Given that high-quality 2D facial data is available more readily, estimating 3D facial geometry from an uncalibrated 2D image has gained tremendous traction in recent times. Motivated by this, our goal in this project is to work towards improving the quality of 3D face reconstruction from a single 2D image in a weakly supervised setting. We explore a few popular and state-of-the-art 3D Face Reconstruction techniques from a single 2D image and ran the following baselines to test their performance in the real world.
1. Deep 3D Face Reconstruction:
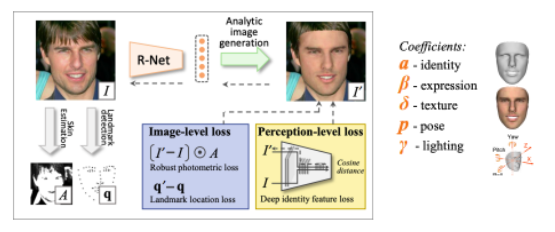
Deep3D Face Reconstruction was introduced in CVPRW 2019. It involves training an end-to-end 3D Face Reconstruction pipeline given one or more images of a person in a weakly supervised setting. In our experiments, we will be focusing on generating a 3D mesh and texture of a person given a single 2D image.
For a single image, the pipeline consists of training an R-Net module which is a resent-based encoder that, given an image predicts BFM 2009 coefficients like identity, expression, and texture along with pose, and lighting parameters. Given these coefficients, we can recover a 3D mesh of a person that when rendered with the given coefficients should give us back an image that is as close as possible to the original image. Using this fact we train the network using losses like Robust photometric loss, Landmark location loss, and Identity loss on the rendered image and the input image.
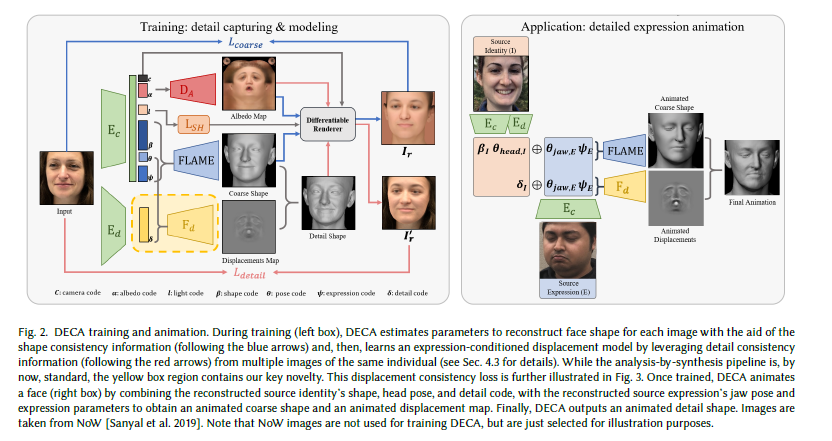
2. Detailed Expression Capture & Animation (DECA)
Most of the work priors to DECA focused on training models to estimate the parameters of statistical shape models like 3DMM from in the wild images using analysis by synthesis losses. These approaches were only able to capture low-frequency shape information which affects the linear shape space and would result in overly smooth reconstructions which are unable to capture geometric details such as expression-dependent wrinkles which are essential for realism.
DECA focused on solving the problem of lack of high-frequency details by incorporating two changes to the standard 3D Face Reconstruction pipeline:
1. Use of FLAME model which can better model the mesh and expressions through its parameter space.
2. Use of Displacement maps that represent a per-vertex offset and can be thought of as UV maps. These offsets can be used to capture dynamic details like wrinkles that change with expression.
We achieved the following results on running the DECA model through some sample test images:

4. OSTeC: One-Shot Texture Completion
OSTeC paper introduced in CVPR 2021 tries to generate high-quality texture by leveraging the power of StyleGAN. StyleGAN is a powerful generator that can be used to better generate the unseen parts of the face. Here is a brief overview of the pipeline:
1. OSTeC reconstructs an initial 3D model of the face by estimating 3DMM parameters and lighting and pose parameters.
2. Multiple views of the face are captured by cameras placed at fixed locations.
3. Each one of these views is reconstructed by performing GAN inversion and then generating it through StyleGAN.
4. For the reconstructed views we perform interpolation to generate a texture UV map.
5. These generated textures are then blended progressively to generate a final output UV texture map.


Optimizing the UV texture map using OsTeC architecture
Face frontisation & texture generation outputs:
Here are some of the results of performing OsTeC optimization on our faces.

