

2D Pose Estimation
ViTPose [1]
ViTPose is a 2D pose estimation that has SOTA results on COCO, OCHuman, and CrowdPose datasets. It builds on the Vision Transformer [2], using it as an encoder, and uses a simple decoder model to regress the key points of a person. ViTPose is a top-down model and performs pose estimation in two steps: – 1. Perform person detection to detect all pedestrians in a scene, 2. Perform pose estimation within the detected bounding boxes.
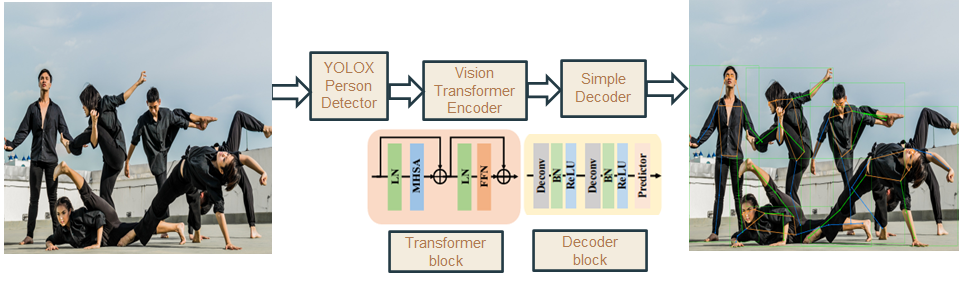

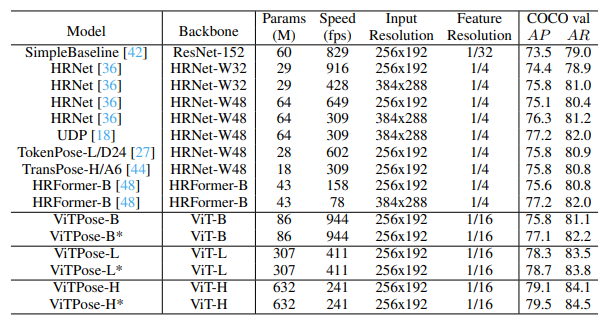
References
[1] Xu, Yufei, et al. “ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation” NeurIPS 2022
[2] Kolesnikov, Alexander, et al. “An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale” ICLR 2021