Setup
Dataset. We experiment on the Common Objects in 3D (CO3Dv2) dataset that contains multi-view images along with camera pose annotations.
Baselines. We benchmark GBT against three state-of-the-art methods – pixelNeRF (projection-guided), NerFormer (projection-guided, attention-based), ViewFormer (geometry-free). Additionally, we compare against GBT-nb (no bias) – a variant of our approach, where we replace the geometry-biased transformer layers with regular transformer layers.
Metrics. To evaluate reconstruction quality, we measure the peak signal-to-noise ratio (PSNR) and perceptual similarity metric (LPIPS).
Results
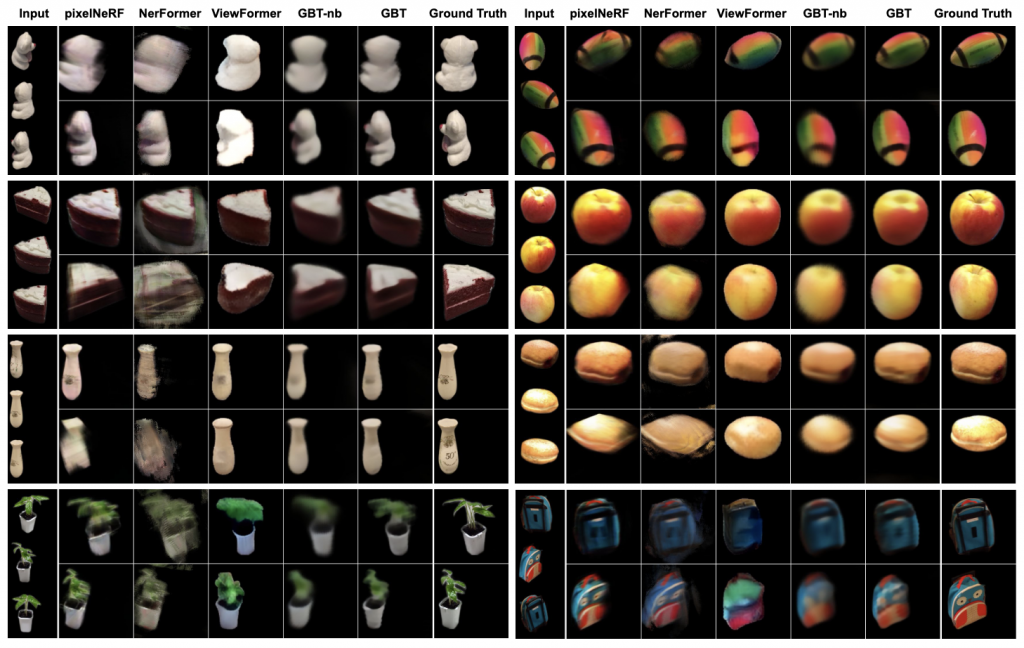

Novel view synthesis for unseen objects. Table 1 demonstrates the efficacy of our method in synthesizing novel views for previously unseen objects. GBT consistently outperforms other methods in all categories in terms of PSNR. With the exception of a few categories, we also achieve superior LPIPS compared to other baselines.
We attribute ViewFormer’s higher perceptual quality to their use of a 2D-only prediction model, which comes at the cost of multi-view consistent results. Also, in cases where the query view is not visible in any of the input views, pixelNeRF and NerFormer – which rely solely on projection-based features from input images – suffer from poor results, while our method is capable of hallucinating these unseen regions. We also show qualitative results in Fig 1.
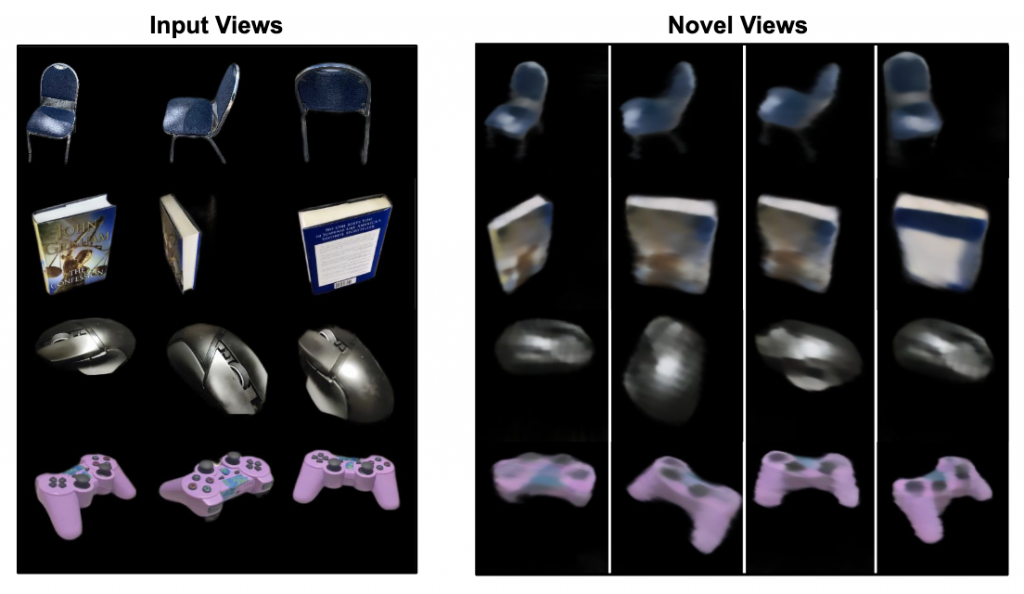
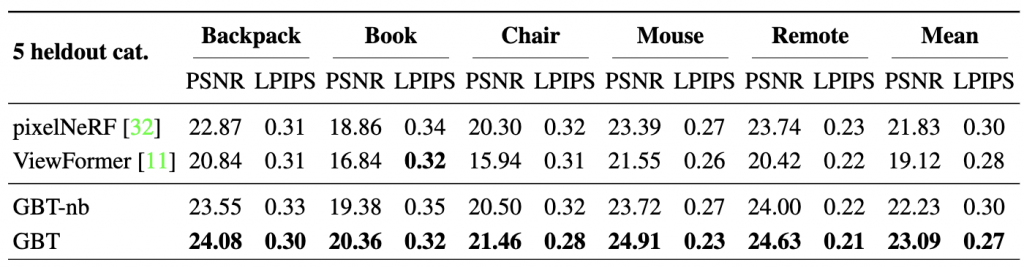
Generalization to unseen categories. To investigate whether our model learns generic 3D priors and can infer global context from given multi-view images, we test its ability to generalize to previously unseen categories. In Table 2 we benchmark our method by evaluating over 5 held out categories. We empirically find that GBT demonstrates better generalizability compared to baselines, and also observe this in the qualitative predictions (Fig 2).
Effect of the Geometric Bias

In Fig. 3 we visualize attention heatmaps for a particular query ray highlighted in green. In absence of geometric bias (GBT-nb), we observe a diffused attention map over the relevant context, which yields blurrier results. Notably, the initial layers tend to store global information in the form of latent features towards the edge patches of the image (which is empty in most of the training images). A similar effect was observed in Sajjadi et al. as well. The deeper transformer decoder layers aggregate the attention towards the relevant context which enables the model to extract the appearance information from the input views. On adding geometric bias (GBT), we observe more concentrated attention toward the geometrically valid regions. In particular, the first decoder layer now focuses more on the corresponding Epipolar lines in the input images. Subsequently, the later layers concentrate the attention further. We hypothesize that this sharper attention leads to more precise details.
Effect of Viewpoint distance on prediction accuracy
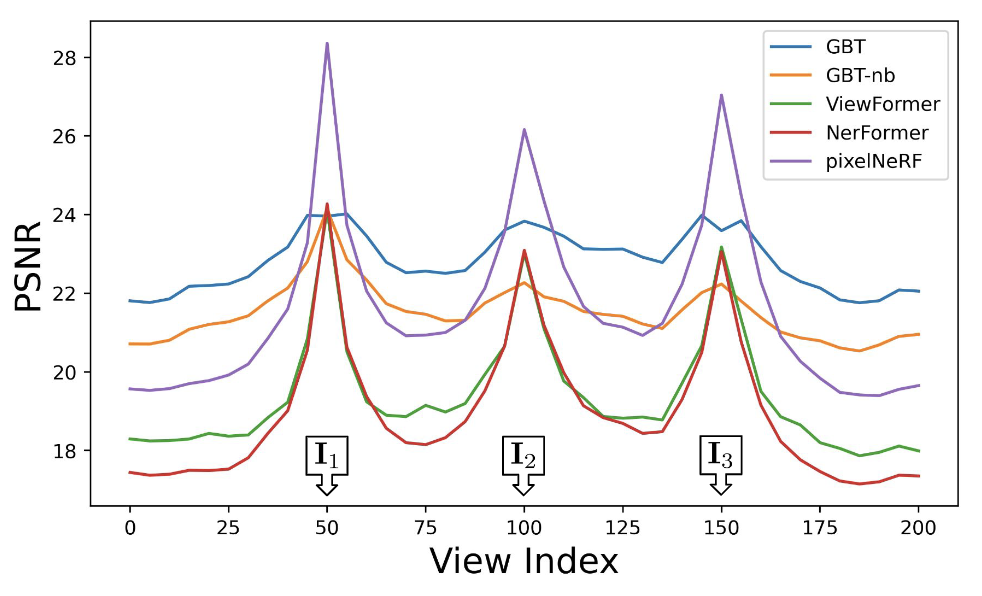
In Fig. 4, we analyze view synthesis accuracy as a function of distance from context views. In particular, we use 80 randomly sampled sequences from across categories with 200 frames each, and set the 50th, 100th, 150th views as context, and evaluate the average novel view synthesis accuracy across indices. We find that all approaches peak around the observed frames, but our set-latent representation based methods (GBT, GBT-nb) perform significantly better for query views dissimilar from the context views. This corroborates our intuition that a global set-latent representation is essential for reasoning in the sparse-view setup.
Ablative Analysis
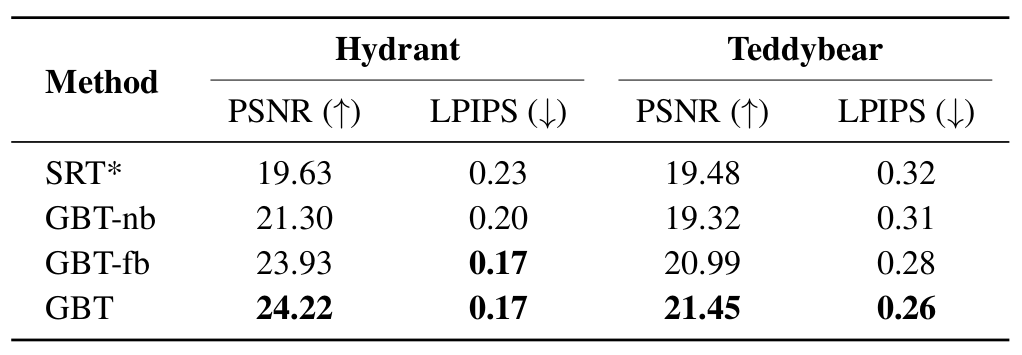
In Table 3 we present a few ablations:
GBT-fb (fixed bias). We keep a fixed weight for the distance bias as a constant γ = 1 (refer to Approach). This avoids the Jacobian computation for γ during backpropagation (which has a memory overhead as big as the attention matrix). The hope is that the relative contribution between dot-product similarity and the distance bias in the attention layers would be implicitly learned by the norm of the token features.
GBT-nb (no bias). As explained before, we replace the geometry-biased transformer layers with regular transformer layers (equivalently, set γ = 0 during training and inference).
SRT*. This variant is closest to SRT where we remove the geometric bias from the transformer layers and replace the Plücker coordinate representation with r = (o, d). This is a variant of SRT with late camera fusion.
For each ablation (GBT-nb, GBT-fb, SRT), we train a category-specific model from scratch and evaluate its results on held-out ob- jects. From Table 3, we notice that a learnable γ (GBT) yields some benefit over fixed γ = 1 (GBT-fb). However, removing geometry altogether (GBT-nb) results in a considerable drop in performance. Furthermore, the choice of Plücker coordinates as ray representations improves the predictions in general as can be seen from the performance drop in SRT. The key takeaway is that a learnable geometric bias, coupled with Plücker coordinate ray representation enables better generalization to novel viewpoints.
Future extensions
Although our GBT framework is designed primarily for novel view synthesis, one can readily extend it to perform multiple image-related tasks. For instance, in addition to predicting pixel RGB, the GBT decoder can be used for semantic segmentation, depth estimation, etc. Intuitively, even though there is no explicit 3D scene representation, GBT is able to reason about both the appearance and the geometric characteristics of the scene.
One way to realize this idea is by relying on a transfer learning setup i.e. by performing a large-scale pretraining of GBT on the novel view synthesis task and finetuning the decoder for other tasks. Another approach could be to train on multiple tasks simultaneously which requires a large number of labeled training datasets.
As a groundwork, we demonstrate a simple experiment wherein we train a model with two tasks – (1) novel view synthesis, and, (2) foreground (object) segmentation. Both tasks are supervised using ground truth available in the CO3Dv2 dataset for the Hydrant class. Fig. 5 shows qualitative results validating our intuition that one can indeed learn tasks beyond novel view synthesis.
