
Experiments
Simple Composition of Two Scenes
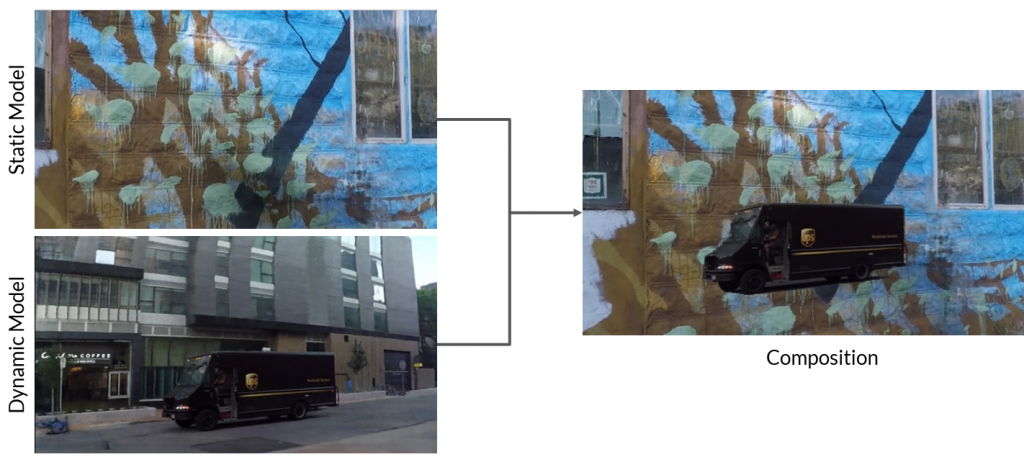
The first goal of our project is to compose an object from one scene into another. To achieve this, we load a static model trained on one scene and a dynamic model trained on a different scene, then run Dynamic NeRF inference to get the composed image as shown in the figure below.
Transformation could also be applied to change the position of dynamic object:
Multiple Dynamic Objects
We also explore training Dynamic NeRF on custom data that contains multiple dynamic objects moving incoherently, like the following traffic scene. After training and rendering, we see that Dynamic NeRF has many parts of the background moving, even though we explicitly pass it the object masks with cars as the dynamic objects.
Results
Quantitative
We evaluate the image fidelity quantitatively by assessing the PSNR between the synthesized image and the corresponding ground truth image at a fixed viewpoint but changing time. We compare with existing works in the Table below. Our framework performs comparably to other methods without the need for additional modalities of ground truth data like optical flow. In particular, we achieve the best PSNR among all methods for scenes with fewer deformable movements (Balloon1 and Umbrella). The PSNR is lower for scenes with high deformable movement (Jumping and Skating) since we do not use ground truth optical flow supervision like prior works do. Using optical flow ground-truth supervision should increase the PSNR for these scenes and remains future work.

Qualitative
We compare our novel-view renderings with Gao et. al. in the figure below. As can be seen from their predicted object masks, there are blending artifacts at the edges of the Umbrella, Balloon1, and Jumping scenes at novel viewpoints. Our framework reduces these blending artifacts, as visible clearly from our predicted object masks and generated final images. In other scenes with single objects, our framework performs comparably to prior works.

Ablation Study
We study the impact of each of our modules on the quality of the final image.
Multiple Cameras. The improvement in blending factor prediction is significant when composing dynamic objects into a scene using NeRFs. In the figure below, we show the final images and predicted masks when inserting a second object into the left corner of the scene. Gao et. al. predict the second object is present at multiple places in the scene (ghost predictions) and has blurry boundaries. Our multiple-camera module removes these artifacts significantly and generates crisp object mask boundaries, resulting in reliable neural composition, as can be seen by the final predicted RGB images.

Novel-view augmentation. We provide ablation of the losses related to novel-view augmentation training, i.e., the novel-view mask and RGB losses in the figure below. Using only the novel-view mask loss removes the blending artifacts significantly, evident by the removal of the artifact on the right side in the Umbrella scene and on the shirt in the Balloon1 scene. However, the color reproduction is poor, with some background bleeding through. Adding the novel-view RGB losses ensures the inserted objects have proper color reconstruction and also slightly helps in reducing the blending artifacts.

Alpha Loss. We highlight the impact of alpha loss in the figure below. As seen by the final RGB image of the NeRF corresponding to the camera responsible for the umbrella, there is color outside the mask of the umbrella, which is because the NeRF predicts non-zero alphas at these points. Using alpha loss leads to a black color output outside the mask since the alpha at each point is close to zero, leading to a final color corresponding to zero, which is black.

Scalability. The multiple-camera module provides our framework the ability to photo-realistically insert multiple objects independently at novel points of the scene. It only requires a list of the cameras responsible for the parts of the scene that need to be manipulated and the change in pose relative to their original pose configuration.
