
The scene is encoded as a bunch of fronto-parallel RGBA planes at discrete depths. Rendering a new image is as simple as compositing the planes back-to-front. Given some defocused images like the ones below:

We attempt to learn the below RGBA planes which together represent a multi-plane representation:
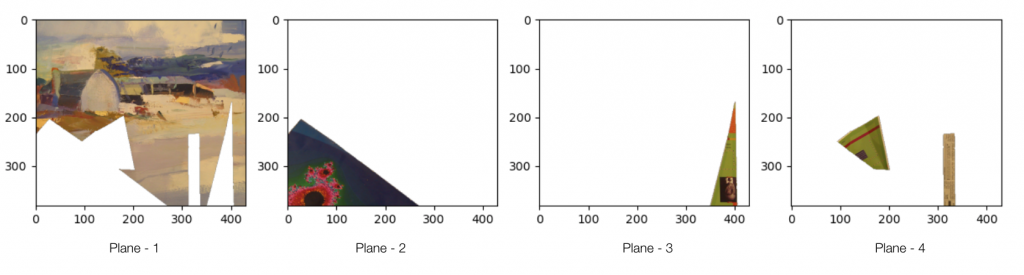
Then we can render the image for novel camera settings:
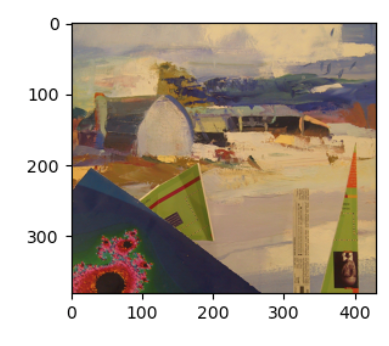
Below we go through the experiments and analyses conducted for the MPI representation.
Experiments
Dataset
The generated dataset assumes the world consists of two planes – foreground and background each with a predefined depth. A set of focus and aperture values are swept along the two planes to generate the Focus-Aperture stack.



We implemented a custom renderer in PyTorch that can mimic the thin-lens-based camera model to generate images for different focus and aperture values.
Experiments
In all the experiments below, we learn two planes (WxHx4) at fixed distances using images from the training stack. Ideally, we expect the learned MPI to be similar to the foreground and background images as shown above.
Experiment 1: Single Image overfitting



Observation: Given a single image, the learned MPI and rendered image are shown above. We can see that the rendered image and ground truth image are pretty close. It is hard to learn depth disambiguation from a single image and hence there exist multiple MPI solutions that can give back the same image. This is why the rendered image looks clean while the MPI planes themselves look extremely noisy.
Experiment 2: FA Stack training
Training on 9 Focus stacks and test on 1 Focus stack



Observations: We can see that learned planes in MPI are pretty close to the true foreground and background planes. Since the planes are correct, the generated image for different focus and aperture looks pretty close to the ground truth.
References
- Tucker, R., & Snavely, N. (2020). Single-view view synthesis with multiplane images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 551-560).
- Li, J., Feng, Z., She, Q., Ding, H., Wang, C., & Lee, G. H. (2021). Mine: Towards continuous depth mpi with nerf for novel view synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 12578-12588)