
There are different approaches to build a visual system to teach origami folding. One simple approach would be one that just provides pictures of the end result of each step along with some textual explanation. Users using this system would have to manually advance to the next state and there is no feedback on the user’s progress. Such kind of system is like a digital version of the instruction manuals. Unfortunately, most origami teaching systems today are some version of this.

no tailored instruction
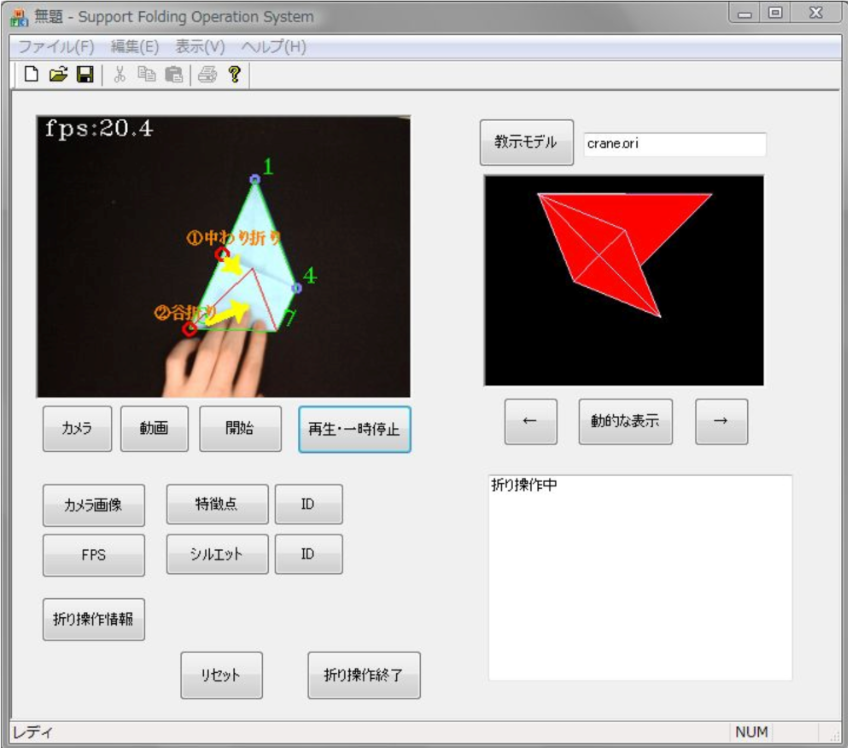
The prior pipeline that is most directly related to our work is a series of work [4][2][8][5][6] from 1997 to 2020 by a group of Japanese researchers that aim at a similar goal of automatically recognizing steps and offering feedback. However, their pipeline which uses only machine learning algorithms have some downsides and limitations. First, due to the large use of machine learning algorithms, their pipeline consists of many pre-processing and post-processing steps, which render it exceedingly complicated. Secondly, they heavily restrict their application to situations of a black background with white papers. Thirdly, since the core algorithm in their pipeline is silhouette matching, their definition of each step depends entirely on the silhouette of the paper, without any consideration of the creases which can divide the overall folding process into more detailed steps. Lastly, their approach of instruction giving is limited to a computer application that only shows you the step recognition result and instructions for next steps on the screen.
As a comparison, our projection-based system has the benefit that the origami learners do not have to frequently switched their attention between the instruction and the paper in their hands, thereby improving their learning efficiency. Admittedly, this kind of projection does have an undeniable limitation that it only works on planar surfaces, but with careful selection of origami models and definition of each steps, the effect of this limitation can be minimized.
A recent works [7] also tries to use mixed reality system to aid origami teaching. However, their work suffers from similar problems that there is only minimum level of interaction and it contains no automatic step tracking or tailored instruction at all. Users have to manually click the button to see the instruction for the next step. Besides, a previous work [3] and a recent application PlayGAMI [1] can achieve real-time automatic paper tracking or step tracking, respectively, but both of them depend on the visual cues on their customized paper surfaces, which are highly restrictive and not generalizable to common origami papers.
In contrast, our data-driven models using neural networks leverage the prior underneath the data, which can be easily collected in our case. The model can achieve straightforward automatic step recognition based on the appearance of the user’s paper with no assumptions about the appearance of the background or the paper.
References
[1] Uttam Grandhi and Ina Yosun Chang. 2019. PlayGAMI: augmented reality origami creativity platform. ACM SIGGRAPH 2019 Appy Hour (2019).
[2] Jien Kato, Hiroshi Shimanuki, and Toyohide Watanabe. 2006. Understanding and Reconstruction of Folding Process Explained by Illustrations of
Origami Drill Books.
[3] Atsushi Nakano, Makoto Oka, and Hirohiko Mori. 2013. Leaning Origami Using 3D Mixed Reality Technique. In Human Interface and the Management of Information. Information and Interaction Design, Sakae Yamamoto (Ed.). Springer Berlin Heidelberg, Berlin, Heidelberg, 126–132.
[4] Hiroshi Shimanuki, Jien Kato, and Toyohide Watanabe. 2002. Constituting Feasible Folding Operation Using Incomplete Crease Information. In IAPR International Workshop on Machine Vision Applications.
[5] Hiroshi Shimanuki, Yasuhiro Kinoshita, Toyohide Watanabe, Koichi Asakura, and Hideki Sato. 2016. Operational Support for Origami Beginners by Correcting Mistakes. Proceedings of the 10th International Conference on Ubiquitous Information Management and Communication (2016).
[6] Hiroshi Shimanuki, Toyohide Watanabe, Koichi Asakura, Hideki Sato, and Taketoshi Ushiama. 2020. Anomaly Detection of Folding Operations for Origami Instruction with Single Camera. IEICE Trans. Inf. Syst. 103-D (2020), 1088–1098.
[7] Yingjie Song, Chenglei Yang, Wei Gai, Yulong Bian, and Juan Liu. 2020. A new storytelling genre: combining handicraft elements and storytelling via mixed reality technology. The Visual Computer 36 (2020), 2079 – 2090.
[8] T. Watanabe and Yasuhiro Kinoshita. 2012. Folding support for beginners based on state estimation of Origami. TENCON 2012 IEEE Region 10
Conference (2012), 1–6.