Overview
We aim to render novel viewpoints of previously unseen objects from a few posed images. To achieve this goal, we design a rendering pipeline that reasons along the following two aspects: (i) appearance – what is the likely appearance of the object from the queried viewpoint, and, (ii) geometry – what geometrically-informed context can be derived from the configuration of the given input and query cameras? While prior methods address each question in isolation our method jointly reasons along both these aspects. Concretely, we propose geometry-biased transformers that incorporate geometric inductive biases while learning set-latent representations that help capture global structures with superior quality.
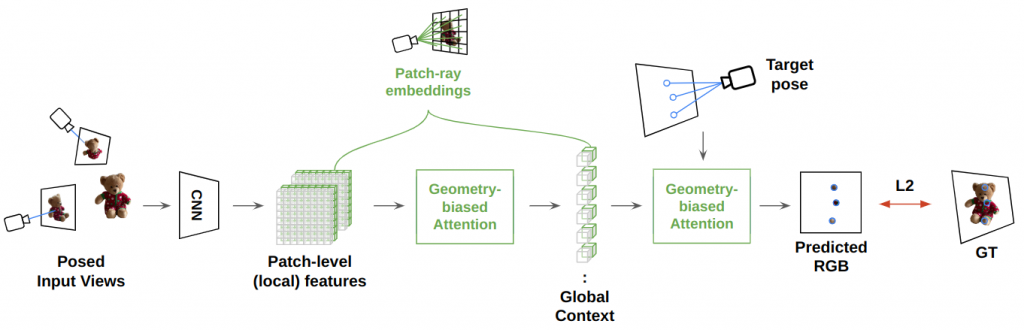
First, a shared CNN backbone extracts patch-level features which are fused with the corresponding ray embeddings to derive local (pose-aware) features. Then, the flattened patch features and the associated rays are fed as input tokens to the GBT Encoder that constructs a global set-latent representation via self-attention. The attention layers are biased to prioritize both the photometric and the geometric context. Finally, the GBT decoder converts target ray queries to pixel colors by attending to the set-latent representation. The model is trained end-to-end using the L2 reconstruction loss for randomly sampled query pixels in a training batch.
Geometry-biased Transformers
Conventional Transformers comprise three key components: multi-head attention, normalization, and, a feedforward network. In particular, the most salient operation – Attention – is described by the following expression:
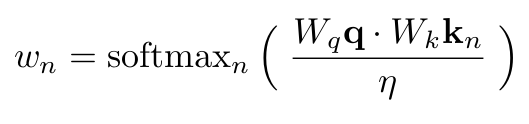
where a scaled dot-product between the key and query tokens is used as the “attention” to perform a weighted aggregation of the value tokens. We refer the reader to Attention is All You Need for more. Typically, the query, key, and value tokens only consist of latent features (for instance, the patch-level features as shown in Fig. 1 above).
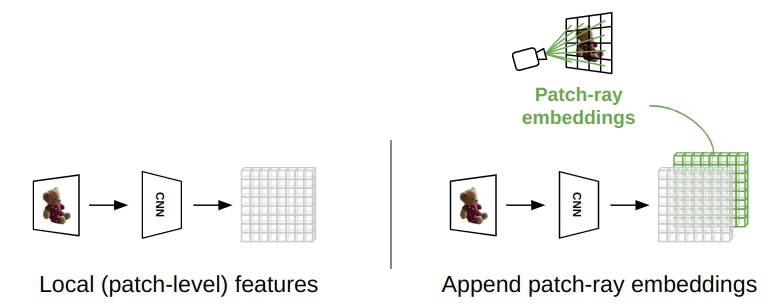
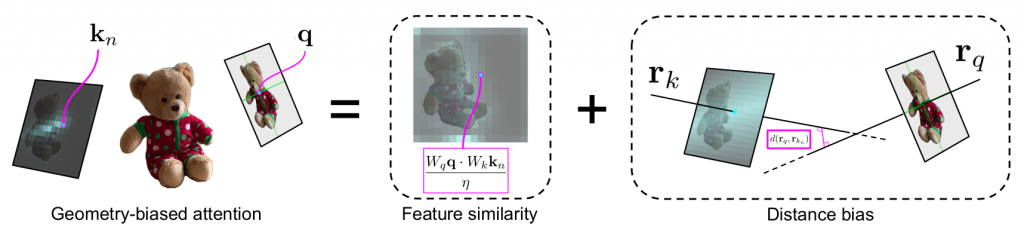
However, our Geometry-biased Transformers additionally incorporate ray geometry to bias the attention toward meaningful regions. Each token is associated with a ray (in the example in Fig. 2 below, each patch feature is appended with a patch ray embedding)
With the latent features modeling the appearance, and the ray embeddings modeling the geometry, we compute an explicit ray-distance biased attention as follows:
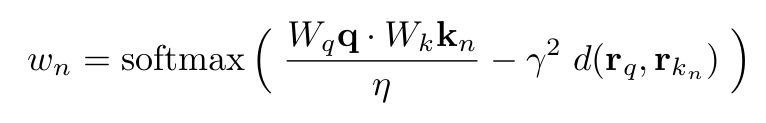
where d(r1, r2) represents the distance between the rays associated with the query and the key tokens. Fig. 3 schematically shows the significance of geometry-biased attention; in practice, the attention is higher toward the patches along the Epipolar line. Note that the distance is multiplied by a weight (gamma) which is learned via backpropagation for each transformer layer.
Ray Geometry
Given a camera’s intrinsic and extrinsic parameters, we obtain patch-level (input images) and pixel-level (query pixel) rays. We use the Plücker coordinate representation to define a ray given the origin o and direction d:
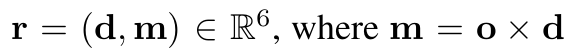
The distance between rays is therefore computed as follows:
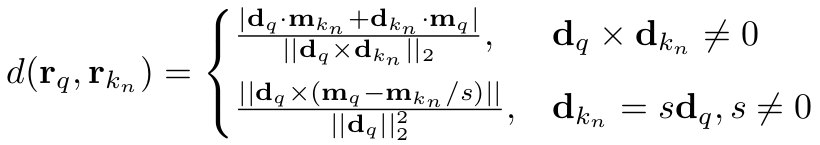
Since we do not have access to a consistent world coordinate frame across scenes, we choose an arbitrary input view as the identity coordinate frame and construct all rays in the identity frame.
It is worth noting that while concatenating the ray information with latent features as shown in Fig. 2 we transform the rays through harmonic embeddings which enables the model to capture high-frequency details.
Implementation Details
CNN. We use a ResNet18 (ImageNet initialized) up to the first 3 blocks as the CNN backbone which enables faster convergence due to transfer learning. The images are resized to 256×256 and the CNN outputs a 16×16 feature grid. These features are concatenated with 16×16 patch rays for each input image.
GBT. We use 8 GBT encoder layers and 4 GBT decoder layers, wherein each transformer contains 12 heads for multi-head attention with GELU activation. Each token consists of a concatenation of latent features and ray embeddings (as shown in Fig. 2). For the harmonic embeddings, we use 15 frequencies {1/64, 1/32, …, 128, 256} which results in a 15x2x6=
Training. During training, we encode V=3 posed input views and query the decoder for Q=7168 randomly sampled rays for a given target pose. The pixel color is supervised using an L2 reconstruction loss. The model is trained with Adam optimizer with 1e-5 learning rate until loss convergence.
Inference. At inference, we encode the context views once and decode a batch of HxW rays for each query view in a single forward pass. This results in a fast rendering time.