
This section further explains the finer details of the two representations we chose to work with – Multi-Plane Images (MPI) and Neural Radiance Fields (NeRF). Let’s take a quick look at the high-level design of our approach.
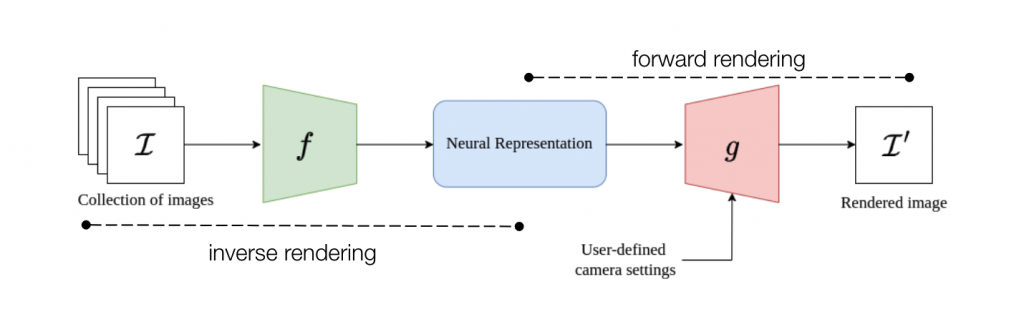
As we can see, a suitable neural scene representation is essential to perform the inverse and forward rendering steps efficiently and accurately for our task. We briefly cover two image formation concepts relevant to understand our approaches.
Preliminaries
Focus
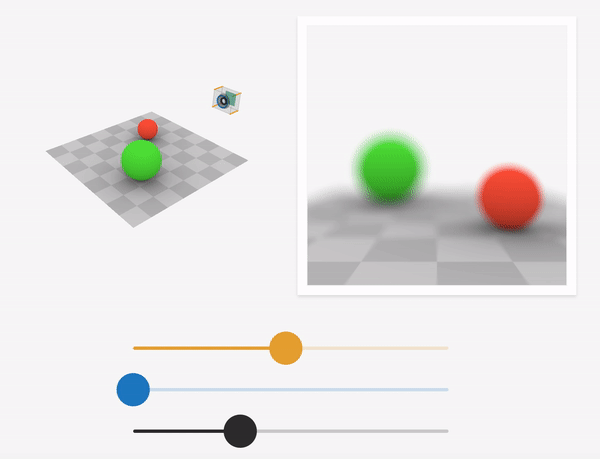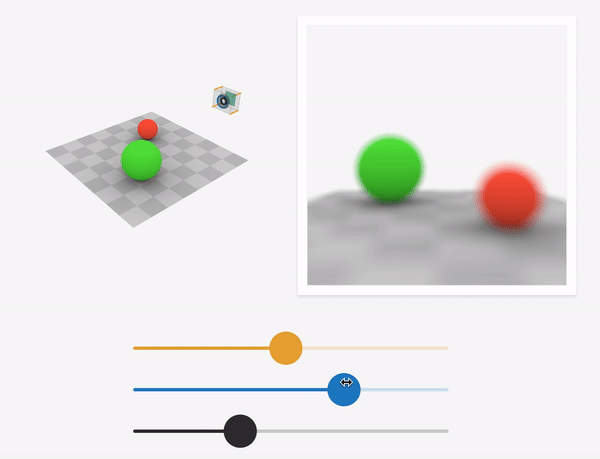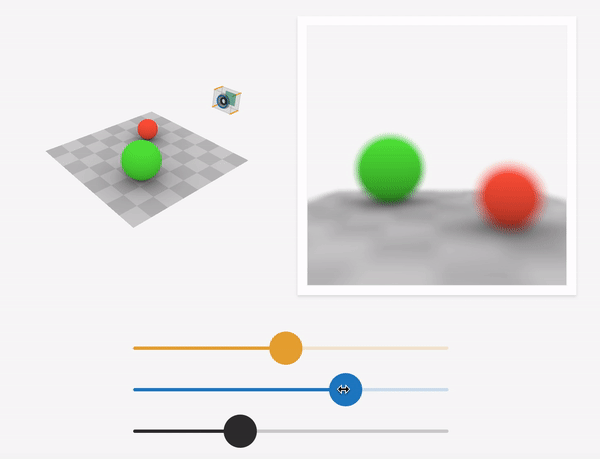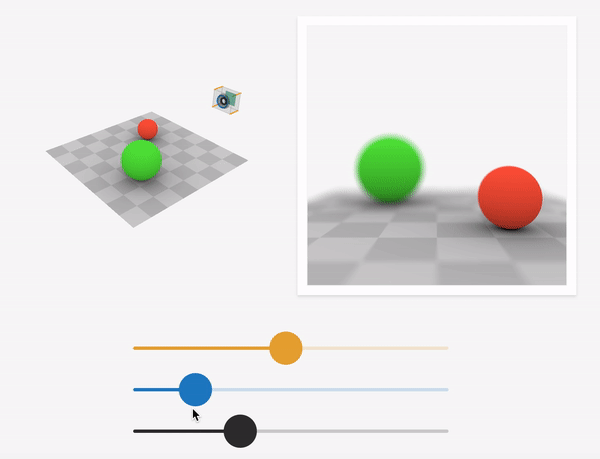
Source: https://ciechanow.ski/cameras-and-lenses/
For a particular sensor distance and focal length of the lens, objects that lie on a specific plane called the focus plane to appear sharp in the final image. This is governed by the thin-lens equation. As we sweep the focus plane away from the camera, objects further away appear in focus while nearby objects get blurred.
Depth-of-Field
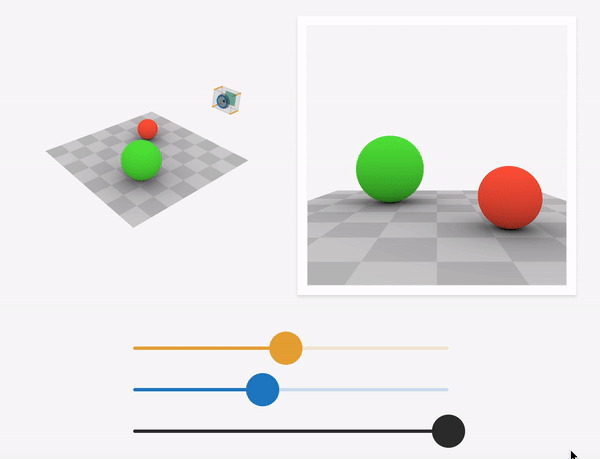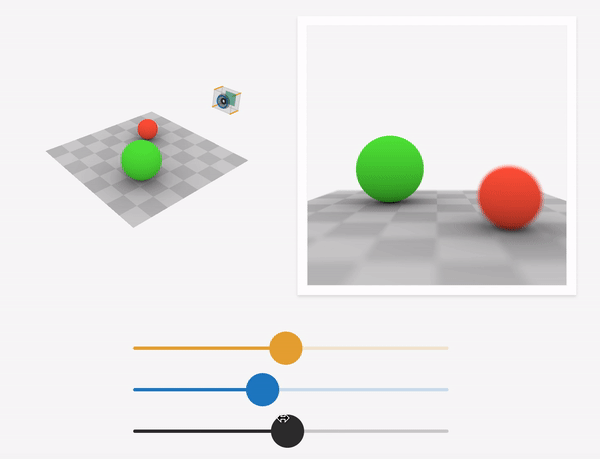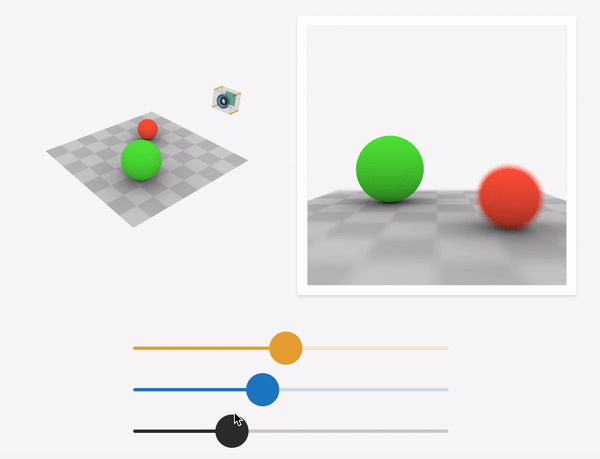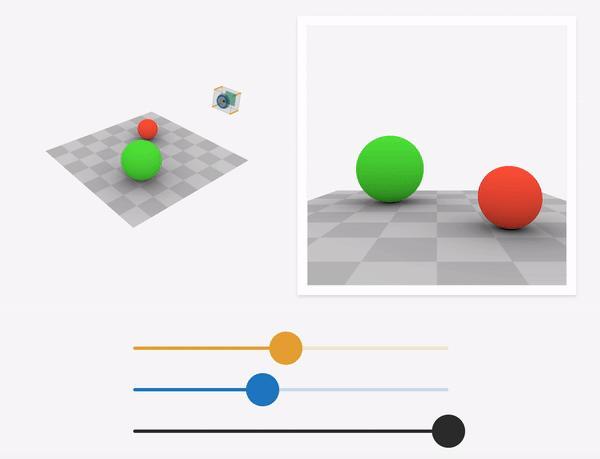
Source: https://ciechanow.ski/cameras-and-lenses/
Depth-of-field is the range of scene depths that appear sharp in the image. For a large aperture (small f-stop number), the depth-of-field is shallow, and hence a small range of depths is in focus. As we approach a pinhole camera (smaller aperture, larger f-stop number), the depth-of-field increases, and a larger range of scene depths are in focus. At the limit, the aperture becomes that of the pinhole, and the image generated is called an all-in-focus image(AIF).
Our choice for using MPI and NeRF was based on the fact that both representations model scene depth explicitly (implicitly for NeRF). While we initially experimented with the MPI approach, we encountered a few critical limitations regarding rendering time and quality inherent to MPI ray sample-based rendering. Hence, we shifted our focus (pun intended) to a radiance field representation (NeRF) that solved many of the problems we faced with MPIs.
We go into the approach details and experiments for each representation below: