
Given a large unlabelled set of multi-view data (multiple cameras from diverse viewpoints), the goal is to improve the label efficiency of a human part segmentation model by leveraging its multi-view capabilities on the unlabelled set using active learning.
RELATED WORK
HUMAN PART SEGMENTATION
Human part segmentation is a crucial task in computer vision that identifies and outlines body parts in images or videos. Multi-view data can help disambiguate occluded regions and improve segmentation quality. CDGNet[1] is a state-of-the-art method that simplifies the problem using horizontal and vertical class distribution labels as supervision signals. The authors observe that the human body has hierarchically structured parts, and each body part has its unique position distribution. We used CDGNet for our baseline as it provides a robust pipeline and focuses on directional features for human part segmentation, which is helpful for unusual human poses.
ACTIVE LEARNING
Active Learning (AL) reduces labeled data required for training by intelligently selecting informative samples for annotation. AL iteratively selects instances from unlabeled data and queries the oracle for their labels. Various query strategies measure the informativeness of samples based on the model’s uncertainty, disagreement among models, or expected impact on the model’s parameters. ViewAL[2] introduces an innovative active learning (AL) framework designed explicitly for multi-view data. ViewAL utilizes an AL strategy that selects the most informative samples from the multi-view data to be labeled based on view consistency/entropy although they operate on outdoor scene data and are not directly comparable.
Dataset
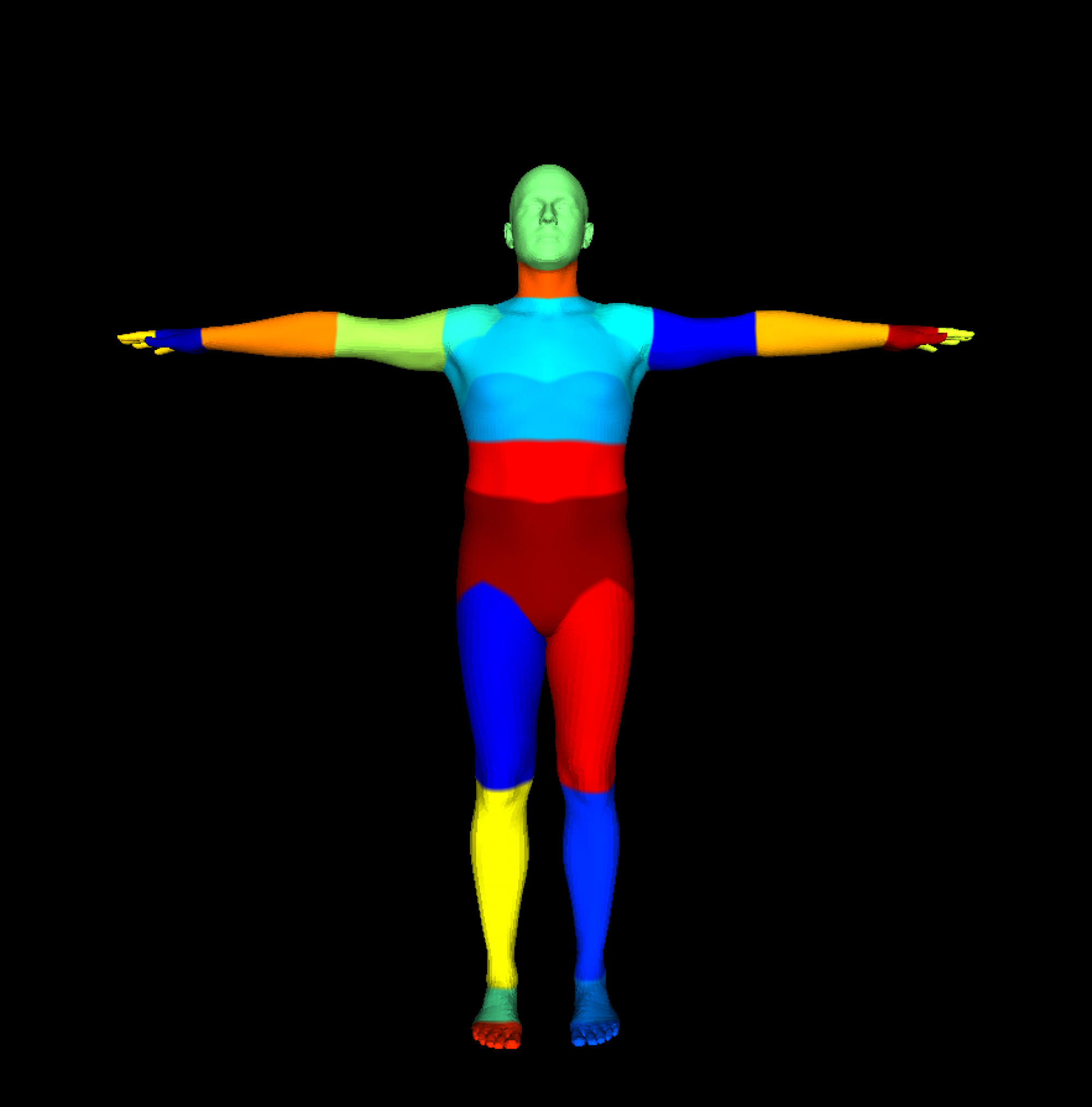
Unfortunately, no direct large-scale multi-view dataset with consistent and strong part segmentation labels exists. Humans3.6 has some weakly labeled part segmentation labels. Thus, we create our synthetic dataset based on SURREAL[3] (Synthetic hUmans foR REAL tasks) data. The primary advantage of SURREAL is that it provides a massive number of annotated samples with precise ground truth information, eliminating the need for manual annotation, which can be both time-consuming and error-prone. We used SURREAL to generate ~2.5M samples out of which we used 80k samples, 66k for training, 7k for validation, and 7k for final testing. This was done due to computational constraints and to accelerate iterations. To sample diverse poses, we check the 3D keypoint distance of the meshes in a video stream and only add frames if the difference exceeds a threshold. We provide the RGB image, part labels, and pixel-wise depth map. Below is an example of an action from our dataset and six views from the same timestamp.

References:
- Kunliang Liu, Ouk Choi, Jianming Wang, Wonjun Hwang: CDGNet: Class Distribution Guided Network for Human Parsing
- Yawar Siddiqui, Julien Valentin, Matthias Nießner: ViewAL: Active Learning with Viewpoint Entropy for Semantic Segmentation
- Gül Varol, Javier Romero, Xavier Martin, Naureen Mahmood, Michael J. Black, Ivan Laptev, Cordelia Schmid: Learning from Synthetic Humans