

Menu
Fall 2022
Spring 2022
Fall 2022
2D Pose Estimation
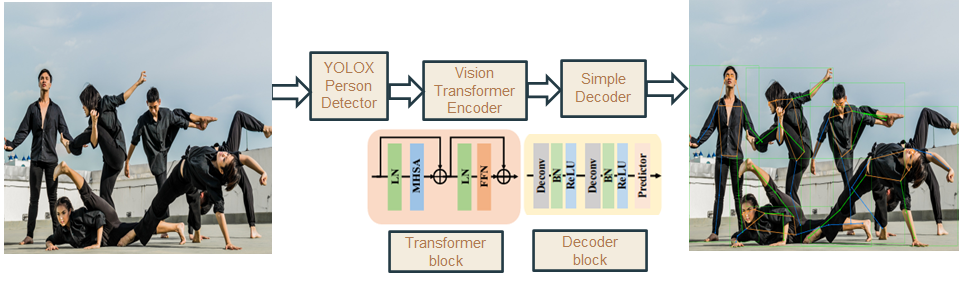
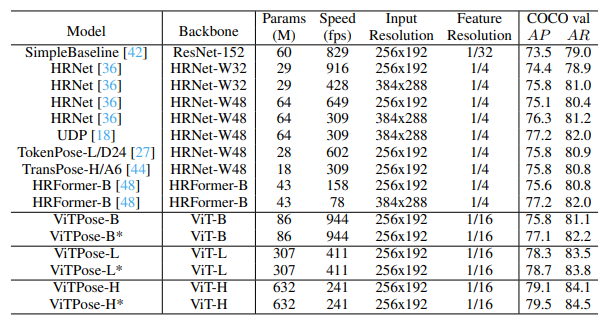
ViTPose [6]
ViTPose is a 2D pose estimation that has SOTA results on COCO, OCHuman, and CrowdPose datasets. It builds on the Vision Transformer [7], using it as an encoder, and uses a simple decoder model to regress the key points of a person. ViTPose is a top-down model and performs pose estimation in two steps: – 1. Perform person detection to detect all pedestrians in a scene, 2. Perform pose estimation within the detected bounding boxes.

Spring 2022
2D Pose Estimation
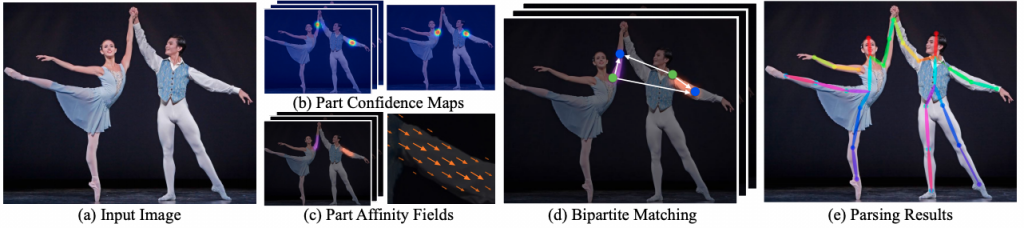
Openpose [1]
Openpose is a 2D pose estimation model developed at CMU. It is considered the state-of-the-art approach for real-time 2D human pose estimation. The codebase is open-sourced on GitHub and is very well documented. Openpose is originally written in C++ and Caffe. Its pipeline is as follows:
3D Pose Estimation
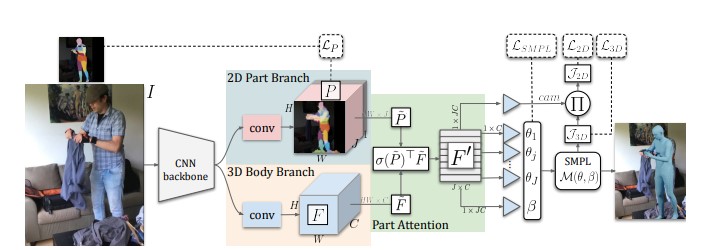
PARE [2]
PARE, which is a direct successor of VIBE [3], is an occlusion-robust human pose and shape estimation method. It uses a soft attention mechanism, called the Part Attention REgressor (PARE), which learns to predict body-part-guided attention masks. Most methods rely on global feature representations, making them sensitive to even small occlusions. In contrast, PARE’s part-guided attention mechanism overcomes these issues by exploiting information about the visibility of individual body parts while leveraging information from neighboring body parts to predict occluded parts. Its pipeline is as follows:
ROMP [4]
ROMP focuses on the regression of multiple 3D people from a single RGB image. Existing approaches predominantly follow a multi-stage pipeline that first detects people in bounding boxes and then independently regresses their 3D body meshes. In contrast, ROMP regresses all meshes in a One-stage fashion for Multiple 3D People (termed ROMP). The approach is conceptually simple, bounding box-free, and able to learn a per-pixel representation in an end-to-end manner. The pipeline is as follows:
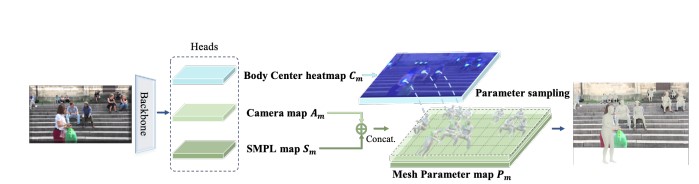
BEV [5]
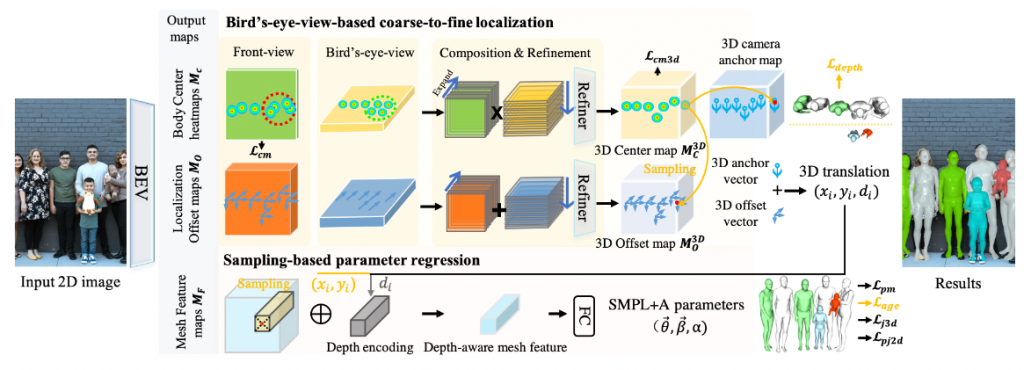
Given an image with multiple people, BEV’s goal is to directly regress the pose and shape of all the people as well as their relative depth. Inferring the depth of a person in an image, however, is fundamentally ambiguous without knowing their height. This is particularly problematic when the scene contains people of very different sizes, e.g. from infants to adults. First, the authors develop a novel method to infer the poses and depth of multiple people in a single image. While previous work that estimates multiple people does so by reasoning in the image plane, BEV adds an additional imaginary Bird’s-Eye-View representation to explicitly reason about depth. BEV reasons simultaneously about body centers in the image and in-depth and, by combing these, estimates 3D body position. Unlike prior work, BEV is a single-shot method that is end-to-end differentiable. Second, height varies with age, making it impossible to resolve depth without also estimating the age of people in the image. To do so, we exploit a 3D body model space that lets BEV infer shapes from infants to adults. The pipeline is as follows:
References
[1] Zhe Cao et. al. “OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields” CVPR 2017
[2] Kocabas, Muhammed, Nikos Athanasiou, and Michael J. Black. “Vibe: Video inference for human body pose and shape estimation.” CVPR 2020.
[3] Kocabas, Muhammed, et al. “Pare: Part attention regressor for 3d human body estimation.” CVPR 2021.
[4] Sun et al. “Monocular, One-stage, Regression of Multiple 3D People” ICCV 2021.
[5] Sun et al. “Putting People in their Place: Monocular Regression of 3D People in Depth” CVPR 2022.
[6] Xu, Yufei, et al. “ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation” NeurIPS 2022
[7] Kolesnikov, Alexander, et al. “An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale” ICLR 2021