
Datasets
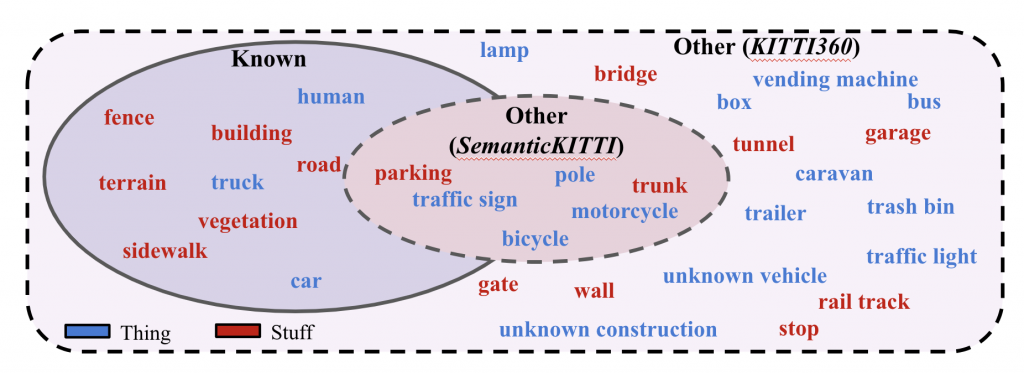
For LiPSOW, we use two datasets: Semantic-KITTI [1] and KITTI-360 [2]. The two datasets are recorded in Karlsruhe, Germany using the same sensor setup. However, they consist of different parts of the city (with no overlap), different weather conditions, and are collected several years apart. More importantly, they consist of different class vocabularies, with KITTI-360 having significantly more semantic categories and instances. These differences make these datasets suitable as per our definition of LiPSOW.
Under our setting, we use Semantic-KITTI as the training and validation set, and KITTI-360 as the test set. Since KITTI-360 consists of several classes and instances which may be unseen during training, this setting indeed helps evaluate open-world performance.
During training, a subset of classes are held-out as other. Concretely, their semantic labels are altered to other and instance labels are ignored. During validation, the ground-truth instance labels are used to evaluate performance. During testing, instance labels from novel categories (unseen during training)) are used to evaluate performance.
Vocabularies
We use two strategies to hold-out classes during training. Under the first (Vocabulary 1), the rarest classes from each super-category are held-out as other. On the other hand, the second strategy (Vocabulary 2) closely resembles the original Semantic-KITTI vocabulary, with the rarest class from each super-category held out as other.
References
- Behley, Jens, et al. “Semantickitti: A dataset for semantic scene understanding of lidar sequences.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019.
- Liao, Yiyi, Jun Xie, and Andreas Geiger. “KITTI-360: A novel dataset and benchmarks for urban scene understanding in 2d and 3d.” arXiv preprint arXiv:2109.13410 (2021).