Challenges
Since we are using MoFaNeRF as our backbone, there are some concerns we want to address. This method performs well on new data that fits the original training data distribution but fails when it encounters data that is much different. We want to increase the generalizability by augmenting it with a more diverse dataset. The second concern we have is the ability to change expressions on our own. MoFaNeRF has an input expression parameter but the expression codes are learnable instead of being able to assign an input expression to learn on. For this reason, we introduced FACS to replace these expression codes. Our experiments below are split into two main sections.
- Retrain MoFaNeRF with FACS
- Retrain MoFaNeRF with BP4D+
Retraining
We want to address the challenges discussed earlier while we retrain MoFaNeRF so we broke them up into two parts.
Retraining MoFaNeRF with FACS
In order to have more controllability over the expressions of the generated images, we decided to retrain MoFaNeRF using Action Units as the expression codes instead of the original learned ones.
However, before the retraining, we will have to obtain the AUs for the FaceScape [3] dataset, which is the training data for MoFaNeRF. For this, we used OpenFace 2.0 [7], a facial behavior analysis tool, to predict the AUs for the images and used it as ground truth for training.

After the retraining, we are able to control the expressions with AUs to some extent. Let’s take a look at some results.
Successful Cases
Some of the AUs performed extremely well.
When increasing intensities of AU45 and AU06 + AU12, they gave us the expected expressions, blink and smile.
However, not all AUs are learning the correct expressions.
Failure Cases
When increasing the intensity of AU15, instead of depressing the lip corner, it was showing a cheek blower expression.
And when increasing the intensity of AU23, instead of tightening the lips, it was showing a mouth left expression.
We believe the cause of these failure cases comes from the fact that the AUs cannot represent some of the predefined expressions in the dataset well. In this case, the model is leveraging the AU that it deems closest to represent this expression instead.
Retraining MoFaNeRF with BP4D+
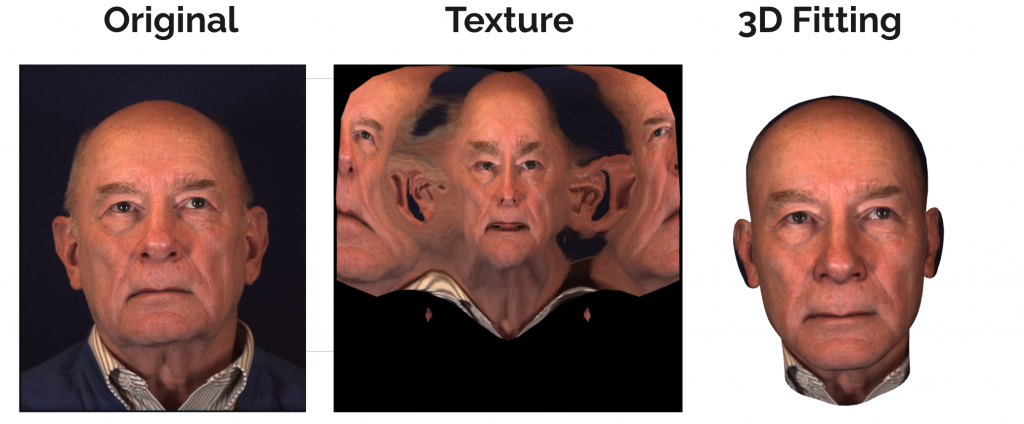
In order to prepare for retraining with BP4D+, we have a couple of extra steps than being able to use the dataset directly. One of the inputs to MoFaNeRF is the appearance code which is the texture map. When the paper trained MoFaNeRF they had access to texture maps per person which then they used to render the texture for the multi-view outputs. BP4D+ does not have this component so we needed to produce our own. The next image shows the base 3DMM model that we want to combine with a frame from the video sequence to result in a final fitting image onto the 3DMM.

As you can see the base model is lacking the space for the eye and mouth cavities. This is not an issue for the original MoFaNeRF training because they have multi-view data so they have a high fidelity scan to render the outputs. For this reason, we need to preserve the eye and mouth textures in order to create these multi-view images for the training sequence. This means we need to fill the empty cavities in the base model.
The process to fill the mesh is straightforward.
- Retrieve vertices, faces, and texture vertices
- Find vertex correspondence for chosen vertices
- Find corresponding texture coordinate
- Add new faces
The final mesh model after fitting will look something like this. As you can see the cavities are filled in and the texture matches the original input.
Next Steps
- Generate texture maps for the most neutral frame per subject to input to the Texture Encoding Module (TEM) during the MoFaNeRF training pipeline
- Select a set of expressions (and their associated AU’s), see which frame for a subject has the highest AU’s for that expression
- For more accurate depth representation on-base 3DMM, augment the base model with the partial frontal mesh provided in the BP4D+ dataset
- Retrain with BP4D+!