Title
Visual Features Disentanglement into Interpretable Attributes Features using Prompts
Research Question:
How do we describe the distribution of image data?
Abstract
Deep Neural Networks are considered black-box mod- els as the feature embedding are often entangled and not human-interpretable. Though the feature embedding en- codes the information regarding understandable attributes (e.g., tail, head, wheel), it is distributed in the embedding and thus entangled. In this paper, we propose a simple method to disentangle dense image representations into a weighted combination of interpretable visual attributes by learning a simple linear projection in the joint space of a vision language model (VLM) in a data-driven fashion . By using images to weight attributes, our attributes are more semantically meaningful to the underlying data distribution than the generic curated attribute methods proposed in the literature. We demonstrate that our interpretable embed- ding performs competitively as compared to the dense em- bedding. Our discovered attributes act as better prompts under few shot settings, outperforming prompt-tuning methods (CoOp ) by 3% on 1 and 2 shot settings. Moreover, we also show a variety of potential downstream applications enabled by data-driven attributes, such as measuring domain shift, open vocabulary classifications and attribute- guided zero shot detection.
Contribution
- We propose a simple yet efficient method to disentangle dense visual features to a weighted combination of interpretable attribute feature in language domain.
- We shows that our interpretable feature is a semantically meaningful yet a competitive feature in adapting visual concept by showing our superior performance on few shot evaluation.
- We also shows the potential of the attribute feature by showing a skew of downstream application like measuring distribution shrift, solving open-vocabulary classification and detection.
Motivation
- Feature embedding encodes the information regarding understandable attributes (e.g., tail, head, wheel) over data distribution, but it is distributed in the embedding and thus entangled.
- Semantic based disentangled feature can be interpretable data distribution measurement.
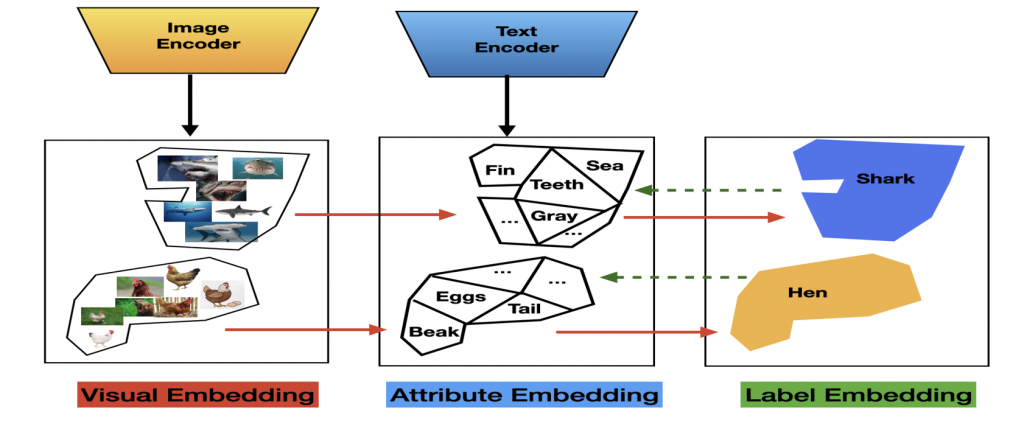
Pipeline
- Visual feature encoding and attribute text feature encoding with CLIP.
- Calculate pair-wise cosine similarity score between each attribute and class feature.
- Dataset adoption by performing linear probing over cosine similarity.
- Class-wise visual feature become a weighted combination of interpretable attribute feature.
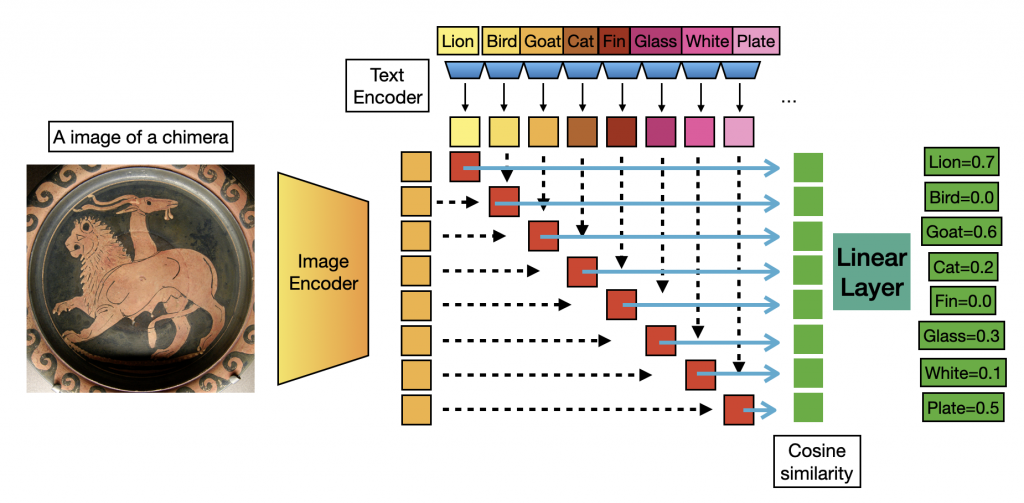
Application
- Few shot generalization
- We aim to show that attributes generated in a data driven fashion from images collections could be a better visual descriptor compared to previous method which querying from LLM.
- Our method outperform all previous finetuning method on 1 & 2 & 4 shot for a large margin. Compare to CoOp, which is a good baseline that use gradient propagation to learn the optimal embedding for prompting, but this will results in a non-interpretable feature. We shows the superiority of out method in terms of accuracy, interpretability and training time on extremely few shot setting.
- We aim to show that attributes generated in a data driven fashion from images collections could be a better visual descriptor compared to previous method which querying from LLM.
- Quantifying distribution shift
- Quantifying distribution shift of ImageNet-sketch and -R(endition) dataset with respect to ImageNet1K dataset us- ing VAS-attributes (top-10 pos & neg). We observe that color- less attributes become dominant and color attributes become subservient on ImageNet-sketch and art attributes become dominant on ImageNet-R. This demonstrates that we can capture the distribution shift in a human-interpretable way.
- Quantifying distribution shift of ImageNet-sketch and -R(endition) dataset with respect to ImageNet1K dataset us- ing VAS-attributes (top-10 pos & neg). We observe that color- less attributes become dominant and color attributes become subservient on ImageNet-sketch and art attributes become dominant on ImageNet-R. This demonstrates that we can capture the distribution shift in a human-interpretable way.
- Open vocabulary object classification
- We show that it’s possible to enable the classifier to gen- eralize onto novel concept(in this case, classify purple lemon) by swapping the order of our interpretable attributes feature.
- Attribute guided detection
- We repurpose CLIP RN50x64 for detection by computing the cosine similarity values between the Resnet embedding and our class-specific attribute list before the attention-pooling layer. This gives us a measure of which regions in the image correspond more to the input attributes, acting as a low-cost detector. On querying individually using our Hippopotamus and Nile Crocodile class attributes we can detect both classes respectively. These detections are obtained solely using our class-attributes which do not make use of the class-name.



