

Menu
Fall 2022
Spring 2022
Fall 2022
To review, the challenges we face with Synthetic Dataset generation are as follows:
- It is very time-consuming to build a dataset.
- Multiview setting requires a lot of hacking to the game.
- Domain transfer would be a problem
With these challenges in mind, we pivoted to the TBD Pedestrian dataset by CMU, which is multi-view and provides camera matrices and 2D trajectory labels for every pedestrian in all 3 camera views. The dataset is time synchronized so we know the frame number, pedestrian ID, and position coordinates of every person across all views.
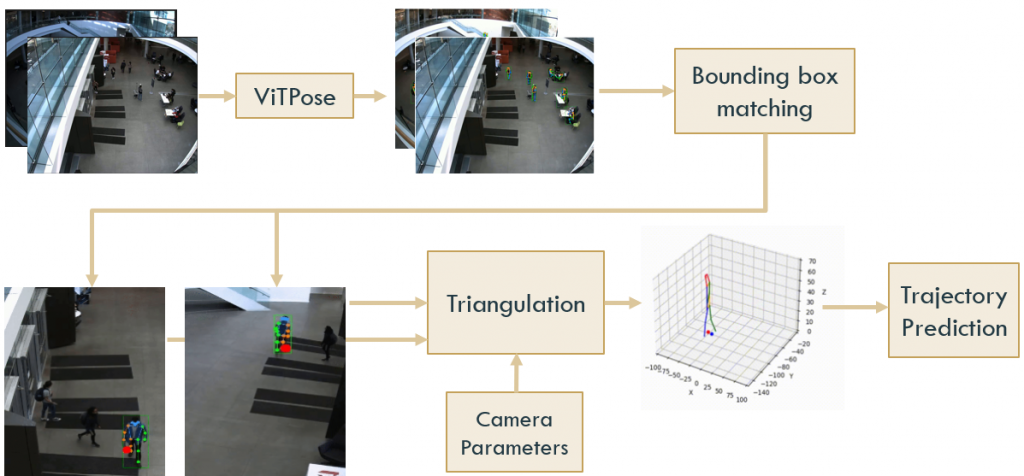
The pipeline we designed for 3D trajectory prediction is as follows:
- Perform 2D pose estimation with ViTPose on all 3 camera views
- Use a Greedy approach to match the bounding boxes of each pedestrian across at least 2 camera views.
- Create a dataset of 2D pose sequences for each pedestrian across 2 camera views.
- Perform triangulation using the camera matrices and the 2D pose sequences to obtain the 3D pose ground truth for each pedestrian
- Perform trajectory forecasting to predict the 3D trajectories of each pedestrian
(I) 2D Pose Estimation with ViTPose
Results of ViTPose on TBD Dataset



(II) Bounding Box Matching
Now that we have obtained the bounding boxes and 2D pose key points for each pedestrian, we need to match them across camera views. We need 2D pose sequences for each pedestrian across camera views so that we can triangulate them to obtain 3D pose key points. Since 2 views are sufficient for triangulation, we perform bounding box matching for View 1 and View 2.
To match pedestrians across views, we use the following greedy approach:
- for each pedestrian with a trajectory label and pedestrian ID, for the first frame of that pedestrian ID, we find the closest bounding box to the trajectory point.
- for subsequent frames, we track that bounding box, by finding the bounding box with the highest IOU with the previous frame


We now have a sequence of 2D pose trajectories for each pedestrian in both views, on which we can now perform triangulation to obtain 3D pose information.
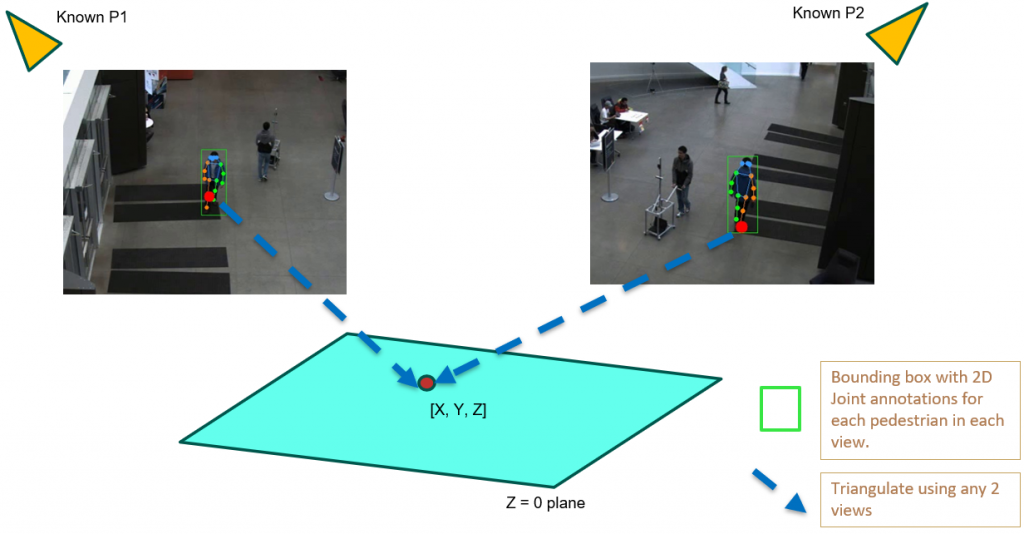
(III) Triangulation
We use 2D pose sequences from view 1 and view 2, and the camera matrices for triangulation to obtain 3D ground truth pose sequences for each pedestrian.
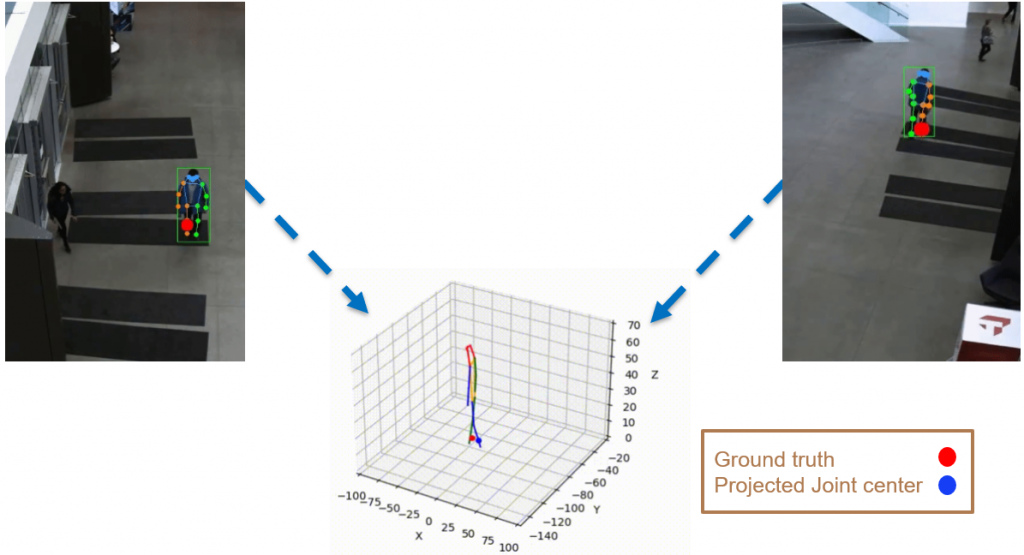
However, the triangulated 3D joints are noisy due to the downstream errors from both pose estimation and bounding box matching. Hence to obtain a smoother trajectory with less jitter we apply smoothening on skeleton gravity, limb length, and limb angles.
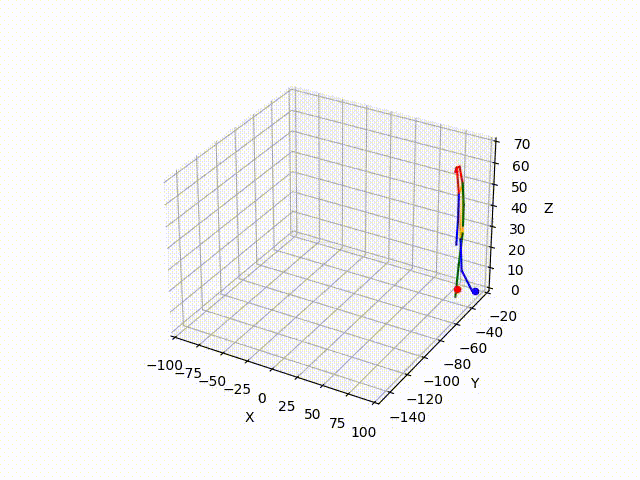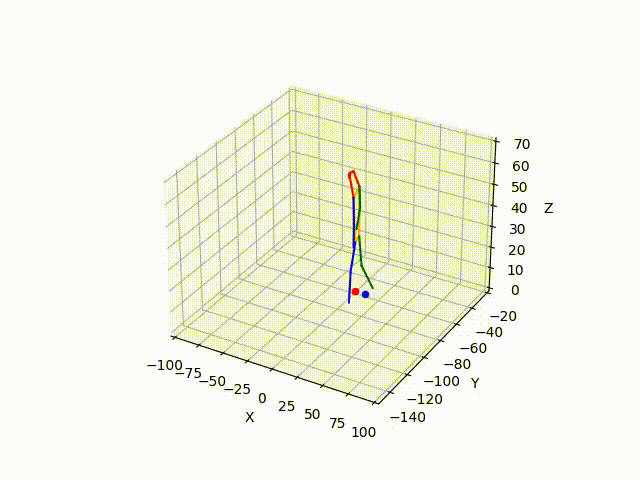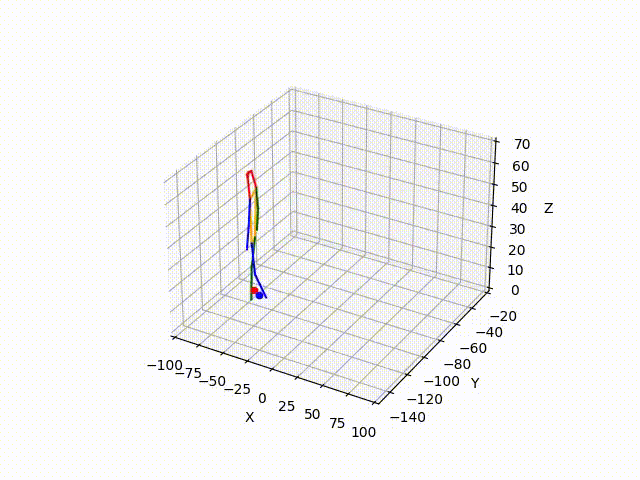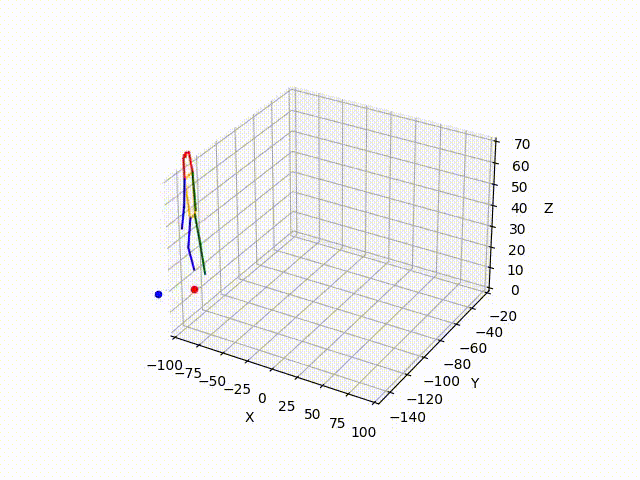
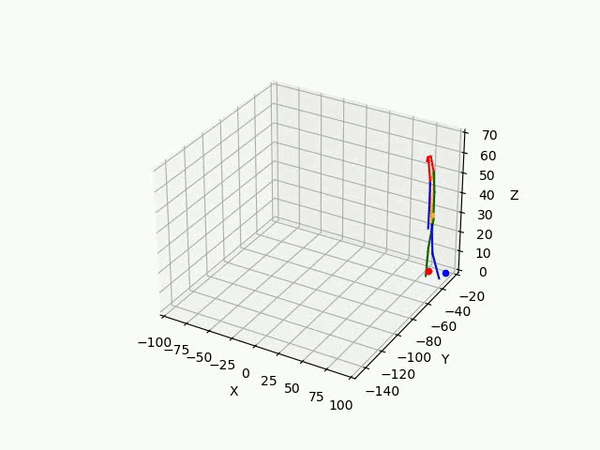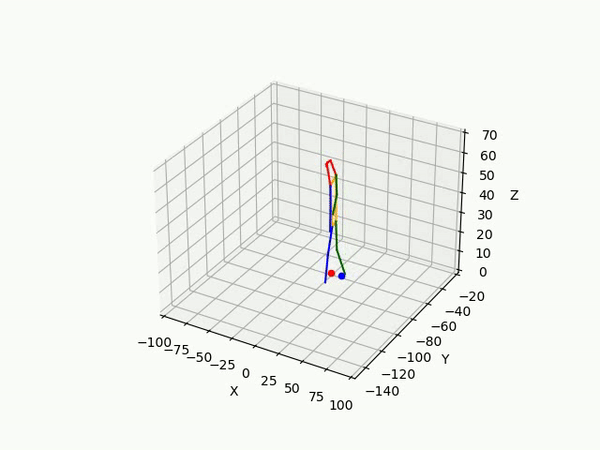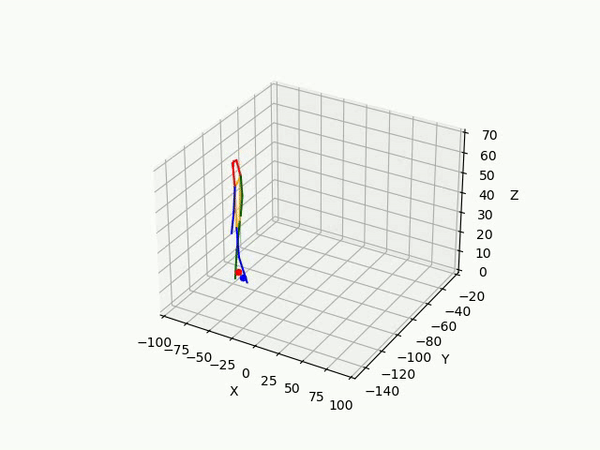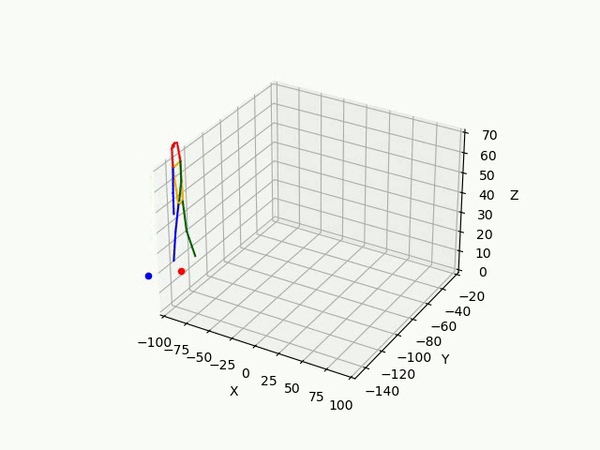
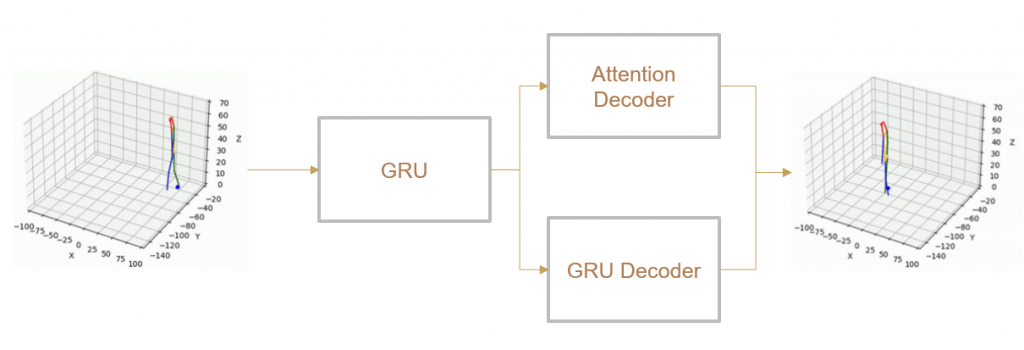
(IV) Trajectory Forecasting
We take 2 approaches to trajectory forecasting:
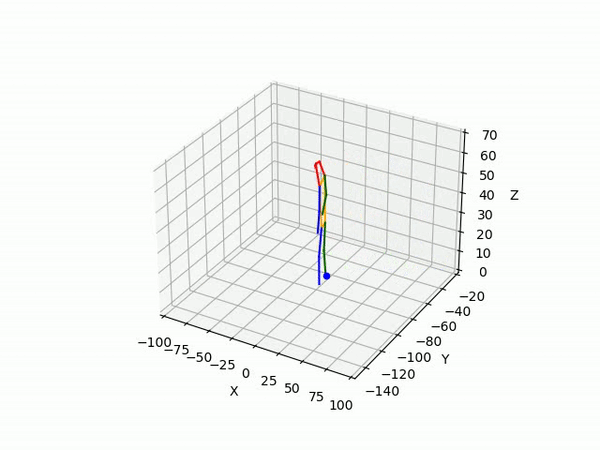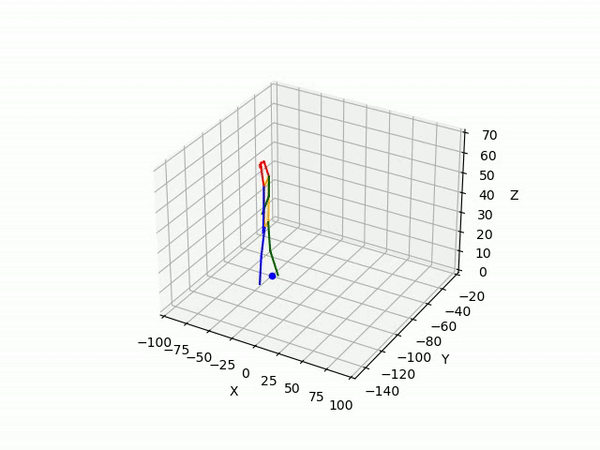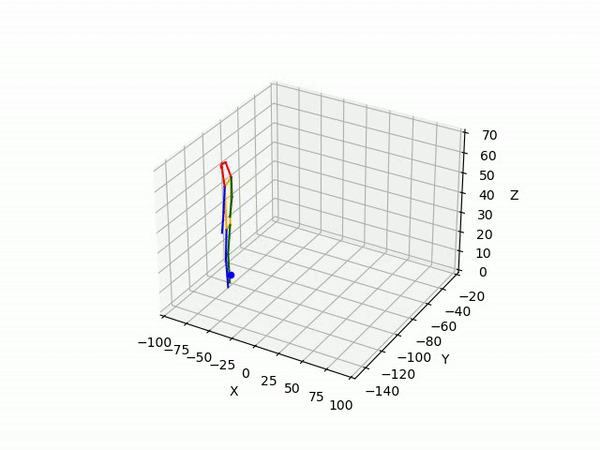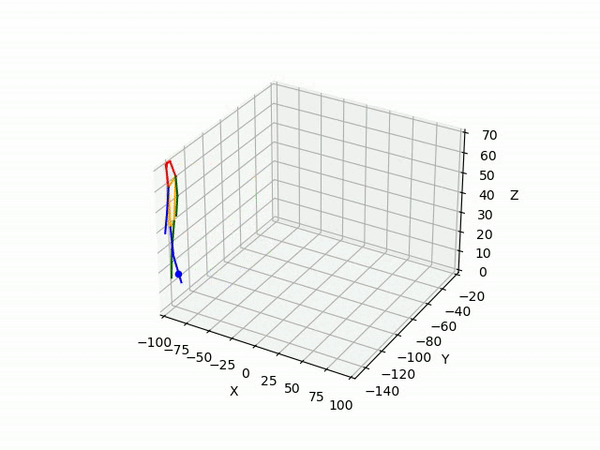
- Predicting 3D point trajectory
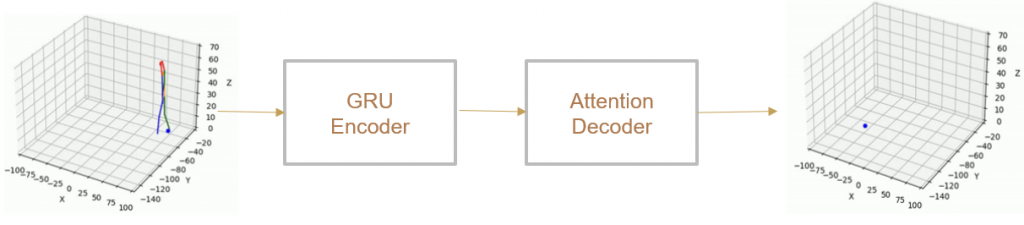
Result
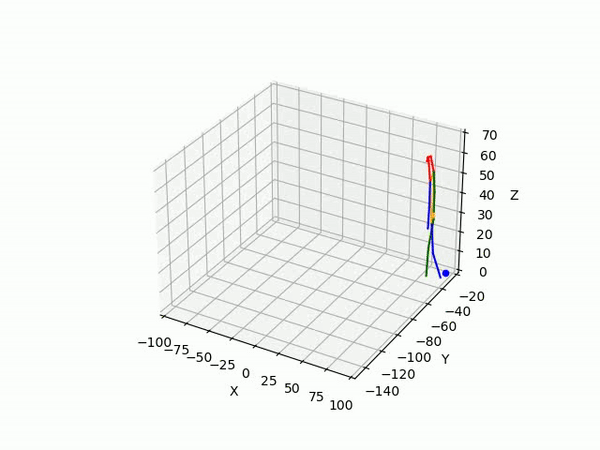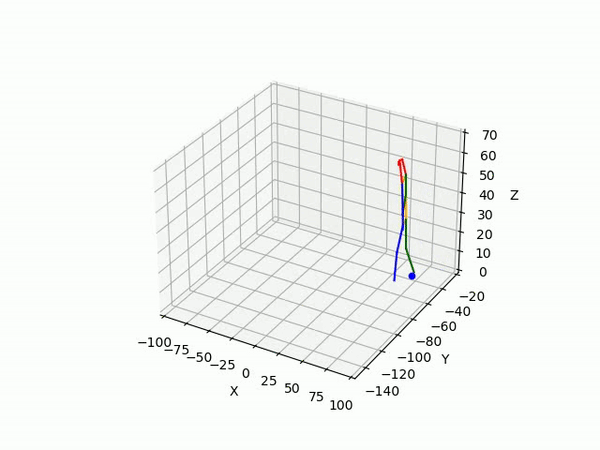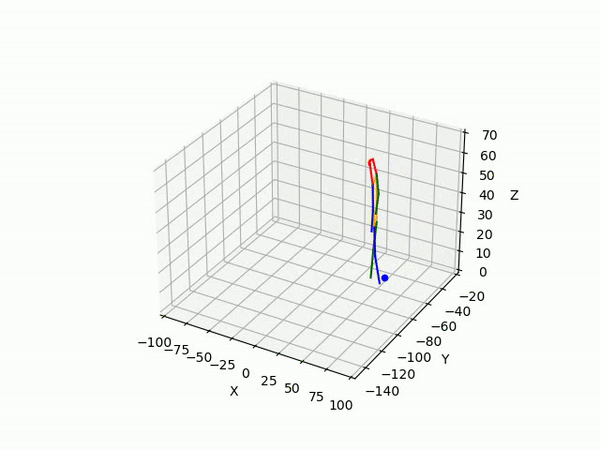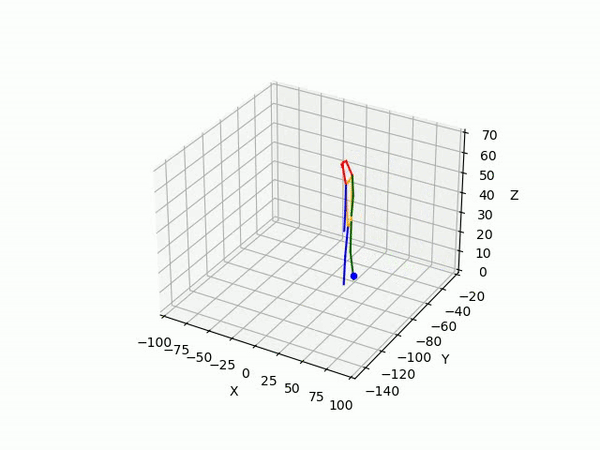
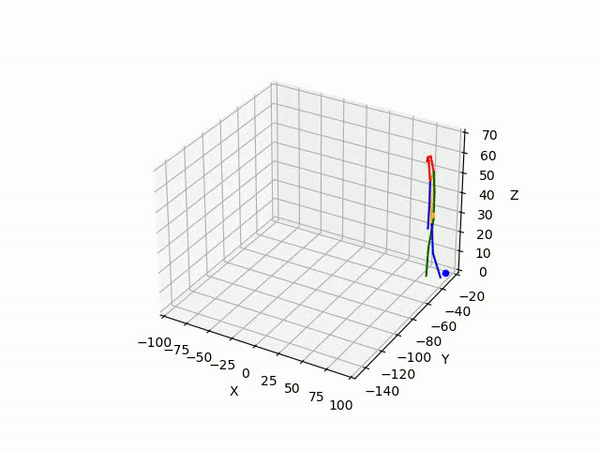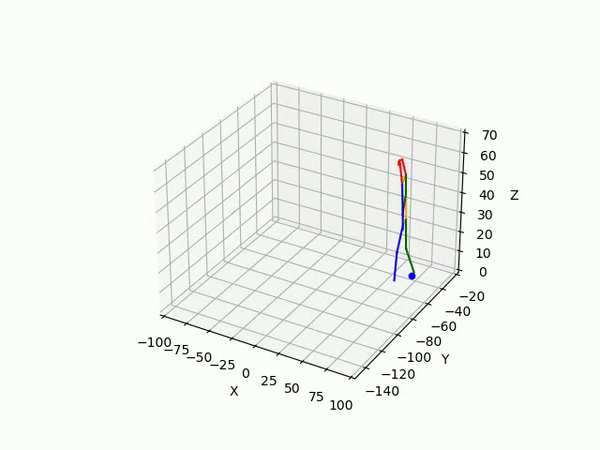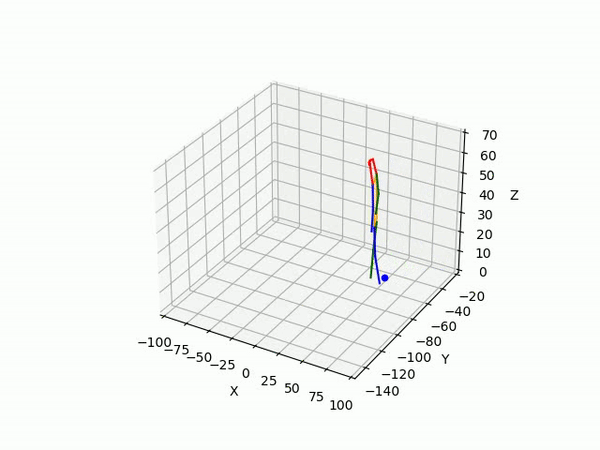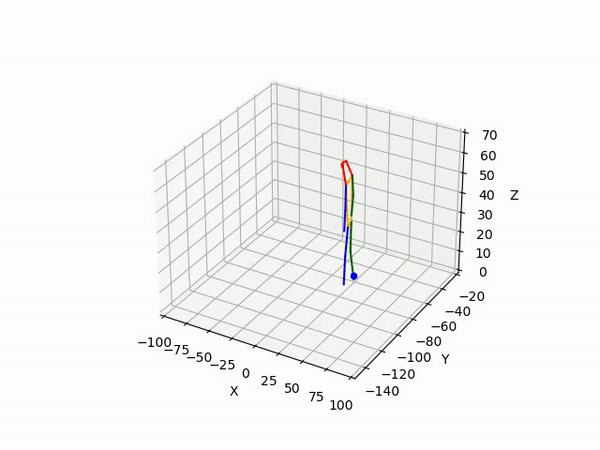
2. Predicting 3D skeleton and trajectory
Result
Spring 2022
2D Pose Estimation
We experimented extensively with Openpose in both real-world and simulation settings. For the real-world data, we experimented on the Shibuya crossing live video – a traffic intersection that streams a live video feed 24/7. For the simulation setting, we set up the JTA Dataset Mods [2] to hook on to the GTA 5 game and collect the dataset.
Experiments and Results on Shibuya videos
When we naively apply openpose on the test video we get the below result:

But since we know there are people mainly in the bottom left, and top right portion of the frame when people are waiting and in the middle when people are crossing the intersection, we can crop the video to these sections of the video and run Openpose. The results are as follows:
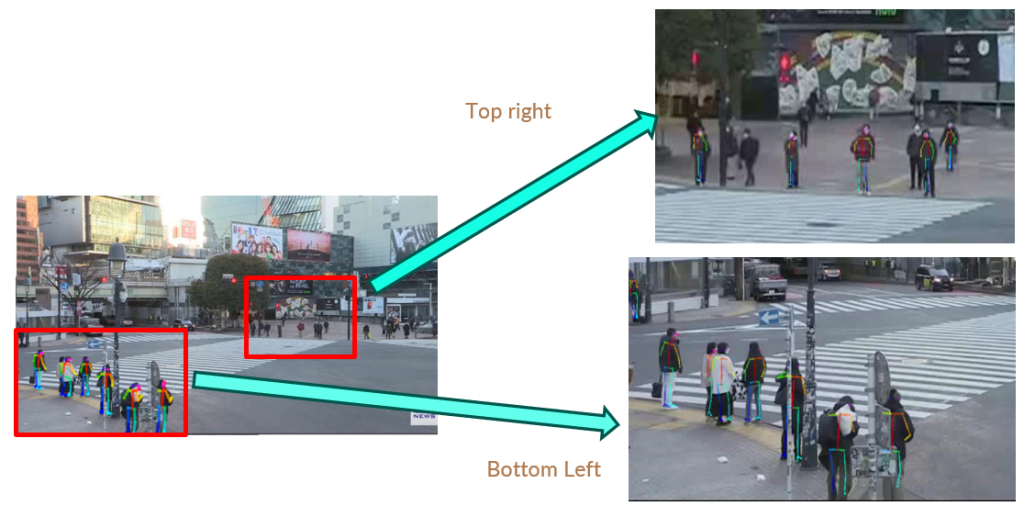
We can observe that Openpose performs well for a specific resolution of video and scale of persons in the video. We make the following observations:
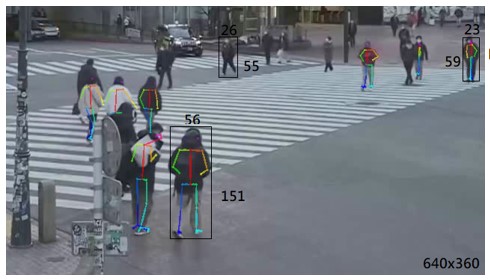
As a base requirement, we require a relative scale: of 1/10 x 1/16 (Height x Width), and an absolute scale: of 59 x 23 (pixels). We found that anything lesser than this has a low detection fidelity.
We also did some experiments on various Zoom levels:
We also experimented with combining both cropping and zooming the video:
We can see an improvement in results by crop and zoom of the video. But is this a feasible method? Can we always do this during deployment in our test domain?
Disadvantages:
(1) Low resolution causes the model unable to tell objects from people.
(2) Low resolution makes it hard for models to tell people apart from the background.
(3) Existing models are not trained with the “bird’s eye view”.
A solution we build our dataset since it has the following advantages:
(1) Control the number of cameras and the angle of the cameras
(2) Define the scene: weather, time of the day, etc.
(3) Obtain ground truth joints key points from the physical engine.
So we try the above approach even on the synthetic data. And the results are as follows:

We can observe that the OpenPose mispredicted some joints even after crop-and-resize. Hence, we can’t use Openpose off-the-shelf and we need to train our pose estimation models on the dataset we generate.
3D Pose Estimation
1. PARE
2. ROMP
PARE and ROMP fail when camera angles are elevated
Failure cases:
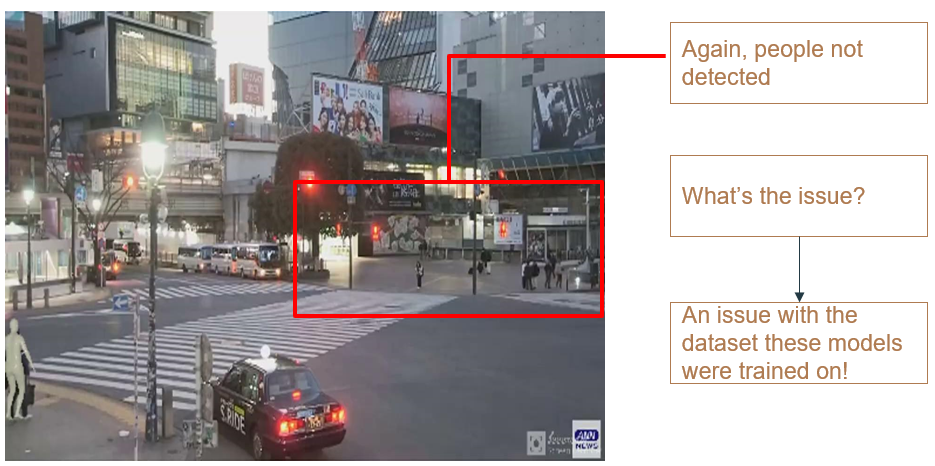

We can see that even with cropping and applying super-resolution the results aren’t great. This is also an issue with the dataset. The datasets these models were trained on, were as follows:
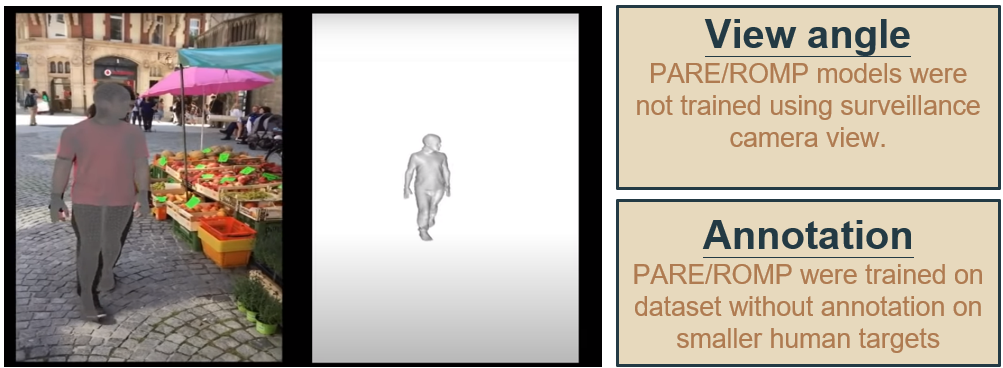
Hence, both ROMP and PARE don’t perform too well in the test domain. We then test the BEV model on the Tepper dataset.
3. BEV


Hence, like in the 2D pose estimation case we still have to train the BEV model on the GTA5 dataset we create
References
[1] Zhe Cao et. al. “OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields” CVPR 2017
[2] Fabbri, Matteo, et al. “Learning to detect and track visible and occluded body joints in a virtual world.” ECCV 2018.
[3] Ledig, Christian, et al. “Photo-realistic single image super-resolution using a generative adversarial network.” CVPR 2017.
[4] Wang, A., Biswas, A., Admoni, H., & Steinfeld, A. (2022). Towards Rich, Portable, and Large-Scale Pedestrian Data Collection. ArXiv, abs/2203.01974.