
Dataset
We use Nvidia’s Dynamic Scene Dataset [1] for our experiments. It contains multiple scenes containing objects moving in the foreground, each consisting of 12 images captured from a monocular camera.

The images are taken at different times, as can be seen from the truck’s position shown by the red circles in the above figure. They are also taken from slightly different viewpoints, as shown in the green circles in the figure below.

General Approach
Most of the work done by the research community has the flow of information shown in the figure below.
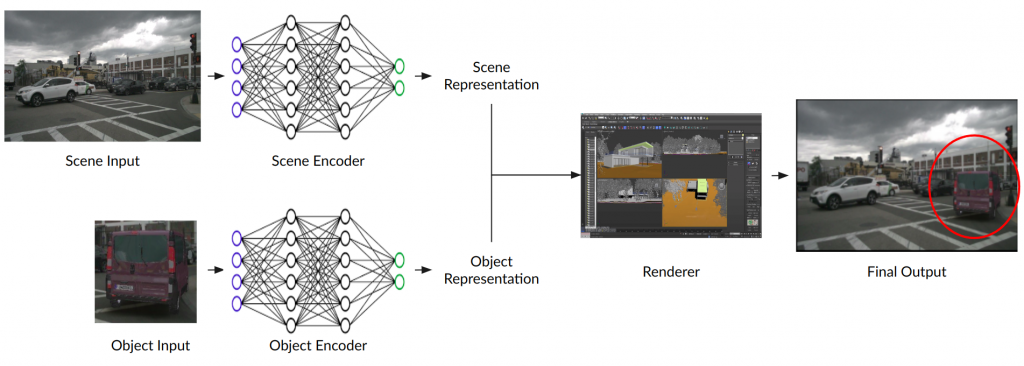
An image of the scene is provided as input to the scene encoder to build a scene representation. Similarly, an image of the object to be inserted into the scene is passed through an object encoder to build an object representation. The two representations are merged using a renderer to finally render thhe object in the given scene.
References
- Jae Shin Yoon, Kihwan Kim, Orazio Gallo, Hyun Soo Park, and Jan Kautz. Novel view synthesis of dynamic scenes with globally coherent depths from a monocular camera. In CVPR, 2020.