

3D Reconstruction and camera poses using COLMAP:

Advanced Feature Detection and Matching
SIFT identifies a vast number of features while the quality of matches might not be good for some pairs of images even with significant scene overlap. Hence, this motivates us to combine both SIFT and facial landmarks to improve reconstruction performance.


Additional features such as deep learning-based features could improve the performance such as SuperPoint + SuperGlue and Facial Landmarks.
SuperPoint Keypoint Descriptors and SuperGlue Keypoint Matching



The SuperPoint and SuperGlue models yielded approximately 500 matches per image pair, marking the highest number of matches among the compared approaches.
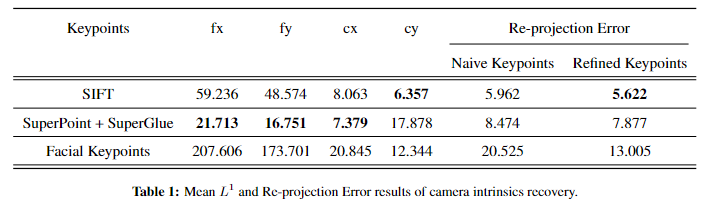
- We achieved a score of 8.4741 (in pixels) in terms of re-projection error, while the L1 error results are shown in Table 1 below. The visualizations of the reconstructions and detected features and matches are illustrated above.
One reason for the re-projection error being higher than only SIFT-based reconstruction might be not finetuning the models for face-specific data given the challenges of key points detection and matches on human faces, such as significant textureless regions and symmetry. Another possible explanation for the underperformance of reconstruction using SuperPoint key points is that SIFT performs better in sub-pixel keypoint localization due to SIFT’s extra sub-pixel localization step, and errors in localization of key points result in the propagation of larger errors to the final geometry.
Facial Keypoint Detection



We extract 217 facial landmarks or key points for each of the images and match them with the corresponding key points in other images.
These matches are close to perfect, however, we only have around 100 matches per image pair because not every image captures the full face.
There is a significant reduction in the number of features and this could be one of the reasons why the performance has deteriorated despite the improvement in the quality of matches. One of the observations we could make from the results of this experiment is that the quantity of matches is equally important in ensuring a quality reconstruction. Additionally, the key points' locations are shifted in the image space, which results in a bigger triangulation error.
Featuremetric Keypoint Alignment
We apply featuremetric keypoint alignment on SIFT, SuperPoint and facial detection key points, and feed the adjusted key points to the pipeline. The table below illustrates that keypoint location alignment enhanced the re-projection error for all these different features as this method improves both triangulation and localization accuracies and consequently more accurate camera parameters and 3D structure.
3D Reconstruction



3D Sparse Reconstruction using SIFT, Superpoint and Facial Keypoints Features (from Left to Right)
Another form of evaluation is to compare the visual quality of the 3D sparse reconstruction of all the experiments so far. The visualisations are displayed above.
- The overall structure is captured using only SIFT features.
- SuperPoint reconstruction has outliers that were not removed during the reconstruction process.
- The facial key points were projected into the space, resulting only in the reconstruction containing those landmarks alone. It fails to capture the overall structure.
Previous Semester Results: Kruppa Equations
We have verified these equations for synthetic data and found that the Frobenius norm of the equations converged to zero. However, the noise from the correspondences between the images might be one of the reasons why these equations are not converging for the face image data.