
Baseline
We use the approach mentioned in DynamicNeRF [1] as our baseline. The overall architecture of DynamicNeRF consists of two NeRF models, one for the static scene and the other for the dynamic object. Both of the NeRF models take the following inputs:
- images from different viewpoints and timesteps of the scene containing dynamic objects
- ground truth mask of dynamic objects in the scene
The static model implements vanilla NeRF, querying color and density given the position and viewing direction. The dynamic model takes not only the position and viewpoint, but also the timestep to output the color and density as well as the blending factor at each point and timestep. The blending factor ranges between 0 to 1, denoting the importance of the prediction of the dynamic model at each point. The image is finally rendered using volumetric rendering.
An overview of the DynamicNeRFs rendering pipeline is shown in the figure below.
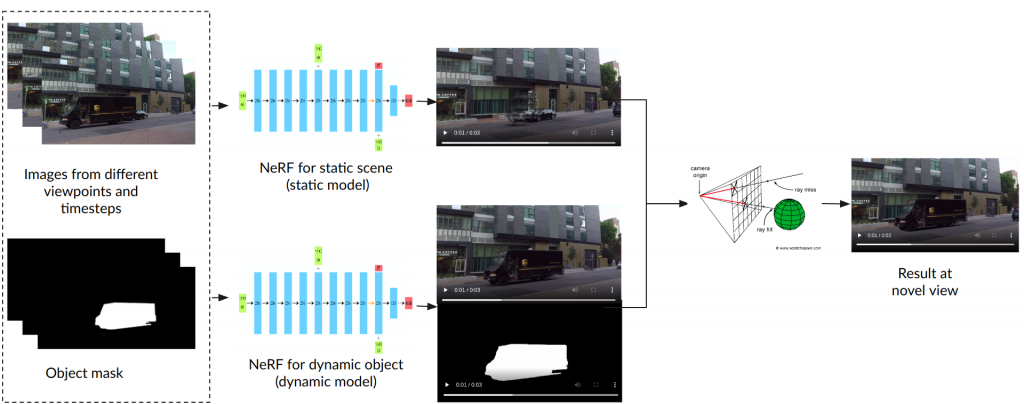
Some baseline results are shown in the videos below.
Our Contribution
- Flexible multi-camera composition framework to add an arbitrary number of dynamic objects into a static 3D scene
- Novel-view augmentation (NOVA) strategy for learning better per-point blending factors
- Corresponding novel-view losses for high rendered image fidelity
Multi-camera Composition
Our framework uses separate cameras to learn different parts of the scene. To specify what these cameras are responsible for, a segmentation mask is provided for each camera. Given the images at different time steps and these segmentation masks, each camera is assigned a corresponding NeRF that is static or dynamic based on the dynamicity of the scene parts it models (see figure below).
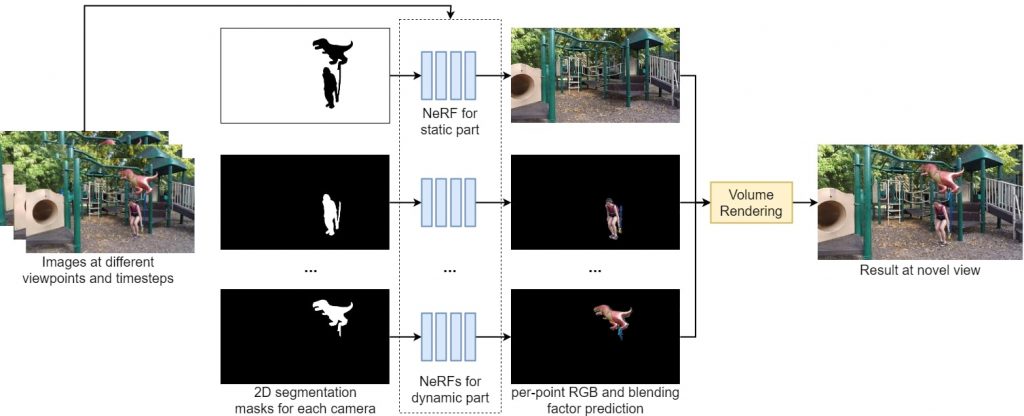
The static NeRF is time-invariant and can use images across all time steps to learn the scene, predicting the per-point color and density given the point’s position and viewing direction. The dynamic NeRF is time-varying and uses a single image per time-step to learn the scene at a particular timestep, predicting the per-point color, density, scene flow, and blending factor given the point’s position, viewing direction and time.
Novel-view augmentation (NOVA)
During training, we shift the camera responsible for the dynamic object to a novel view. Given the camera’s relative transformation, we calculate the ground truth segmentation mask at the novel view using stereo geometry. Points are sampled along the rays of the camera at the novel viewpoint C2 and passed through the corresponding NeRF.
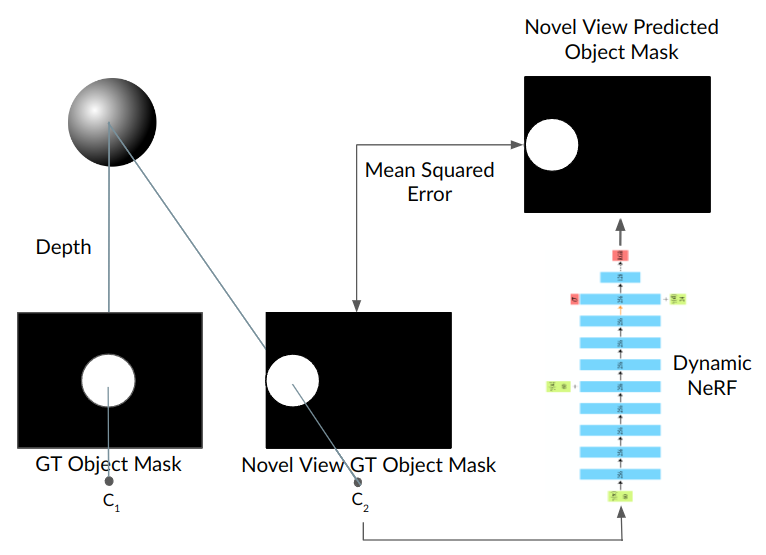
Novel-view losses
We introduce a few losses to ensure high image fidelity when placing objects at novel points in the scene.
- Novel-View Mask loss: MSE between GT and predicted masks
- Full Novel-View RGB loss: MSE between GT and predicted RGB image
- Blending loss: sum of blending factors across cameras should be equal to one
- Alpha loss: predicted alpha outside mask should be zero
References
- Gao, Chen, Ayush Saraf, Johannes Kopf, and Jia-Bin Huang. “Dynamic view synthesis from dynamic monocular video.” In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 5712-5721. 2021.