4D panoptic segmentation is the task of labeling all 3D points in a spatio-temporal lidar sequence with distinct semantic classes and instance IDs. Such spatio-temporal scene understanding is directly relevant for autonomous navigation, as robots need to be aware of both scene semantics and surrounding dynamic objects in order to navigate safely.
Because this task is naturally formulated as a visible point labeling task, existing datasets such as NuScenes, Semantic-KITTI, etc. make use of modal annotations that do not require estimating labels of occluded regions. In contrast, the 3D object recognition community
makes use of amodal annotations that require hallucinating the non-observable portion of objects (left block in the figure below). As a result of the amodal/modal distinction, disparate methods have been developed for both tasks.
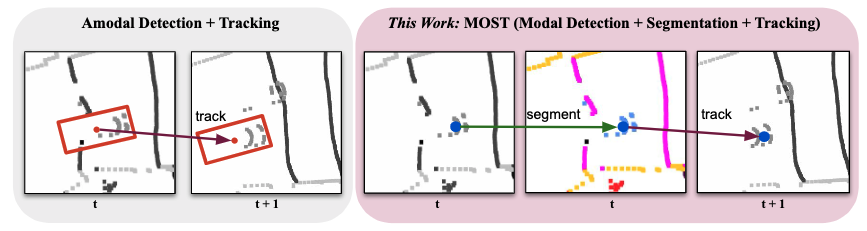
We re-think this approach and suggest that in absence of amodal labels, we can still devise a recognition-centric approach that detects modal centers of objects, followed by binary instance segmentation (right block in the above figure) of nearby lidar points, akin to two-stage image-based instance segmentation networks [20]. This is built on the intuition that methods should maximize all aspects of the panoptic segmentation task, i.e., (i) object recognition, (ii) instance segmentation, and (iii) per-point semantic classification.