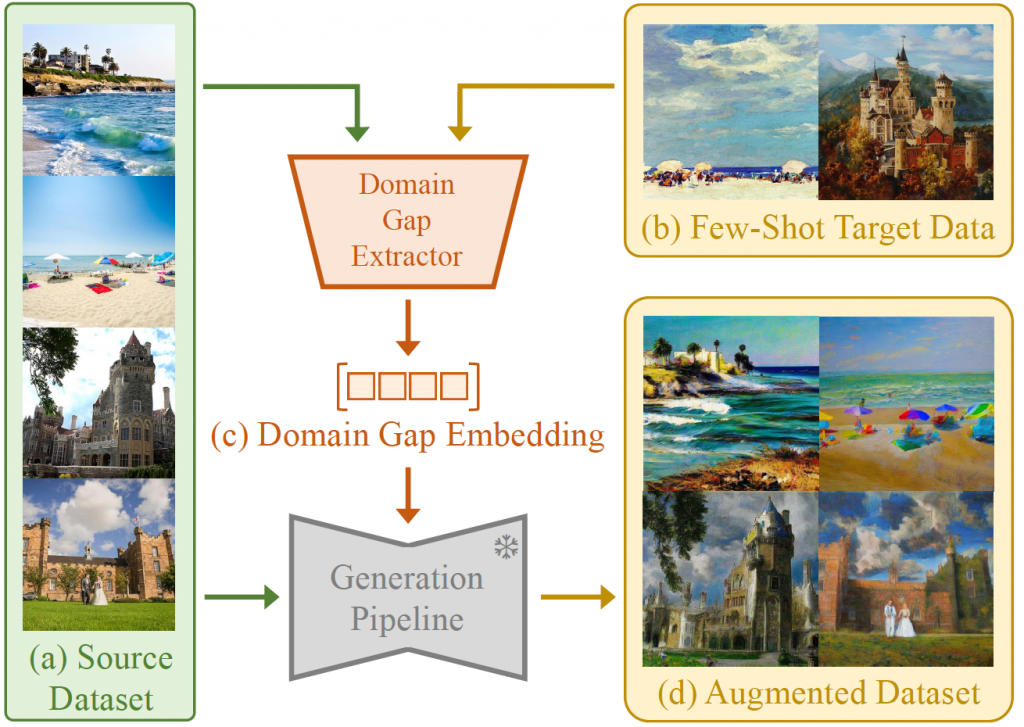
Domain Gap Embeddings (DoGE)
- We introduce Domain Gap Embeddings (DoGE), a plug-and-play semantic data augmentation framework in a cross-distribution few-shot setting.
- Our method extracts disparities between source and desired data distributions in a latent form, and subsequently steers a generative process to supplement the training set with endless diverse synthetic samples.
Method overview
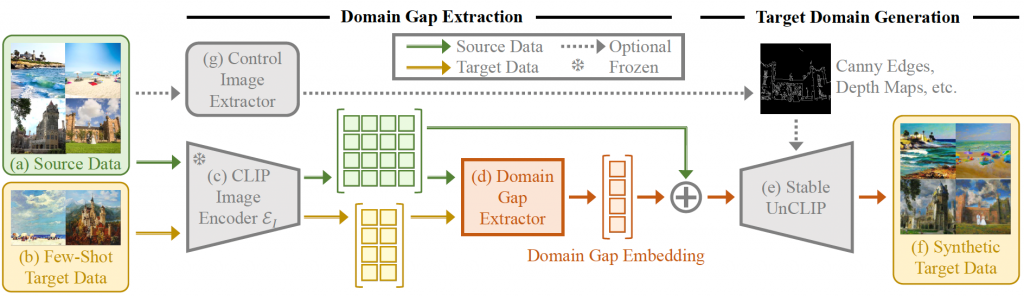
- Encode a few data samples from source/target into the CLIP embedding space
- Extract the Domain Gap Embedding (∆)
- Augment source data embeddings with ∆
- Generate target images from the augmented embeddings with Stable UnCLIP
experiments
This section evaluates DoGE through experiments with classifiers trained on a combination of real and synthetic data.
Our evaluations, conducted on a subpopulation shift and three domain adaptation scenarios under a few-shot paradigm, reveal that our versatile method improves performance across tasks without needing hands-on intervention or intricate fine-tuning.
Experiment: mitigating Subpopulation shift

Examples of synthetic CelebA data generated from (a) Source into (b) Target distribution. Under subpopulation shift, we generated data from the majority subpopulation (a) into the under-represented distribution (b). (c) shows the synthetic data generated from our pipeline. The results demonstrate our capability to apply semantic augmentation in accordance with gaps between two distributions.
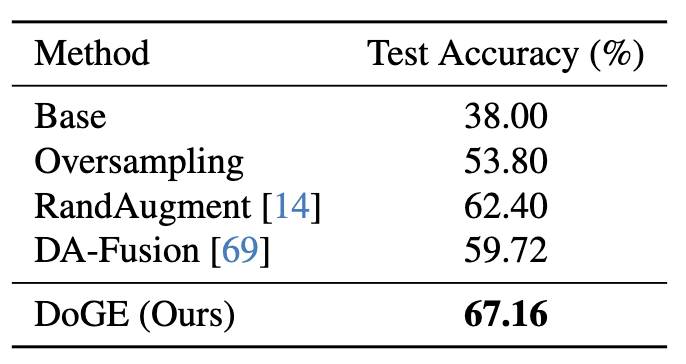
Test Accuracy on our constructed CelebA imbalanced classification problem. We evaluated our method against four baselines. This table shows that synthetic data from DoGE has a significant advantage over other methods.
Experiment on unsupervised domain adaptation problem (classification)

Examples of synthetic DomainNet data, generated from source data into four different target domains. Each generation (bottom) was augmented from the source image (top) using our pipeline with ControlNet. The results demonstrate our capability to augment data in accordance with gaps between distributions.

Examples of synthetic FMoW data, generated from Source (2002-12) into Target (2016-17) distributions in 3 regions using our method with ControlNet. The results illustrate our capacity to generate images across temporal discrepancies.
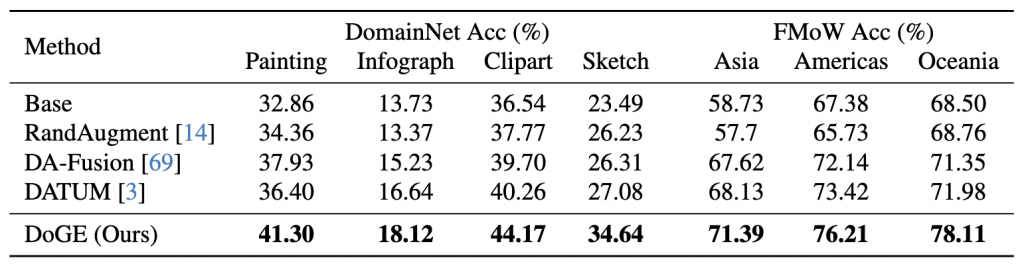
Test accuracy in unsupervised domain adaptation classification problems. We evaluated against four baselines on the left column. For DomainNet, the task is to adopt a model with a Real domain training dataset to Painting, Inforgraph, Clipart, and Sketch domains. For FMoW, for each region (Asia, Americas, Oceania), we adopted a model with old satellite images (2002-15) to perform well on new satellite data (2016-18). The table shows that our methods achieved the highest test accuracy in every category.
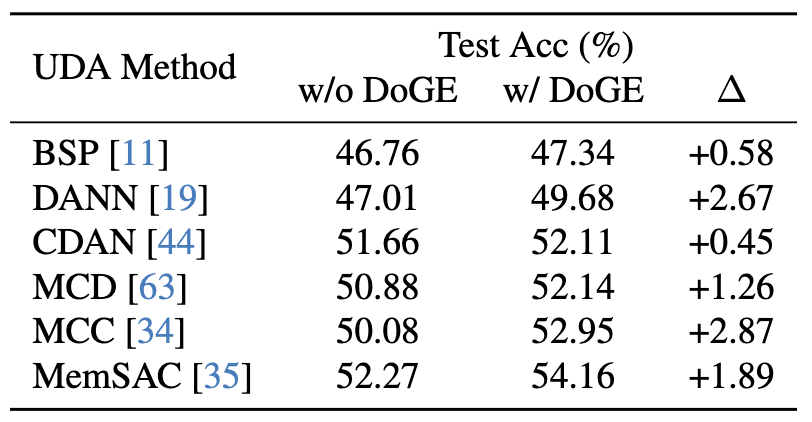
Test Accuracy of UDA methods on the DomainNet (Real → Painting) problem. We evaluated existing UDA methods with and without DoGE. The table shows that our approach is compatible with and complementary to UDA methods.
Experiment on Unsupervised domain adaptation problem (segmentation)

Examples of synthetic self-driving data generated from (a) GTA5 source images into (b) Cityscapes target domain. (c) shows the synthetic data generated from our pipeline without any improvement tricks. We also demonstrated the generation with scene structure preserved by ControlNet (conditioned on canny edges and source segmentation ground truth) in (d). The synthetic data are then used in unsupervised domain adaptation methods to adapt models across domains.

GTA5 → Cityscapes cross-domain segmentation. We used DAFormer as our UDA baseline. DATUM and DoGE are target data generators applied on top of DAFormer. Our performance is at par with DATUM while exempt from any training.