1. GAN Inversion
For image inversion, we use 15 StyleGAN2-based models at 256×256 resolution, for a fair comparison regarding image resolution and network architectures. We first evaluate real image inversion on the validation set images from LSUN Church and CelebA-HQ datasets. We use the optimization-based inversion technique in 𝑊 + latent space with LPIPS and pixel level mean square loss between the target and generated image. Given an image query, we run inversion on models ranked at 1, 10, and 15 by our Gaussian Density retrieval method.
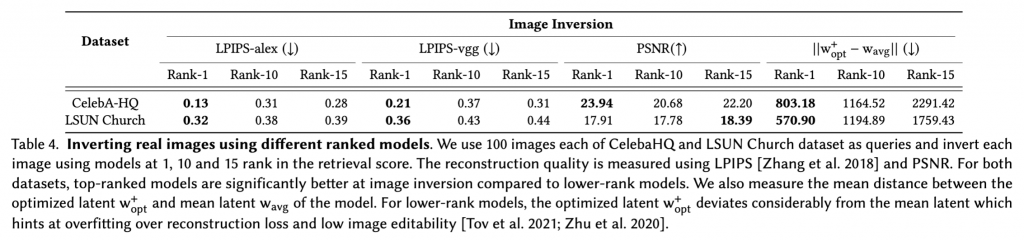
We evaluate the reconstruction quality between 100 inverted and target images of both categories using standard metrics like LPIPS and PSNR. We also calculate the mean distance between optimized w+ opt and the mean latent w of the model which shows the extent of overfitting to the reconstruction loss by the model. The results are shown in Table 4. We observe that top retrieved models that are similar to the image query result in better image inversion on average across all metrics. Moreover, for lower-ranked models, the distance ||w+ opt − w_avg || is significantly higher compared to the top-rank models, which has been shown to correlate negatively with image editability. Figure 8 shows some qualitative samples of image inversion using the different ranked models. Lower-ranked models yield inversions with substantially poorer quality.

2. Image editing and interpolation
We now show that images inverted with top-ranked models can be further edited using existing GAN-based image editing techniques such as GANSpace. Figure 9 shows examples of editing on Ukiyo-e images to change the frowning face to a smiling face. For the flower category, we show example edits that change the petal colors. We can also perform latent space interpolation between inverted images of the same category and create visually compelling samples as shown in Figure 11. A rank-1 model results in the smoother interpolation of one image into another in contrast to inversion and interpolation using a random model.


3. Few-Shot Transfer Learning
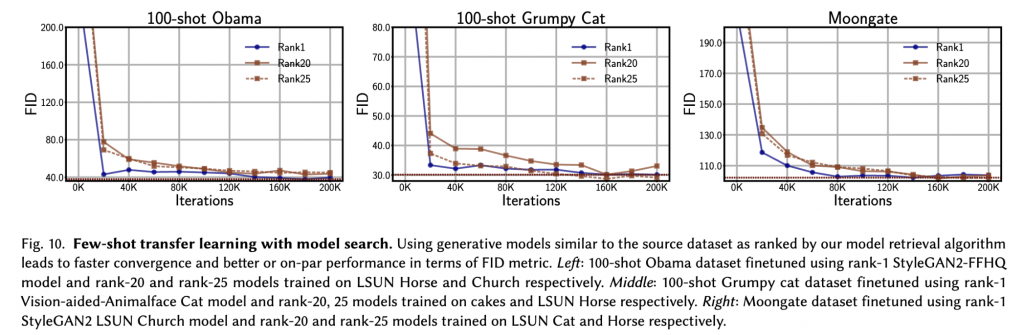
For few-shot transfer learning, we restrict our experiments to 256×256 resolution StyleGAN2 models due to limited computing resources (27 models). We begin with a small dataset of 100-136 images. Then, we rank the 27 models by the average retrieval score over all images. We select models at ranks 1, 20, and 25 as source models for transfer
learning. For finetuning the generator on the new dataset, we use vision-aided GANs, one of the leading methods in few-shot GAN training.
Datasets and evaluation metric: We use three standard few-shot datasets: Obama (100 images), Grumpy Cat (100 images), and Moongate. (136 images). We use the Fréchet Inception Distance (FID) metric for evaluation.
Results: Figure 10 shows the results of transfer learning using different source models with varying retrieval rankings. We observe on average faster convergence when fine-tuning from rank-1 models compared to other lower-ranked models. This shows empirically that training from similar models results in faster convergence and thus requires less compute.