
Overview
Our goal is to frame a methodology to perform learning-based multi-view vision-only depth estimation with large distortion lenses in real-time on edge devices.
Baseline
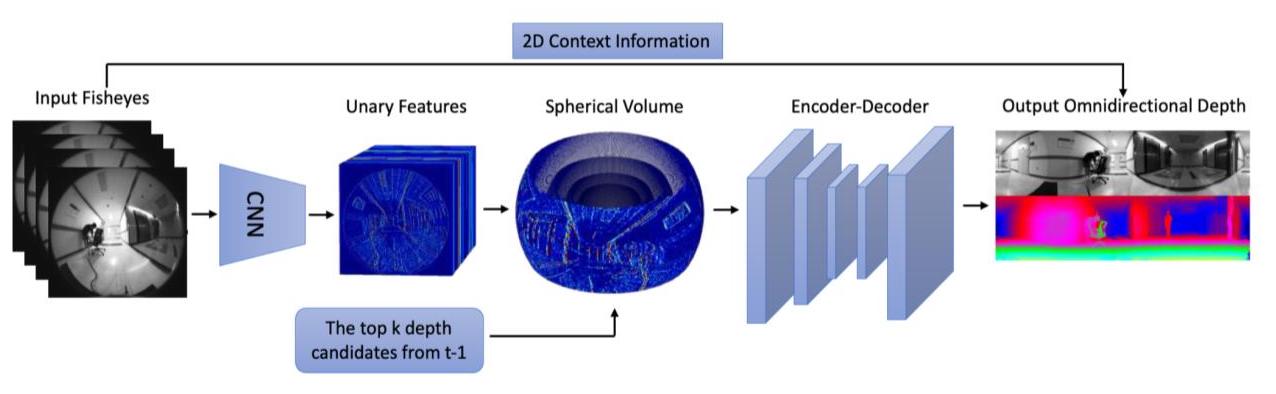
One of our baseline methods is OmniMVS [1], which proposed an end-to-end network architecture for the omni-directional stereo depth estimation. The graph below gives an overview of OmniMVS architecture:
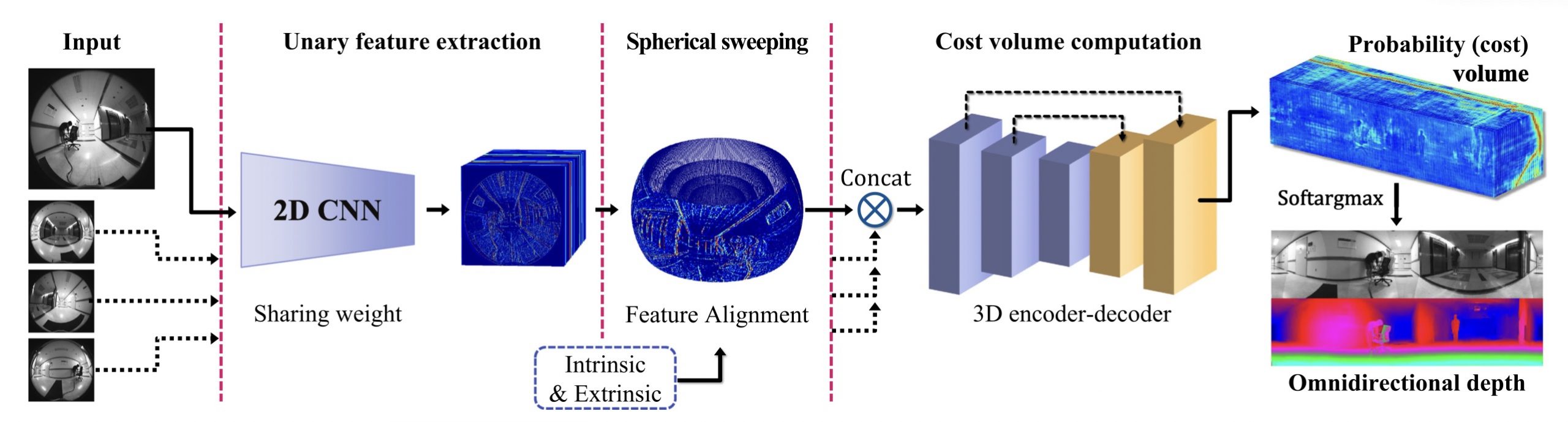
First, the input images are processed by a 2D CNN to extract feature maps. These unary feature maps are then projected into spherical features to create a matching cost volume. The final depth is obtained by computing the cost volume using a 3D encoder-decoder architecture and softargmax.
To generate the spherical features, OmniMVS uses a technique called spherical sweeping, which is a modified version of the plane-sweeping algorithm designed for ultra-wide FOV images. As shown by the graph below, the coordinate system used for this method is based on the rig, with the y-axis defined as perpendicular to the plane closest to all camera centers, and the origin located at the center of the projected camera centers. The spherical sweeping generates a set of spheres with varying radii, representing different depth candidates, and builds the spherical images of each input image.
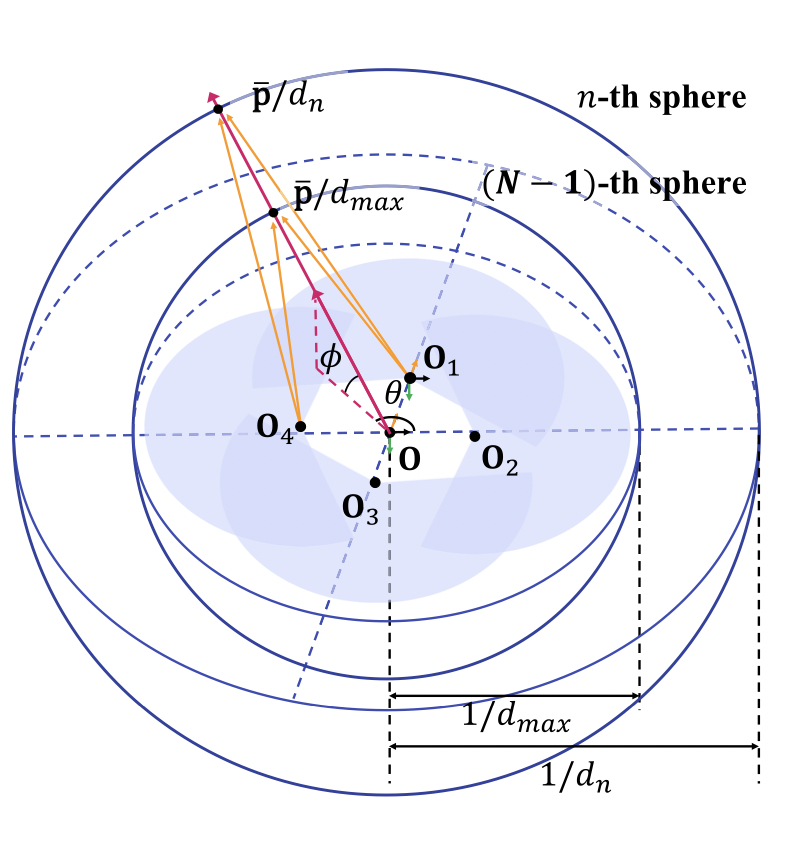
The pixel value of the equirectangular spherical image warped onto the n-th sphere is determined as, 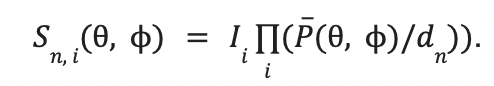

The depth results from previous methods such as SweepNet often struggle to handle multiple true matches, resulting in incorrect depth estimates for thin objects that are overridden by the background depth. These methods also face challenges when dealing with large textureless regions such as ceilings. In contrast, OmniMVS leverages multi-view observations and global context information to address these issues, leading to improved depth estimation results as shown in the last row of the results.

Despite its advantages, OmniMVS is not without limitations. There are instances where it may mispredict depth, such as when stairs are parallel to the stereo baseline or when objects are very close to the rig. However, the paper proposes the use of an uncertainty measure that can indicate complex and ambiguous regions in depth mapping, which can help mitigate these problems [1].

Baseline results
The results from the baseline method on the 6-camera rig:

Approaches
1. Temporal Sequence Information
To improve the efficiency, the top k depth estimation from past keyframes with offset learning will be incorporated when building the spherical volume. Similar approaches were shown to have SOTA MAE/MRE results in Matterport3D and 360D datasets by [2]. In addition, 2D context information from the input fisheye images will also be considered to further enhance the accuracy of the depth estimation.
2. Fisheye Space Convolutions
Traditional convolutions assume spatial feature invariance (i.e. content-agnostic) which doesn’t apply when working with fisheye images. Instead, we plan to use,
- Deformable convolutions: which has learned 2D offsets similar to the approach used in [3]
- Spherical convolutions: which has a preset kernel map depending on the location of distortion
- Pixel-adaptive convolutions: in which the kernels are content and/or position dependent as described in [4]

Spherical Convolutions
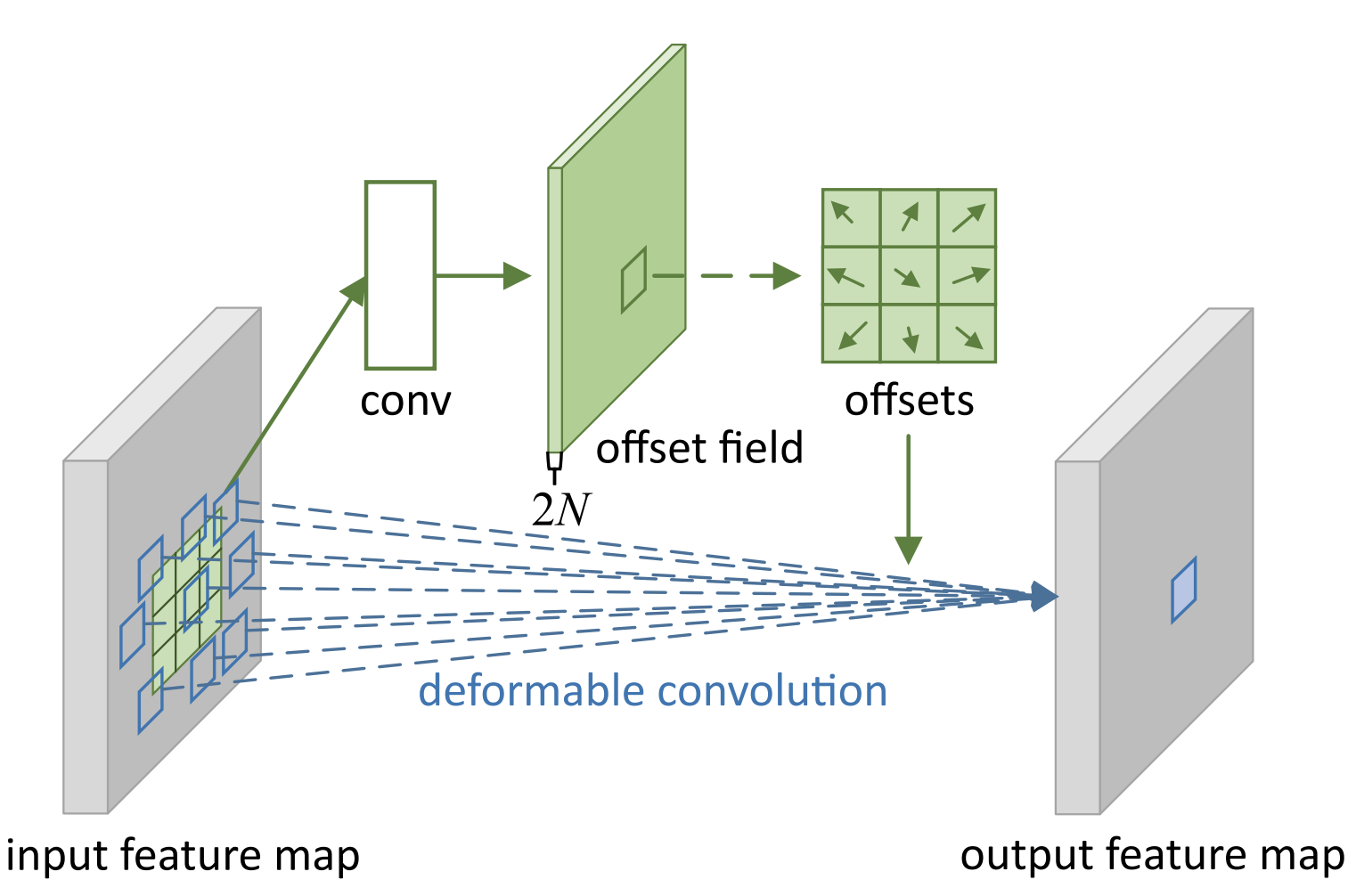
Deformable Convolutions
References
[1] C. Won, et al. “End-to-End Learning for Omnidirectional StereoMatching With Uncertainty Prior,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021
[2] G. Pintore, et al. “SliceNet: deep dense depth estimation from a single indoor panorama using a slice-based representation,” IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021
[3] V. R. Kumar et al., “FisheyeDistanceNet: Self-Supervised Scale-Aware Distance Estimation using Monocular Fisheye Camera for Autonomous Driving,” IEEE International Conference on Robotics and Automation (ICRA), 2020
[4] V. R. Kumar et al.; “SynDistNet: Self-Supervised Monocular Fisheye Camera Distance Estimation Synergized With Semantic Segmentation for Autonomous Driving”, IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2021