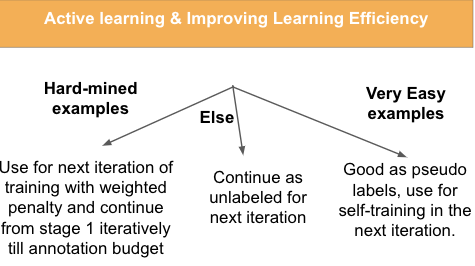

Stage 1:
We start with an initial set of labeled multi-view data. Precisely, 1500 images (150 actions with ten views each) were randomly sampled. This corresponds to ~15% of the total training data. We save this set for all future experiments to maintain consistency.

Stage 2:
In this stage, we train a body part segmentation model. We adapt the architecture from CDGNet, the current state-of-the-art model for this task. We replace the ResNet101 architecture with a ResNet50 backbone to improve training/inference time due to multiple iterations of active learning. We downsample the images to a resolution of 360×640 for the same reason. We do not supervise the model with multi-view training but pass every image independently.
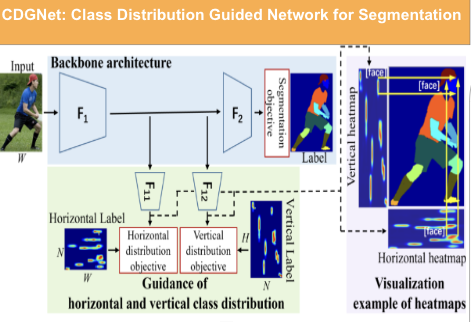
Stage 3:
We save the trained model from the method above and run inference on the multi-view data. We then check for multi-view consistency and diversity of poses according to the following strategy: For every view, we cross project all of the other n-1 views predicted segmentation scores on the given view to compute average segmentation scores. This is then used to compute multi-view uncertainty and we then used entropy/uncertainty based active learning methods on this averaged out score. We can use mesh rendering to project the segmentation features onto the mesh (if available) or point rendering to project the segmentation features into a common 3D space using depth. These are then used to sample hard examples for the next stage of active learning.
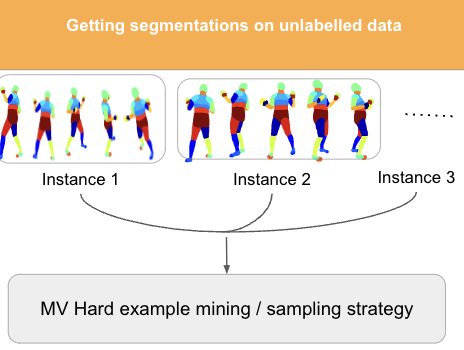
Stage 4:
To use the model’s notion of easy and hard, we plan to use the hard examples (500 i.e. 5% of available data) with higher weights in this next iteration and easy examples as pseudo labels in the next iteration of training. This is motivated by impressive results from Link