Motivation
Perception is the key to safe autonomous navigation. It informs the autonomous vehicle about a) other actors in the scenes like humans, vehicles, etc. b) non-moving structures such as buildings, roads, etc.
There are multiple ways to define an actor or structure in terms of mathematical constructs that can be processed by a computer. A fundamental challenge that we tackle in the project is: How do we define actors?
- Bounding Boxes?
- Centers?
- A Collection of Points?
- Amodal or modal?
Problem
In this project, we focus on Panoptic Segmentation & Tracking, which unifies the typically distinct tasks of semantic segmentation (for each point, assign a semantic label for both stuff and thing classes), instance segmentation (for each point belonging to thing classes, assign a unique instance label) and tracking (assign a temporally consistent unique instance label). Here is a figure illustrating the input and output:
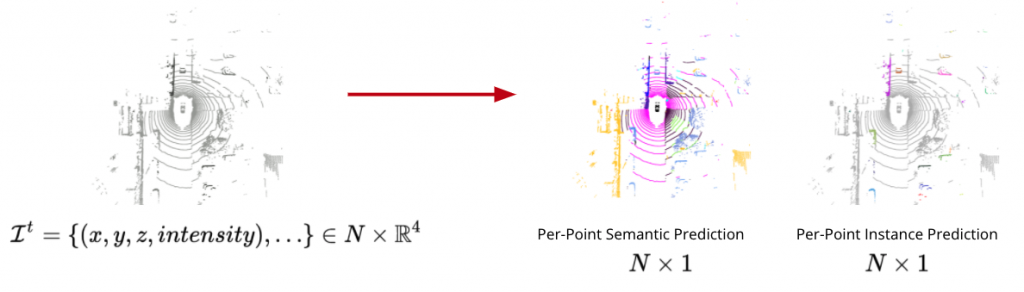
We evaluate our methods on two datasets SemanticKITTI and nuScenes.
Solution
To this end, we pit the bounding box or center-based detectors against point-based segmentors, which have historically been treated as two totally different tasks. We benchmark both approaches of identifying actors against standard benchmarks and combine the best of both worlds to yield better networks.
We present a top-down approach to lidar panoptic segmentation and tracking using only modal annotations. Our unified network jointly detects objects as modal points and classifies voxels to obtain per-point panoptic segmentation predictions. Instances are associated across 4D spatio-temporal data using learned modal velocity offsets to obtain panoptic tracking predictions. Our method establishes new state-of-the-art on Panoptic nuScenes dataset. We hope that this work will inspire future developments in recognition-centric methods for lidar panoptic segmentation and tracking.