Background

Autonomous vehicles are advancing rapidly, and a critical part of this progress is understanding the environment around them. For these vehicles to be truly effective and safe, they must be able to recognize not only standard objects that are often annotated during training, such as other vehicles or pedestrians, but also identify and communicate about unusual or unexpected items on the road. This could be anything from construction materials to an animal.
In the joint exploration between Honda 99P Labs and CMU MSCV capstone project, our overarching goal is to enhance the reliability of self-driving cars. By having a detailed and accurate map of both expected and unexpected objects, we hope the cars can gain a thorough understanding of their environment. By accurately classifying and describing these objects, the autonomous system can make informed decisions, ensuring it reacts correctly to different situations. This comprehensive scene understanding is fundamental for preventing accidents and ensuring a safer journey for passengers and those around the vehicle.
- Project Goals:
- 1. Identifying Road Conditions(RC) via semantic understanding
- Parsing expected and unexpected/rare RCs, objects, and layouts
- 2. Identifying Rare RCs and Unknown/rare Objects
- Discovering objects and assessing RCs by open-set models
- 1. Identifying Road Conditions(RC) via semantic understanding
- Task Formulation:
- Frame-wise RC identification and localization by point-level semantic segmentation and object-level detection
- Improving the robustness of known points and objects
- Parsing unknown points and objects

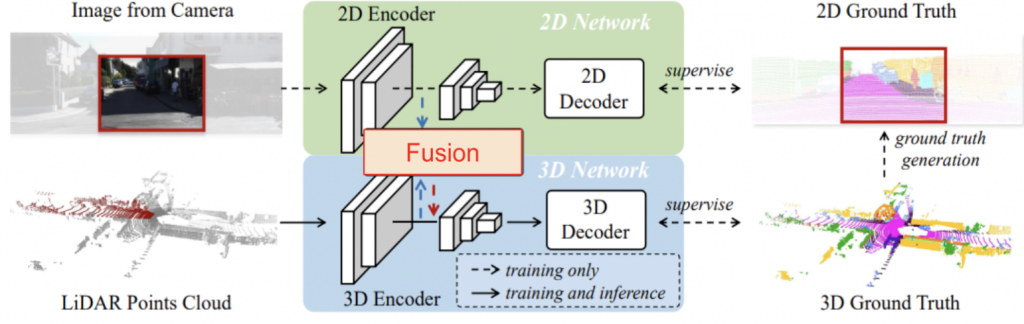
Baseline Network:
2DPASS: 3D Segmentation on LiDAR Point Clouds Assisted by 2D Priors, ECCV, 2022