
Data Capture Setup
The camera we are using comes with an orthographic lens and has a very small field-of-view, and has a very narrow depth of focus. It images a very small section of the scene and has a very narrow depth-of-field. Thus, only a thin slice of the scene will appear in-focus in the captured image. We mount the camera onto a robot arm that moves the camera along the optical axis away from the scene slowly. The camera records a video during the process. In our setup, the camera moves 0.2 inches in 60 seconds, and captures video at 5 fps, resulting in a total of 300 frames for each scene.

We captured two fabric materials under our imaging system. Below we show a sample image from each focal stack
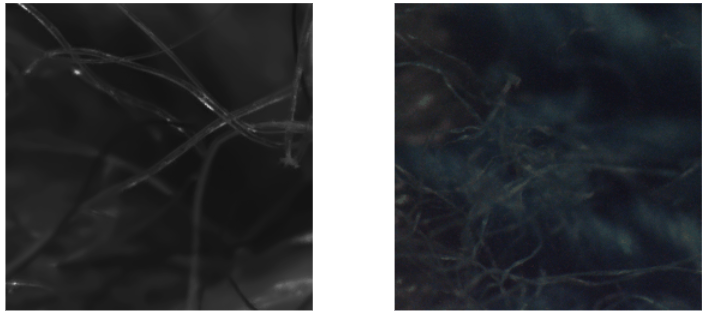
Fabric materials are particularly challenging and interesting under microscopic scale, due to the occlusion, specular reflection, and complicated geometry.
Qualitative and Quantitative Results
Due to the limitations of our hardware, we cannot obtain accurate measurements of ground truth depth in our captured datasets of microscopic-level scenes. Consequently, we are unable to conduct a quantitative analysis of the depth map’s accuracy. To address this, we rely on a synthetic refocusing task to evaluate the effectiveness of our method. By generating images with unknown focus settings that were not used during network training, we can assess the performance of our method.

Dense Focal Stack
We also explore whether the method needs a densely-sampled focal stack. Our original dataset, after preprocessing, contains 36 images from foreground focus to background focus. We examine the model performance when we subsample the dataset. The result is shown below. We see that the method requires a relatively dense focal stack for good performance. One possible reason is that our model only explores per-image feature, but does not model relation across images. In general, the focal stack should contain at least one sharp image of each textured structure in the scene.
