Motivation: In order to investigate how model architecture might affect predicted confidence distribution, we propose to measure how different models are calibrated on detection task.
Dataset: COCO 2017, 2D detection.
Metric: mAP, ECE, D-ECE, Brier score
Candidate: GLIP(Vision-language model, zero shot), CenterNet-V1, CenterNet-V2, FCOS-R-50, FCOS-X-101, Faster-Rcnn, RetinaNet
Calibration method: beta calibration and histogram binning
Before calibration:
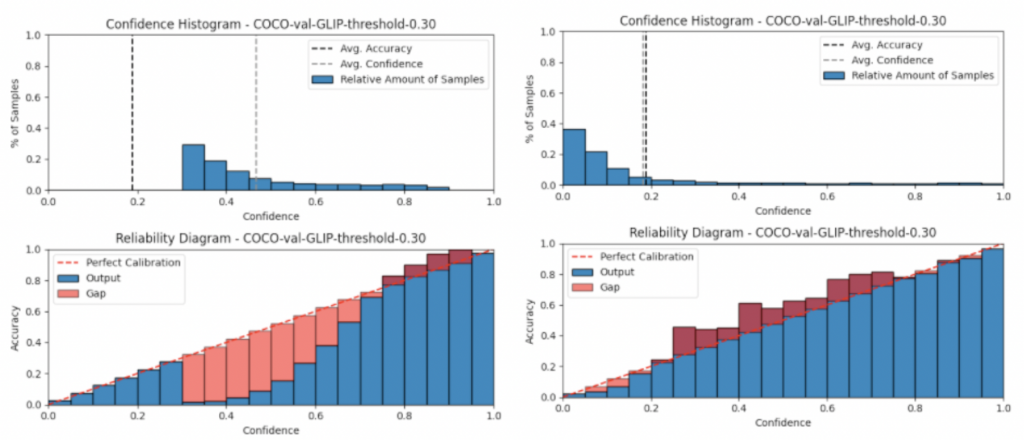
We first compare the performance of different model . Result shows the following observation:
- GLIP are extremely overfidence for P< 0.7, and slightly underconfidence for P>0.7
- CenterNet is perfectly calibrated at low P, be more and more underconfidence as P increase
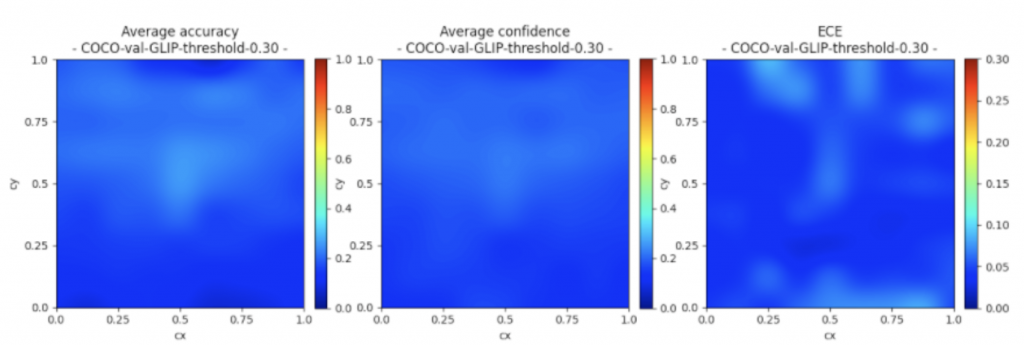
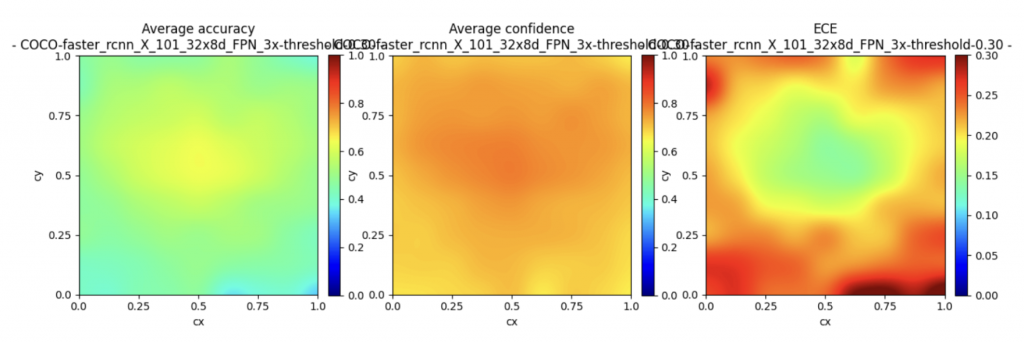
- Faster RCNN tend to predict extreme P(0 or 1), might to do with two stage structure(disregard RPN objectness confidence score). And D-ECE is sensitive to box position in image.
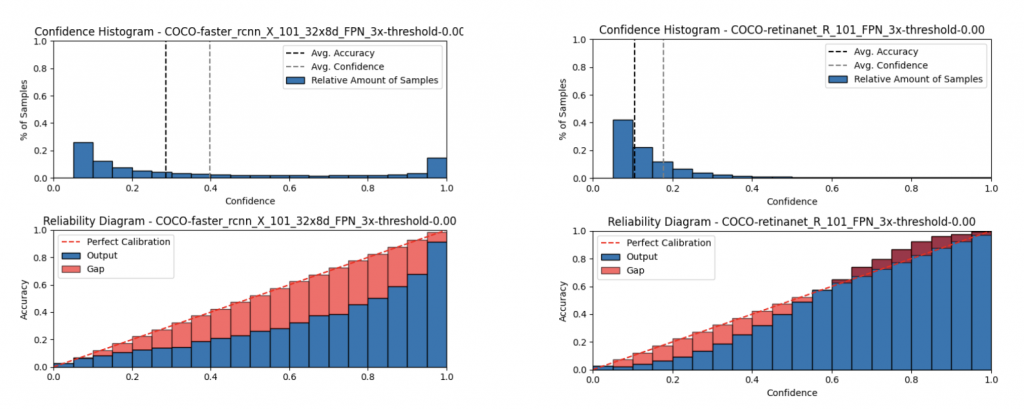
- All method are overconfidence at low P, under-confidence at high P (except for two stage Faster RCNN!)
- CenterNet2 (probabilistic aware) and RetinaNet (train with focal loss) is most well-calibrated in general
After calibration:
Surprisingly, after calibration, result shows GLIP receive the best performance in both mAP (detection accuracy) and ECE(uncertainty measurement). This shows that,
- 1. Simple classification calibration methods could already receive relatively good results on detection.
- 2. Large-scale pre-train is potentially useful for certainty aware since it knows more about ‘what is certain and what is uncertain’ in a more realistic setting.