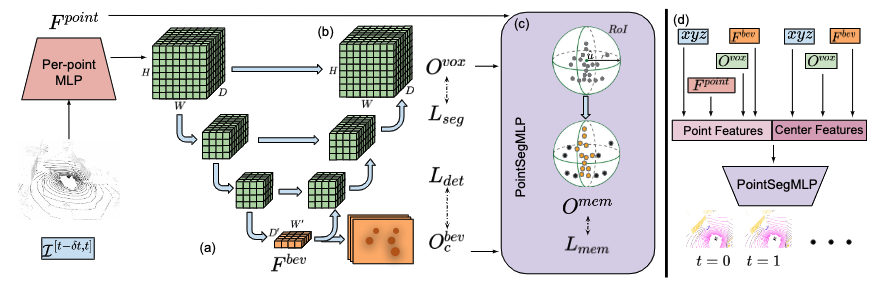
Overview
We accumulate a point cloud sequence and encode it using a voxel grid-based encoder-decoder backbone.
After accumulating encoded points in a 3D voxel grid, we (a) down-sample the volume (via sparse 3D convolutions and pooling layers), and flatten the bottleneck layer along the height-axis to obtain BEV representation (followed by 2D convolutional layers, similar to CenterPoint).
We use this representation to detect objects as (modal) points and regress (modal) offsets for the temporal association.
Our decoder (b) consists of several up-sampling layers to obtain fine-frained, voxel-level semantic predictions.
Our instance segmentation network, PointSegMLP (c) performs binary classification within spherical regions of interest (RoI) centered around predicted centers to obtain object instances.
(d ) PointSegMLP utilizes point and center features as input to produce panoptic segmentation results.
Training
Overall, the network optimizes the following losses:
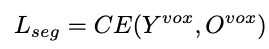
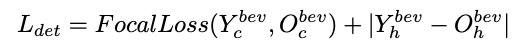
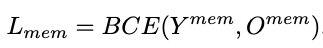
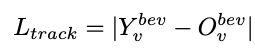
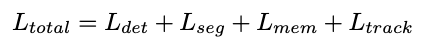
We refer the reader to the presentation for an exact interpretation of all symbols, and to the figure for the function of each of these losses.
Inference
During inference, we fuse segmentation branch predictions, modal center heatmaps, and point-center memberships to obtain 4D panoptic predictions. Intuitively, we listen to the segmentation labels predicted by the segmentation branch and listen to instance labels predicted by the modal centroid membership branch.
Using the segmentation branch predictions, we assign point-level predictions to all points within the voxel. Similarly, we apply non-maximum suppression (NMS) over the predicted center heatmaps to generate predicted modal centers. We then compute the membership of each point p within the RoI of each center using PointSegMLP, resolving overlapping RoIs by the most confident center. Next, we assign the predicted center label to all points that are its members and assign a unique instance-id.
For all stuff points, we directly utilize the predicted semantic label. To extend our method to panoptic tracking, we associate instances across sweeps by using predicted center velocities: we greedily form tracklets by matching previous-sweep centers to current sweep centers with subtracted velocity offsets. Finally, all the instances of an object belonging to a tracklet are assigned a temporally consistent unique ID.