
Hierarchical Lidar Panoptic Segmentation
LPS methods in literature employ point cloud backbones to classify points and learn to group points into object instances. These methods require instance-level supervision for all thing classes. In LiPSOW, the other class (for which no instance supervision is available) consists of both stuff and things, and methods should be able to cope with this. To develop a strong baseline for LiPSOW, we draw inspiration from work in LPS, perceptual grouping, and open-set recognition.

Our method, HLPS, employs a point-based encoder-decoder network to classify points into one of K+1 classes, as is the case in open-set recognition. In other words, the network is trained to distinguish the K known classes from other. In the second stage, we run a non-learned clustering algorithm on both things and other points, and learn a scoring function to get an instance segmentation. This is illustrated in Fig 1. Each component of our proposed method is explained below in further detail.
Semantic Segmentation
We use the well-consolidated Kernel-Point Convolution (KPConv) [1] backbone to operate directly on an input point cloud. We attach a semantic classifier on top of the decoder feature representation to output a semantic map which consists of K+1 classes. The network is trained using cross-entropy loss.
Object segmentation via point clustering
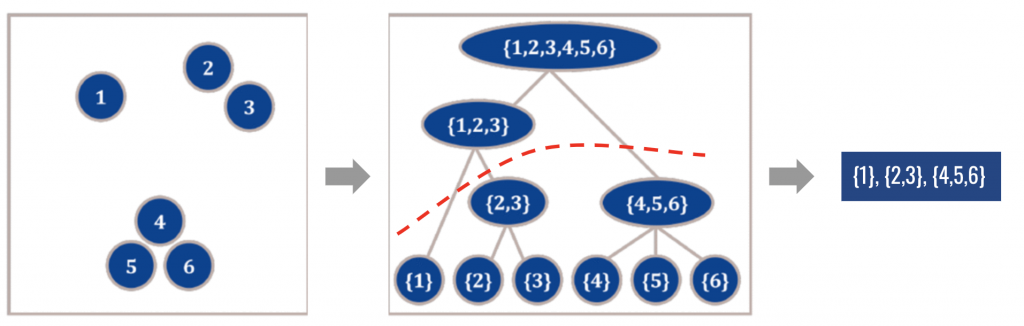
We first group points based on their spatial proximity using hierarchical clustering (HDBSCAN), which results in a hierarchy of segments (Fig 2-mid). From this segmentation tree, there exist combinatorially many per-point instance segmentation possibilities. Therefore, to get an instance segmentation from this tree, we need to make a cut through this tree (Fig 2-right).
To generate a cut from this tree, we learn a function which estimates how likely a subset a points represent an object. We use a PointNet classification network trained with a mean-squared error loss function, with an objective to regress the IoU of the segment with its matched ground-truth instance.
Given this function, we need to find where to cut this tree such that an overall segmentation score is as good as possible. In [2], it is shown that if the global segmentation score is defined as the worst objectness in the tree, the worst-case segmentation leads to an optimal cut (which can be obtained efficiently using dynamic programming).
References
- Aygun, Mehmet, et al. “4d panoptic lidar segmentation.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
- Hu, Peiyun, David Held, and Deva Ramanan. “Learning to optimally segment point clouds.” IEEE Robotics and Automation Letters 5.2 (2020): 875-882.