
Overview

We are interested in building an advanced system that can use a camera to automatically track the progress of the user in real time and provide folding instructions overlaid on the tracked paper. In order to achieve this, we exploit data-driven models to replace some machine learning algorithms used in the previous pipeline which engender restrictive set-up, impractical assumptions, and complicated data processing steps. Our system design (Fig 1 left) uses an iPad with a mirror device from Osmo attached to its front camera, which can simultaneously captures the user building origami on a table while providing some visual guidance on the screen visible to the users. From RGB image input, our system predicts the current state of the origami. Based on its prediction, if the user successfully arrives at a new step, the system will provide instructions for the next step; otherwise, it will offer tailored feedback to correct the mistake. During actual usage, when the users finish a step, they move their hands away from the paper (since it will be predicted as the transition state otherwise), and receive the feedback based on the model prediction. Subsequently, the system overlays the folding instructions on top of the paper using a projector,
along with some optional text. This pipeline is also shown Fig 1.
State Estimator
The main functionality of our vision based system is to automatically recognize the user’s current step in real-time. We view this step recognition problem as a multi-class classification task tackled using convolutional neural networks. Each state, either a finished step or a transition state in between two steps, of the origami paper will be established
by the state predicted by the convolutional neural network classifier. For the sake of accuracy, we define every image frame with hands occluding the origami paper as the transition state. Such design choice largely removes the adverse effect of hand occlusion during step recognition without large demands on the user’s side.
Our network architecture is straightforward. We initialize a ResNet18 model with weights pre-trained on ImageNet and replace the last classification layer with our own. Then we fine-tune it using our dataset explained in the following section.
Dataset

We need a dataset to create robust computer vision models for Origami Sensei, that can accurately recognize different origami states. Another perspective to view this is that, the previous work manually records the operation detail of each fold in special data structures, while we use neural networks to implicitly remember the appearance of each fold, which requires a dataset per origami model. Another benefit from using neural networks is the ability to generalize across different paper and background pattern after training with data augmentation.
There are a few publicly available origami datasets but they were not suited for our task. We collect our own dataset by recording videos of a person making origami against a green background using an iPad with the Osmo mirror and base, just like how an actual user would use it as in Fig. 1. It is important that our collected samples are consistent in term of the distance and the angle to the paper, and use consistent lighting to capture as much detail as possible. In addition, we pre-process our videos into an image dataset by extracting frames at 10 fps, cropping out the interested area, and applying homography transformation to fix the perspective effect. The resultant images for an origami dove model is shown in Fig. 2 left and middle. For simplicity, all transition states are pooled under state 0.
The time cost to collect and manually annotate hundreds of videos to build a large dataset per origami model is infeasible. To overcome this problem, we collected two videos and used green screen techniques to replace the background with other texture images to augment the dataset (Fig. 2 right). Specifically, we synthesize 10 new videos with different texture background and add into our dataset. Furthermore, during training, we also employ online color jittering along with other data augmentation techniques as well so that the trained network can generalize to a reasonable spectrum of background texture, paper colors, lighting, distance, and angles.
Experiments
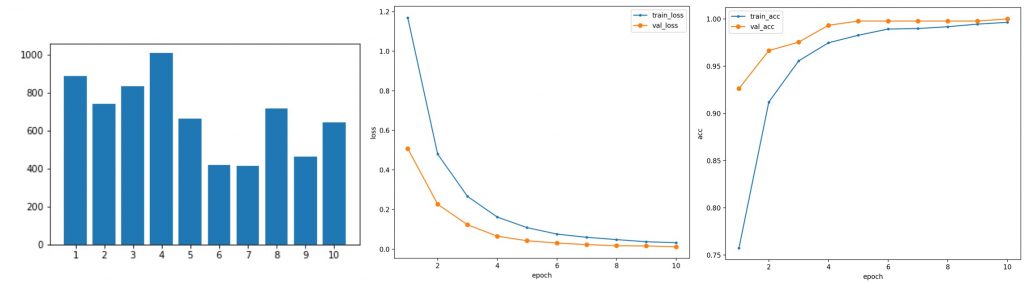
After collecting our dataset, extracting and pre-processing the image frames, and synthesize data with different background texture, we fine-tune our ResNet classification model on the final dataset with various types of data augmentation. The trained model achieves 99.8% test accuracy on the test set (from the same videos), only failing at 1 out of 451 total test frames. This experiment proves that our convolution neural network can implicitly remember the appearance and features of different steps.
Currently, we are using PyTorch Mobile, Core ML Tools, and SwiftUI to make an iOS app and deploy the network on an iPad to run inference. It remains as the next step to test its generalization ability in real time and conduct user study on the experience.