Before diving straight into our approach we would like to introduce some key components we will be going back to throughout our experiments.
Previous Works
NeRF

Recently there has been an explosion in NeRF or Neural Radiance Field [1] which explores novel-view synthesis by using a sparse set of 100 input images. This gained popularity because of its ability to render mostly detailed scenes without having a continuous training space. It is based on an 8 layered Multi-Layer Perception (MLP) network that takes in a 5D input: 3D coordinate and viewing direction theta and rho. Using classical rendering techniques they were able to achieve a reconstruction as the left from the sparse input.
3DMM
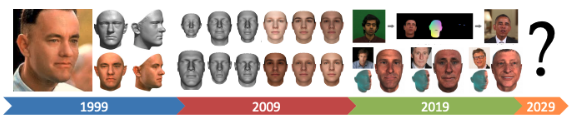
3D Morphable Models (3DMM) [2] have been around for decades and essentially serve as a way to generate new facial models with variable parameters. The three main components are the (1) Shape Models, (2) Expression Models, and (3) Appearance Models. The Shape Models are split into global models for the face surface and local models for the facial parts. The Expression Models control the various expressions that can be modeled. And lastly, the Appearance Models handle the variation in illumination and appearance. While there has been great progress over the years, finer details like mouth interior, and hair are not able to be modeled.
It is important to note these three factors as they set up the foundation for Morphable Facial Neural Radiance Field which will be introduced in the next section
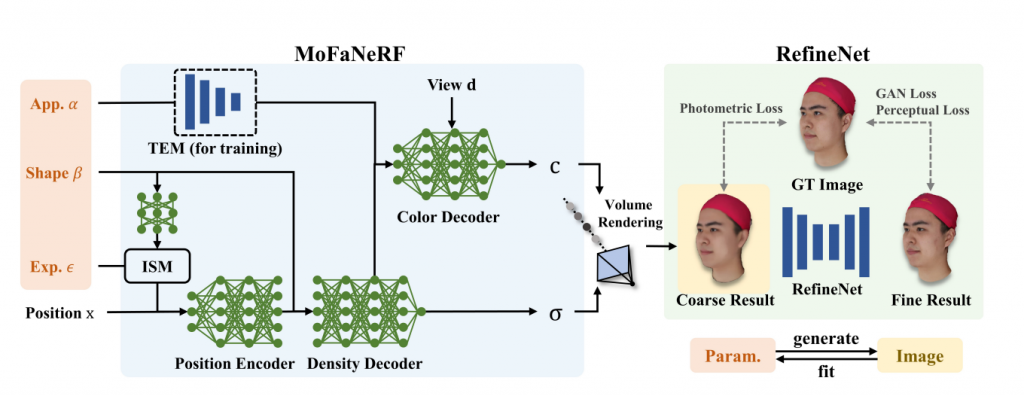
Morphable Facial Neural Radiance Field (MoFaNeRF)
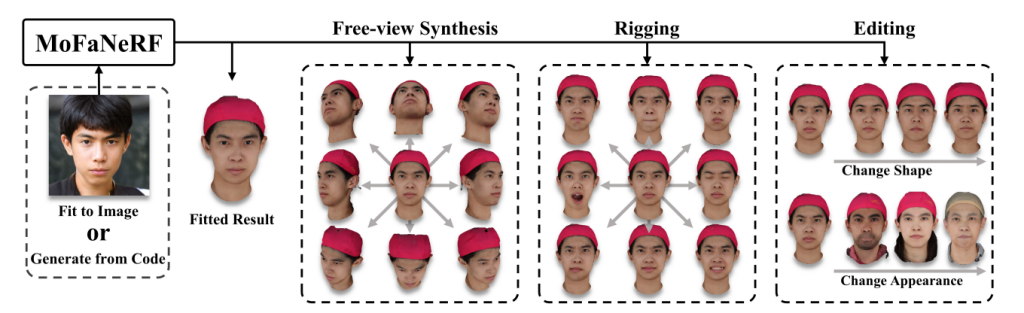
The Morphable Facial Neural Radiance Field (MoFaNeRF) is a parametric head model that combines NeRF and GAN and can render photo-realistic free view generation, image-based fitting, and face rigging + editing. Other than the space coordinate and view direction, the inputs of a conventional NeRF, MoFaNeRFs also depend on the appearance code α, shape code β, and expression code ε to output radiance of a space point for photo-realistic image synthesis. The three codes α, β, and ε come from a 3DMM mentioned in the previous section.
With the help of these additional parameters, MoFaNeRF has higher controllability over the generated images, since it can
- Memorize and parse large-scale face datasets.
- Disentangle parameters like shape, appearance, and expression.
Compared to conventional 3DMMs, MoFANeRF shows the ability to model finer details, which include the interior of the eyes, mouth, and also beards.
Dataset Details
FaceScape
One of the primary datasets we will be using is the FaceScape Dataset [3]. This is also the same dataset that was used by MoFaNeRF. In this data, you will observe the participants wearing a red hat to cover any hair features as they primarily focus on their facial expressions. Below you can see a few examples of what the dataset looks like.

This dataset contains about 359 subjects with 20 different expressions for a total of over 7000 different faces. Each participant for every expression has multiple images from different viewing directions. One of the caveats of this dataset is that is predominantly Asians. This is one of our core challenges of increasing generalizability.
Bp4D+
In order to balance the data distribution, we seek to augment the FaceScape/MoFaNeRF dataset with BP4D+ [4]. Unlike FaceScape, this is a Multimodal Spontaneous Emotion dataset. This data was collected by asking the participants to perform a task that elicits certain expressions or emotions as opposed to asking the participants to perform a particular expression. For example one of the tasks asked the participants to put their hands in a bucket of ice water which resulted in a pained expression. These expressions are encoded using Facial Action Coding System (FACS) which is described in detail in the next section. Below you can see some examples of the diversity in this dataset.

One of the things to note is that this is not a multi-view image dataset, but rather a video dataset with mostly front-facing videos. While we have the advantage of temporal relations between frames, we don’t have multiple views for each of the participants and the expressions.
Facial Action Encoding Units
Facial Action Coding System (FACS)
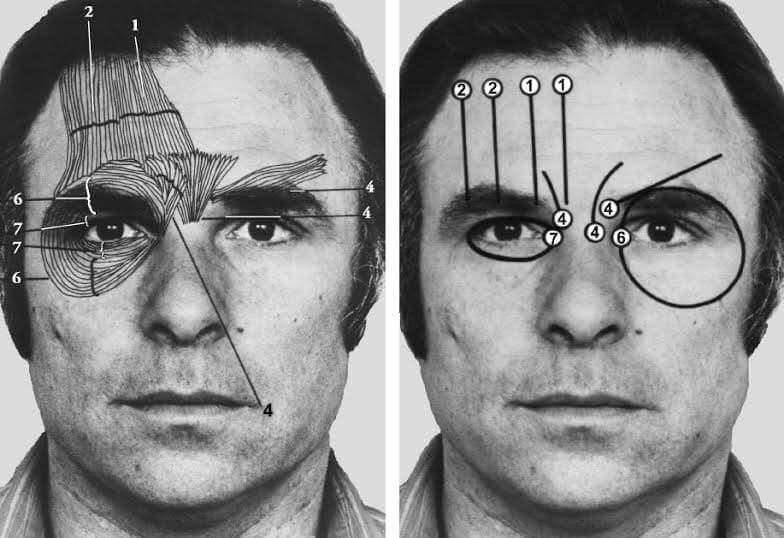
Facial Action Coding System (FACS), is a facial movement encoding system that breaks down facial expressions into individual muscle movements, called Action Units (AUs). It was developed by Carl-Herman Hjortsjö, later adopted by Pual Ekman and Wallace V. Friesen, and published in 1978 [5]. With FACS, we can encode and represent different expressions as combinations of AUs. Take a smile as an example: a smile can be represented as a combination of AU06 Cheek Raiser, and AU12 Lip Corner Puller.


References
- Mildenhall, Ben, et al. “Nerf: Representing scenes as neural radiance fields for view synthesis.” European conference on computer vision. Springer, Cham, 2020.
- Egger, Bernhard, et al. “3d morphable face models—past, present, and future.” ACM Transactions on Graphics (TOG) 39.5 (2020): 1-38.
- Yang, Haotian, et al. “Facescape: a large-scale high quality 3d face dataset and detailed riggable 3d face prediction.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
- Zheng Zhang, Jeff Girard, Yue Wu, Xing Zhang, Peng Liu, Umur Ciftci, Shaun Canavan, Michael Reale, Andy Horowitz, Huiyuan Yang, Jeff Cohn, Qiang Ji, and Lijun Yin, Multimodal Spontaneous Emotion Corpus for Human Behavior Analysis, IEEE International Conference on Computer Vision and Pattern Recognition (CVPR) 2016.
- Ekman P, Friesen W. Facial Action Coding System: A Technique for the Measurement of Facial Movement, Palo Alto: Consulting Psychologists Press. 1978
- Zhuang, Yiyu and Zhu, Hao and Sun, Xusen and Cao, Xun. MoFaNeRF: Morphable Facial Neural Radiance Field, arXiv preprint 2021.
- T. Baltrusaitis, A. Zadeh, Y.C. Lim, and L.-P. Morency. OpenFace 2.0: Facial Behavior Analysis Toolkit. FG 2018.