
Quantitative Results
Metrics
To evaluate under the LPS benchmarks, we use the Panoptic Quality (PQ) metric, which is defined as:
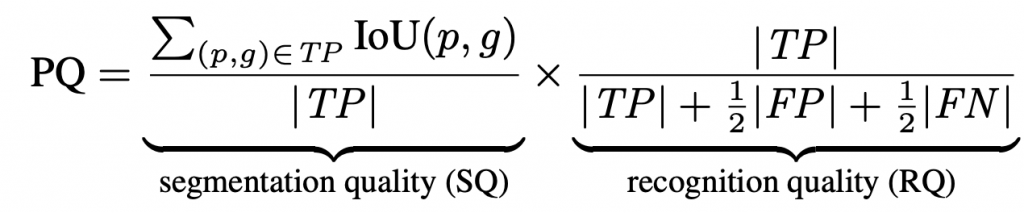
where TP, FP, and FN are defined per-segment. We also use precision and recall to evaluate instance segmentation performance and mean intersection-over-union (mIOU) to evaluate semantic segmentation performance.
For LiPSOW, we use the Unknown Quality (UQ) metric, which is recall-based. Concretely, this is defined as follows.
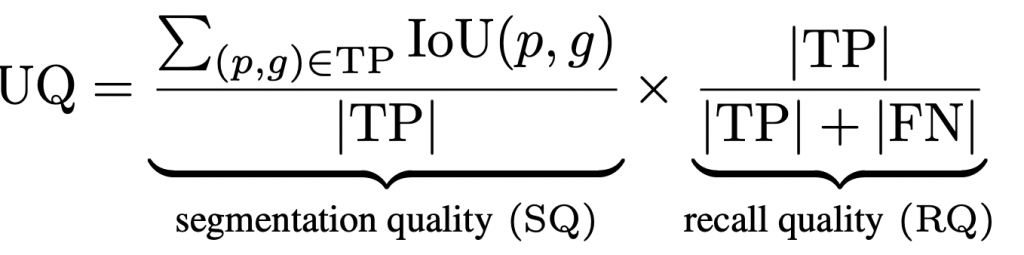
Evaluation of Standard Lidar Panoptic Segmentation
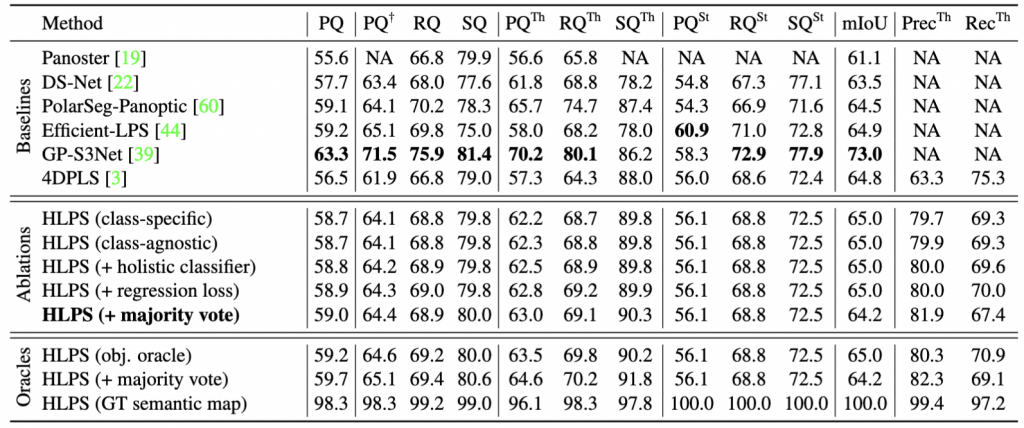
We first evaluate our method on standard Lidar Panoptic Segmentation benchmark using SemanticKITTI validation set. Though not our focus, we show “closed-world” panoptic accuracy for completeness. Our method is competitive with state-of-the-art methods that adopt newer and stronger semantic backbones. Given ground-truth semantic labels, our method achieves nearly perfect PQ (98.3%), indicating that future efforts should focus on semantic classification.
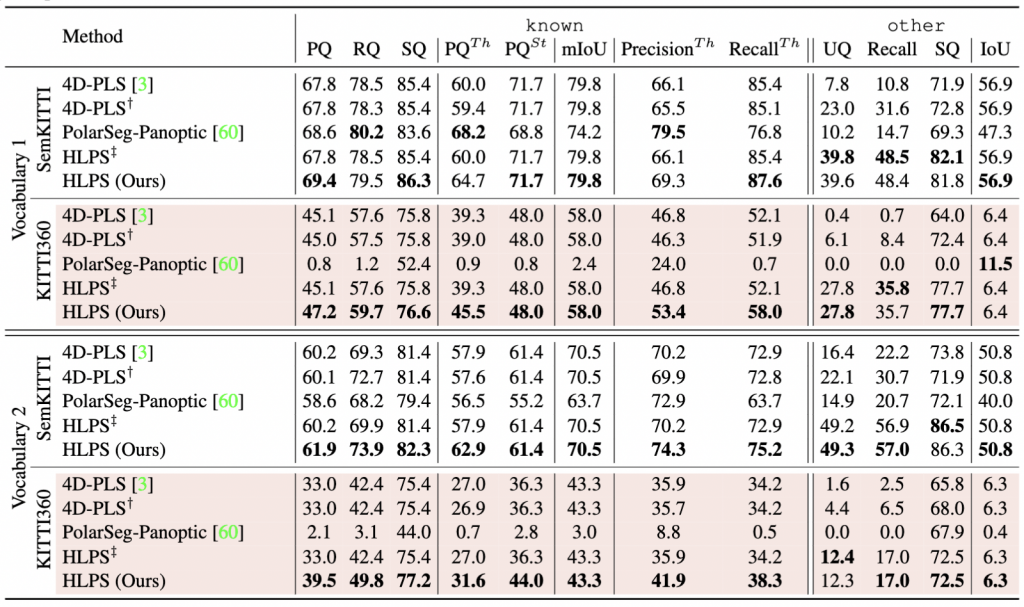
Evaluation of Open-World Lidar Panoptic KITTI benchmark
Algorithms must classify and segment novel-class instances (without reporting their
novel semantic labels). The following table reports within-dataset performance (SemanticKITTI), and cross-dataset performance (SemanticKITTI → KITTI360 ) for two different source-domain vocabularies, where Vocabulary 2 closely follows original SemanticKITTI class definitions, while Vocabulary 1 merges rarer classes into a catch-all other class. We report results of known thing and stuff classes using Panoptic Quality and mean-IoU, and for other class, we report Unknown Quality (UQ), Recall and IoU. Interestingly, HLPS outperforms baselines even for known classes (69.4% PQ compared with 67.8% 4D-PLS in-domain and 47.2% vs. 45.1% PQ cross-domain for Vocab. 1). For cross-domain other classes, HLPS recalls 35.7% of labeled instances, yielding 27.8% UQ while modified version of 4D-PLS can only recall 8.4%, leading to 6.1% UQ. We observe similar trends when using Vocab. 2, however, overall performance on known and other classes drops dramatically, even though we used exactly the same set of labels. Note that Vocabulary 1 generalizes much better across datasets, suggesting that grouping rare classes in a catch-all other leads to better generalization. These results also suggest that we do not need a separate geometric clustering module for other classes. Such an approach is similar to HLPS ‡ (which uses a learned instance grouping for thing classes and a separate hierarchical segmentation tree for other), which does not improve performance
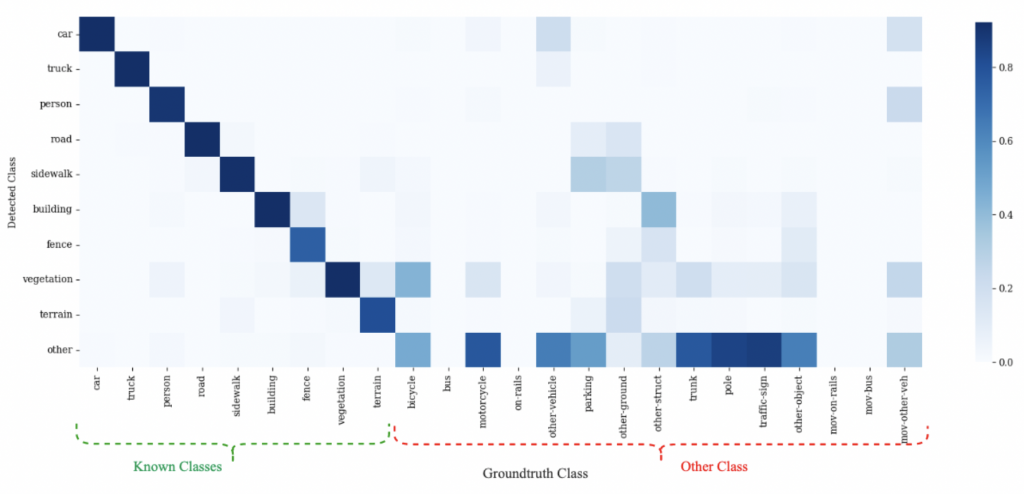
Confusion Matrix for HLPS
The extended confusion matrix for HLPS trained on SemanticKITTI and evaluated in domain (on SemanticKITTI), using Vocabulary 1. In the known classes, we observe confusion between terrain and vegetation. We also observe that several other points are misclassified as known. Other-vehicle is often misclassified as car or truck, while ground and parking are misclassified as sidewalk and road. This explains the low IoU observed on other in Semantic-KITTI.
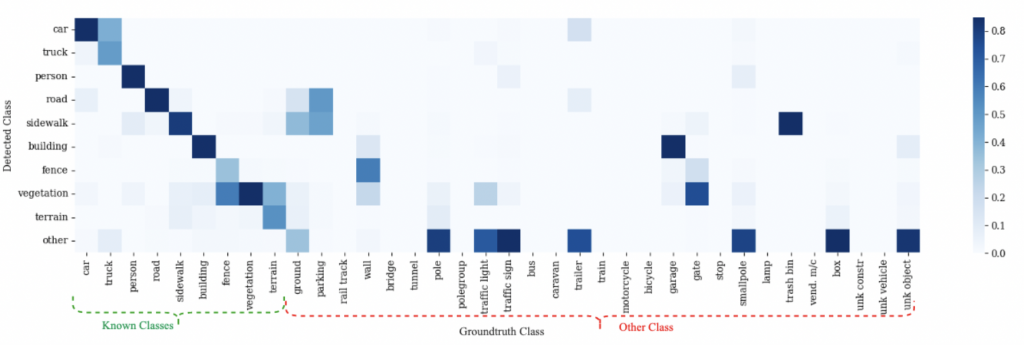
The extended confusion matrix for HLPS trained on SemanticKITTI and evaluated cross domain (on KITTI-360), using Vocabulary 1. Contrary to the in-domain confusion, we observe more confusion within known classes. For instance, car and truck are often confused with each other. Sidewalk is often misclassified as terrain, while almost all known classes are confused with vegetation. We also observe more confusion between known and other. Ground and parking are often predicted as road and sidewalk. Walls (a novel other-stuff class) is confused with fence, building, and vegetation, presumably due to similarity among their geometries. Trailer is frequently confused with car. Clearly, cross domain semantic segmentation is very challenging
Qualitative Results

We visualize the performance of HLPS on retrieving novel instances from SemanticKITTI. We show the ground-truth instance labels and predicted instances respectively. Instances from known classes are colored in shades of green and blue. The other class semantic prediction and instances are colored in red. In the first row, HLPS is able to classify and segment the trailer attached behind the car. In the second row, we observe a bus stop has been segmented as an instance. In the third row, a swing in the playground has been detected as part of the other class. In the fourth row, a stroller has been segmented by our method.

We visualize the performance of HLPS on retrieving novel instances from KITTI360. The first column shows the semantic predictions from HLPS, while the second column shows the corresponding instance predictions. As before, instances from known classes are colored in shades of green and blue. The other class semantic predictions and instance predictions are colored in red. In the first example, the car along with the trailer have been well segmented by our method. In the second row, HLPS successfully detects a detached trailer. In the third row, a previously unseen bus has been classified and segmented. In the final row, HLPS segments every pole, sign, and lamp in the scene