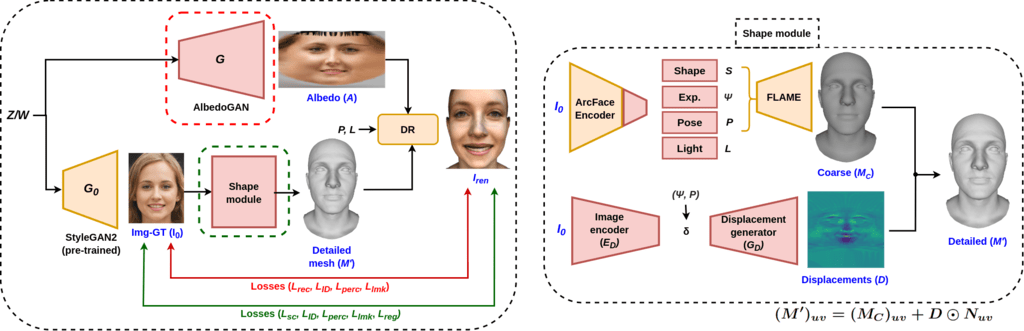
Our proposed pipeline involves generating albedo and a detailed mesh for the latent vector sampled from StyleGAN’s latent space, which together leads to a realistic 3D rendering. In particular, we use a StyleGAN-based generator to generate albedo, which is called AlbedoGAN. To predict the detailed mesh, we first predict a coarse mesh using a ResNet-based encoder to predict parameters like shape, expression, pose, and lighting. We then use encoder decoder based pipeline to predict the displacement map for the coarse mesh leading to the generation of a detailed shape. We found that jointly optimizing the texture and the mesh is quite difficult, and hence we use alternate descent optimization to train our pipeline. The overview of our method is described in Figure 2 and in the following sections we describe each component of our pipeline.
1. Albedo Pretraining
1. 1 Texture Extraction and Correction
We fit a 3DMM model on a given 2D image I to compute a color for each vertex and map it to cylindrical coordinates using the estimates from the pose and camera parameters to obtain texture T. This step establishes the correspondence between each mesh vertex in 3D and the uv domain. Interpolating the captured color values based on the 2D barycentric coordinates and saving them in the image channels gives the texture a smooth look.
By interpolating the obtained texture with pose, texture correction fills in the parts that are hidden. This happens by projecting the flipped input image onto the same mesh and unwrapping it to get the pixels corresponding to the missing parts. The pose determines how many of these pixels are added to the original texture. The below figure explains the texture-pertaining step in detail, which involves obtaining an albedo and shading map from the unevenly illuminated texture.
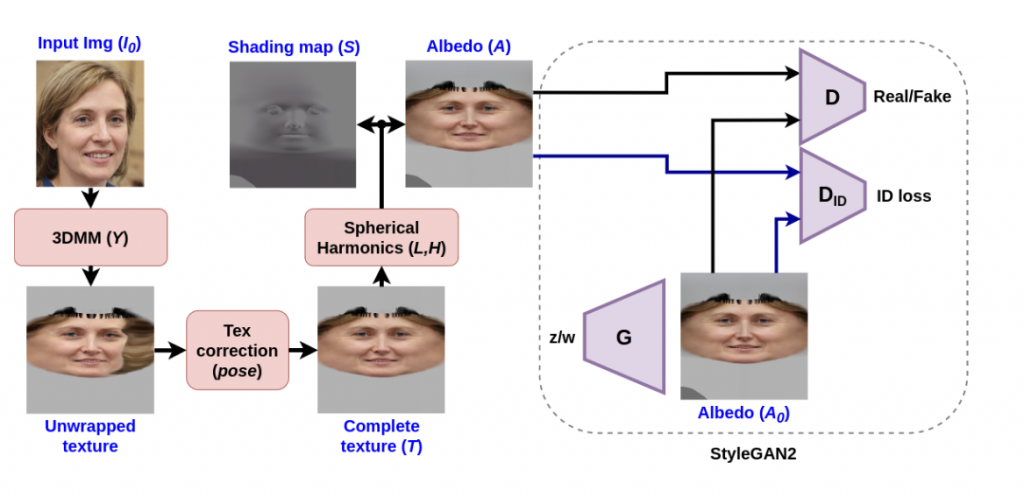
Figure 1: Texture pretraining. Pose-invariant albedo(A) obtained by texture-preprocessing is used to train StyleGAN2 generator(G).
1.2 Pretraining AlbedoGAN
As a next step, we train AlbedoGAN on the albedo obtained by previous steps. The output of trained AlbedoGAN will assist the shape and displacement map training. However, while training the AlbedoGAN, this method does not consider the geometry and more sophisticated illumination model. Thus, we fine-tune the AlbedoGAN trained in this section later with a differentiable renderer and detailed shape (as described in Sec. 2). Since our approach requires a good generative model that can synthesize images (specifically face images) corresponding to a latent vector, we used StyleGAN2.
2. Alternate Descent in Albedo and Shape
In this section, we describe how we estimate the 3D shape from the face image and fine-tune the pretrained AlbedoGAN with a differentiable renderer (DR). While fine-tuning, we take into account expression, camera pose, and a more complex illumination model. We optimize for the best 3D face that is consistent with the input image.
Unfortunately, jointly optimizing all the components (shape, albedo, illumination, etc.) is computationally expensive. Thus, we propose using Alternate Descent for optimization. First, we optimize the shape for a few iterations using the pretrained AlbedoGAN, followed by fine-tuning it using a detailed shape. Subsequently, using the updated AlbedoGAN weights, we again train the shape model and continue to do this alternate optimization throughout the course of training.
2.1 Albedo optimization
To fine-tune AlbedoGAN using the information of the 3D shape and illumination model, we first assume we have an estimate of a detailed 3D shape M’ (explained in the next section). As can be seen from Fig. 2, given an input image, estimated mesh M’, predicted albedo A, pose P, and light L we can generate a detailed rendered image. The loss between the original and rendered images is used to fine-tune the AlbedoGAN (G). We use the following losses to optimize our pipeline:
Symmetric Reconstruction Loss: Reconstruction loss is a simple supervision function that encourages low-level similarity between the predicted image and the corresponding ground truth in the original image and the albedo. We use the mean squared error (MSE) to calculate the reconstruction error as follows:
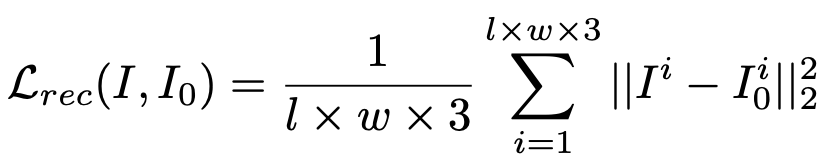
Identity Loss: When we are fine-tuning the model, we use the cosine distance to figure out how much identity loss there is. This essentially teaches the generator to match the rendered face’s identity with the ground truth.
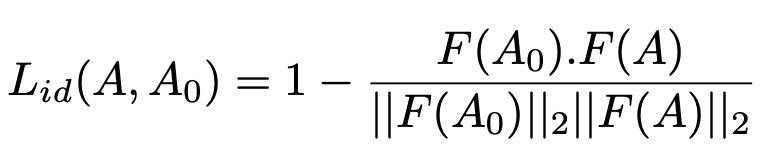
Perceptual Loss: We use the perceptual loss to compare the high-level similarity features for fine-tuning AlbedoGAN. This loss forces the model to generate a more realistically rendered image. Based on the research that has already been done, we use a VGG16-based face recognition model that has already been trained to supervise the training. The loss is calculated by the L2 norm of the difference vector, and the perceptual loss is defined as:
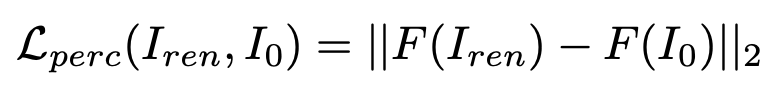
Landmark Loss: We supervise the training using 68 facial landmarks detected in the ground truth and the rendered image to avoid misaligned generations for the landmarks. We used a SOTA face landmark detection FAN to predict 68 landmarks on all the images. We then calculate the loss by taking the mean of the per-landmark distance. The loss can be expressed as:
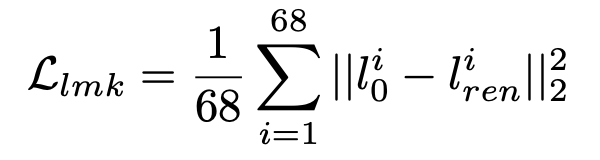
2.2 Shape optimization
This section describes optimizing the shape using AlbedoGAN trained so far. We sample a latent vector w and use pretrained StyleGAN2 model to generate a 2D face image I’, AlbedoGAN to generate albedo A. Note that this albedo A is the one obtained by the pre-trained StyleGAN texture model, not the fine-tuned one. Figure 2 describes the detailed architecture of our shape model. We leverage ArcFace backbone to predict the face shape, expression, pose and lighting parameters.
Motivated by DECA, to capture high-frequency details in meshes, we learn a displacement generator to augment the coarse mesh with a detailed UV displacement map D. This displacement map is conditioned on a detailed code, and predicted expression & pose parameters, respectively. Finally, we combine the displacement map along the vertex normals of the mesh to get a detailed mesh M’ by adding them in the UV domain.
We apply multiple 2D image-based losses, including identity loss, perceptual loss, and landmark loss between the original and rendered images to optimize the mesh representation in a self-supervised fashion. In addition to the losses, we compute a shape center loss on identity images, i.e. In particular, the below equation tries to reduce the distance between shape vector for all the images and their corresponding mean:
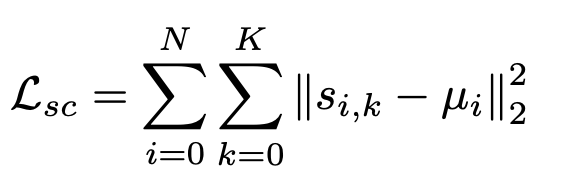
Besides this, we also perform L2 regression on predicted shape, expression, and displacement maps that enforce a prior distribution towards the mean face:
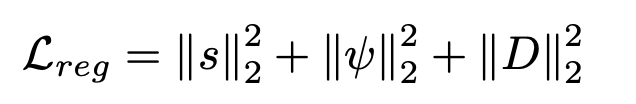
Dataset and Implementation Details:
The corresponding w was generated by randomly sampling 100K 512-dimensional random vectors z from a Gaussian distribution and setting the truncation to 0.7 and the truncation-mean to 4096. To ensure diversity in the generated images across ethnicity, expression, age, and pose. We used 30K of the previously sampled z vectors to train our shape model with 2D data. Then, we use StyleGAN2 to do latent space editing in the w space to make a total of 11 images per identity that show different expressions and poses. We estimate 68 landmarks on all the GT images using FAN landmark detection.