Generative model zoo. We evaluate a collection of 133 generative models trained using different techniques including GANs [Gal et al. 2022; Karras et al. 2018, 2021, 2020b; Kumari et al. 2022; lucid layers 2022; Mokady et al. 2022; Pinkney 2020a,b; Sauer et al. 2022; Wang et al. 2021], diffusion models [Dhariwal and Nichol 2021; Ho et al . 2020; Song et al . 2021b], MLP-based generative model CIPS [Anokhin et al . 2021], and the autoregressive model VQGAN [Esser et al. 2021]. We also assign tags to each model based on the type of generated images, with 23 tags in total. Example tags include “face”, “animals”, and “indoor”, where all the face generative models will have the “face” tag.
Evaluation metrics. Following the image retrieval literature, we evaluate model retrieval using two different metrics:
(1) Top-k accuracy, i.e., predicting the ground truth generative model of each query in top k.
(2) Mean Average Precision@k (mAP@k). All the models with tags common to the query model are included as relevant models regarding the mAP calculation. The mAP@k metric considers only the top-k predictions because, for retrieval use cases, top-ranked models matter more. This metric is computed as below:
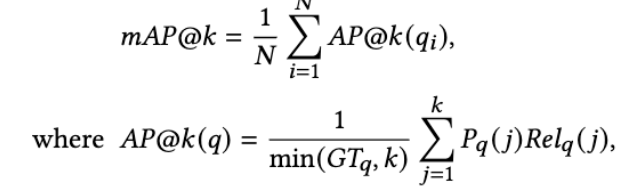
where 𝑃𝑞 ( 𝑗) is the precision of top-j predictions given query 𝑞 and 𝑅𝑒𝑙𝑞 ( 𝑗) is a binary indicator for 𝑗𝑡ℎ prediction being relevant. 𝐺𝑇𝑞 is the number of relevant models corresponding to the query. The above metric weighs all the models similar to the query ground truth equally during evaluation. For example, given a text query face, all face generative models are treated as relevant and should be retrieved as top predictions
Text-based model retrieval. To evaluate text retrieval, we manually assign a ground-truth text description to each model in the collection. We use CLIP feature space [Radford et al. 2021] since CLIP has both text and image encoders. In Table 1, we show the retrieval
performance of the different methods. We achieve top-10 accuracy of 92% and 0.71 score of mAP@10 by applying the 1st Moment-based method. To ensure that the retrieval is robust to variation in text queries, we also evaluate the method with augmented queries that prepend phrases like “an image of” and “a photo of” to each text query. As shown in Table 1, the retrieval performance decreases only marginally. Both quantitative numbers and visual inspection of results show that our method retrieves relevant generative models
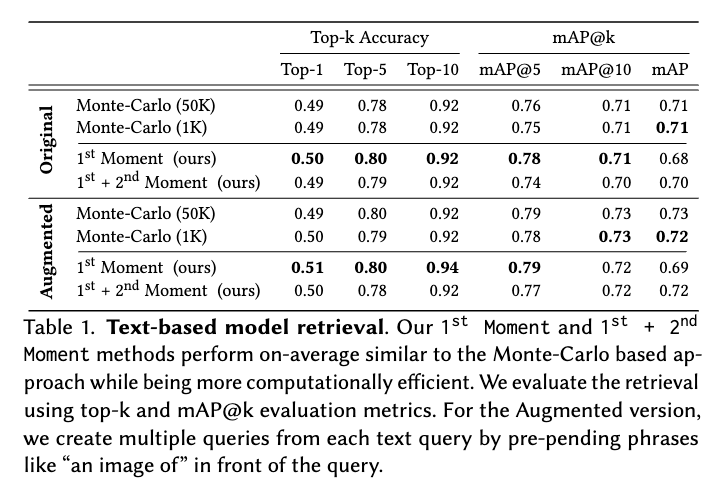
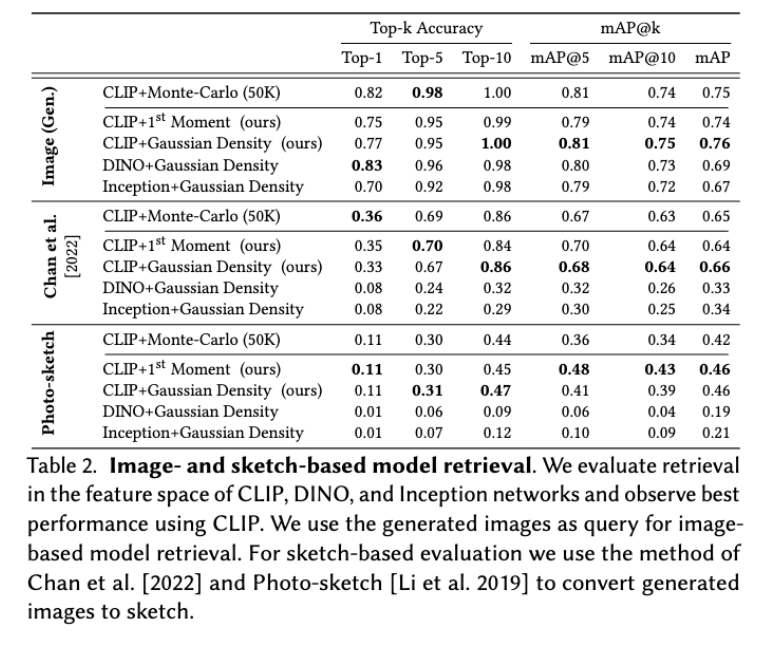
Image- and sketch-based model retrieval. For image-based model retrieval, we test three different image features –Inception [Szegedy et al . 2016], CLIP [Radford et al . 2021], and DINO [Caron et al. 2021]. To evaluate, we automatically create image queries using images generated by each model. We generate 50 image queries for each model and use the corresponding model as the ground truth for the queries. In total, we have 133 × 50 image queries. To obtain sketch queries, we use the method of Chan et al. [2022] and PhotoSketch [Li et al. 2019] to convert images into sketches. We also apply the 1st Moment method to image-based model retrieval. Specifically, given an image query, we extract the feature using CLIP’s image encoder. We then compute the cosine distance between the query feature and the first moment.
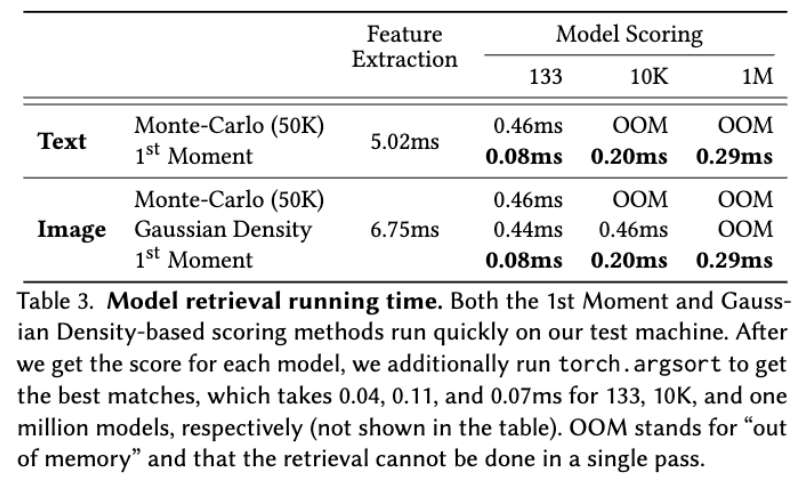
Runtime and Memory Analysis
The computational and memory efficiency of the retrieval algorithm is crucial to supporting many concurrent users searching over large-scale model collections. Therefore. we profile our method on 133 generative models as well as a much greater number of simulated models. To create simulated models, we sample the 1st Moment model statistics and Monte-Carlo samples from a 512-dimensional normal distribution that corresponds to points in the CLIP feature space, and the second moment statistics are generated as a unit covariance matrix with a small, uniform, symmetric noise added. The data are stored in the GPU’s VRAM. We run the following tests on a machine equipped with an AMD Threadripper 3960X and NVIDIA RTX A5000 running Pytorch 1.11.0 and report them in Table 3.
Qualitative Results



Qualitative results of model retrieval. Top row (image query): The still-life painting retrieves models related to art and places the AFHQ Wild model at the bottom ranking. Middle row (sketch query) Both horse and church sketches retrieve relevant models at the top ranking. Bottom row(text query): The query “human wearing a pair of glasses” successfully retrieves a GANSketch model finetuned for human faces with glasses. Similarly, with the query “a bird that talks”, we find a Self-Distilled GAN [Mokady et al. 2022] trained on Internet parrots images
Multimodal query:

Multi-modal user query: We show a qualitative example of how multi-modal queries can help refine the model search. With only the image of “Nicolas Cage” we retrieve only face models. But with the multi-model query of image and text as “dog”, we can retrieve the StyleGAN-NADA model of “Nicolas Cage dogs”.