
Introduction
Our project is about human pose estimation and tracking. The task is to estimate the location of human joints in the scene and track humans simultaneously. This can be put onto end devices like AR headset, and be used for many downstream applications like activity recognition and superimposing artwork on persons, which could provide a more immersive AR experience. The goal of our project is to develop a 3D human pose estimation & tracking method that can handle multi-person in-the-wild scenes from a monocular camera, and hopefully it’s real-time.
Spring 2021
Problem Identification – the Limitation of State of the Art 3D Post Estimation and Tracking
Tracking methods on the 3D Poses in the Wild (3DPW) dataset [1]. 3DPW dataset contains 60 video sequences. Each human in the dataset is labeled with 14 joints. The left figure in below is the distribution of instances over visible joints. A large portion of human instances in the dataset are not fully visible.
For human pose estimation, we investigated a method called VIBE[2]. On the bottom left, we show the distribution of instances over visible joints, and on the bottom right, we show model’s pose estimation error over the number of visible joints. As the number of visible joints decreases, the mean per joint position error (MPJPE) increases correspondingly.


In further error analysis, we divided the occlusion case into four sub-categories: person-person, object-person, truncation and others. As a result, Person-Person Occlusion is the major sub-category for occlusion.
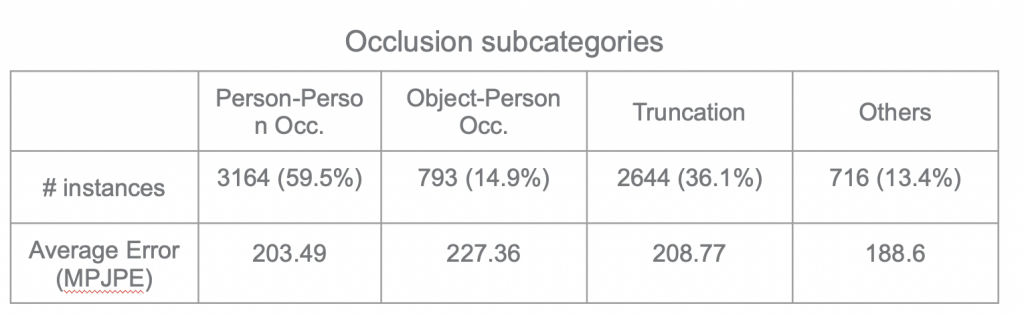
Person-Person Occlusion, Object-Person Occlusion, Truncation, and Others.
We have conducted similar error analysis on tracking part with CenterTrack [3] and categorized error into occlusion and large bounding box aspect ratio. Occlusion as well is the major cause of error.
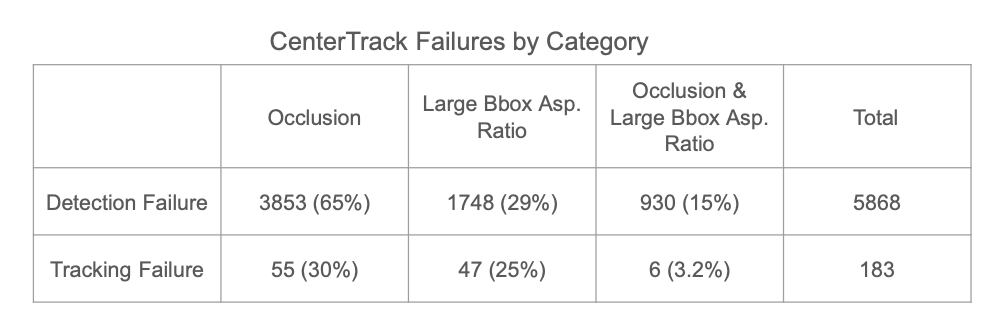
As both tracking and pose estimation suffer from occlusion, we decided as solving occlusion in human pose estimation and tracking; specifically, person-person occlusion as it is harder cases.
Tracking with Depth
For human tracking, we propose to do the tracking with depth information. The intuition is that persons overlapping each other in the image may have difference in depth in the 3D space. Such depth information can help solve tracking failure even with a simple algorithm like Hungarian. An example is shown in the images below. On the bottom left image, two person bounding boxes overlaps with each other; however, are separated apart in 3D spaces by a certain depth.

DeepSORT with Depth
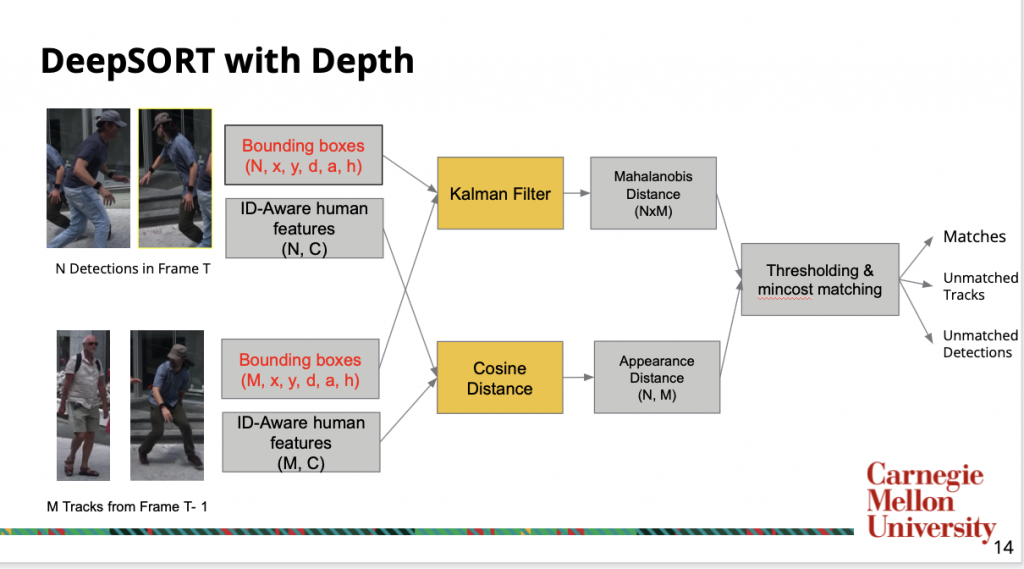
We started our method from DeepSORT [4]. We choose such method as it takes bounding boxes of each frame as input and produces the tracking results; therefore, we can easily convert any human recognition models’ output, such as human pose or segmentation, for the DeepSORT tracking.
The input to the original DeepSort contains N detections from current frame and M Tracklets from previous frames. Each bounding boxes and tracks is represented by x, y location, aspect ratio, and height, and there is a corresponding ID-Aware feature that is extracted by a network pretrained on a human re-identification dataset. To incorporate depth information, we modified the bounding box representation as x, y, location, depth, aspect ratio, and height.
DeepSORT uses bounding box to predict the track position in the current frame as a distribution from previous frames, and calculates the Mahalanobis distance to detected bounding boxes. In the meantime, an appearance metric is calculated for each detection and tracklet pair through cosine distance between ID-aware features. Finally, a thresholding and minimum cost matching is done on the combination of two metrics to produce match pairs. The unmatched track and detections are used to delete previous tracks and initiate new tracks.
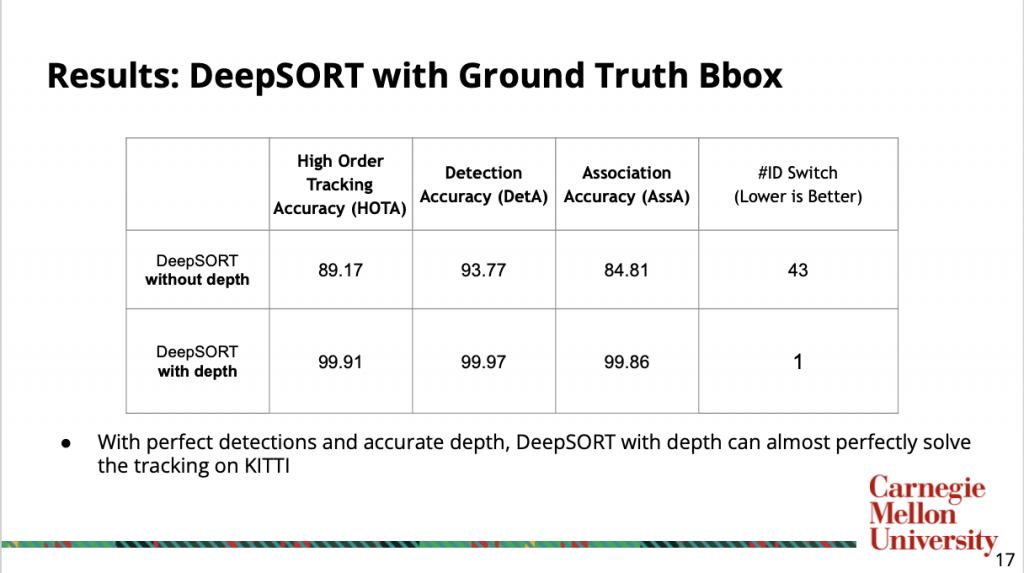
Below is the result of comparing DeepSORT with or without depth information on KITTI tracking dataset. We used ground truth bounding boxes as input to examine the effect of depth information. With perfect detection and accurate depth, DeepSORT with depth can perfectly almost solve tracking. A video of tracking result is at here
Learnable Keypoint Association of Human Pose Estimation
For human pose estimation, we proposed to use bottom up keypoint estimation methods that predict keypoint locations with relative depth, and do learnable keypoint association. As top-down methods will have the fundamental limitation in crowded scenes: a bounding box contains two or more persons confuses the estimator by predicting their body parts together as same instance, as shown in the bottom-left image. On the other hand, the bottom up keypoint estimation methods usually use a greedy algorithm for keypoint association, but this could also lead to sub-optimal results in crowded scenes like the image shown on bottom right. We hope to use a learnable keypoint association algorithm to remedy this.

For pose estimation with learnable keypoint association, we looked into a paper called Differentiable Hierarchical Graph Grouping for Multi-Person Pose Estimation [6]. It’s a bottom up method for 2D pose estimation, and we hoped to extend it to 3D. At a high level, it uses GNN to do keypoint association based on the output of a backbone keypoint estimation model. Below is the pipeline.
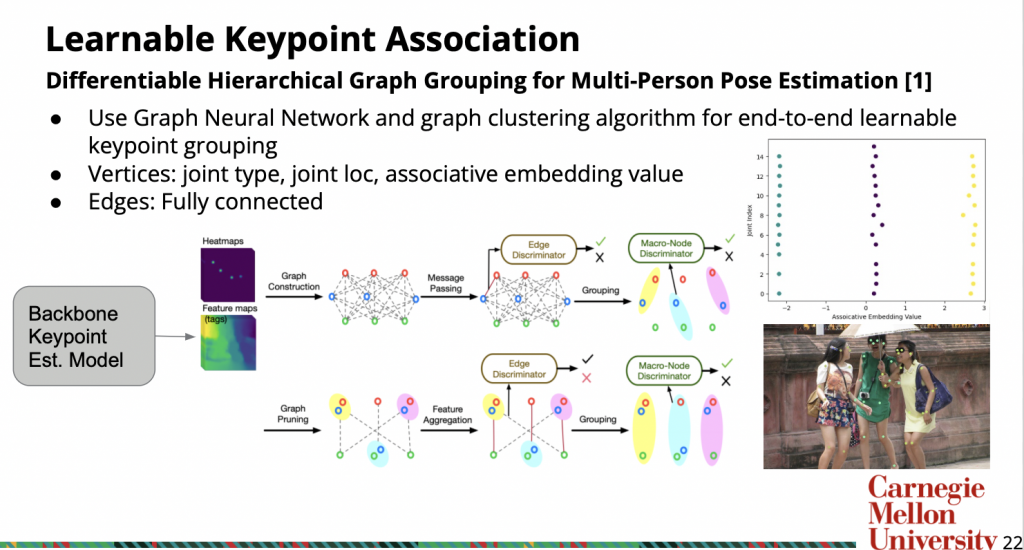
The output of the backbone model contains heatmaps for keypoints and feature map for associative embeddings. The associative embedding is essentially a scalar value for each joint. They are trained so that joints with closer AE value will belong to the same person. An example illustration is shown on the right. The image on the top right are the associative embeddings for each joint in the image below it.
Traditional methods use greedy association algorithms on AE to group keypoints This paper proposes first constructing a graph from the keypoints & AE, where the vertices are concatenation of joint type, joint location and AE value, and the vertices are fully connected except vertices with the same joint type. Then it uses GNN and iterative graph clustering to perform the keypoint grouping.
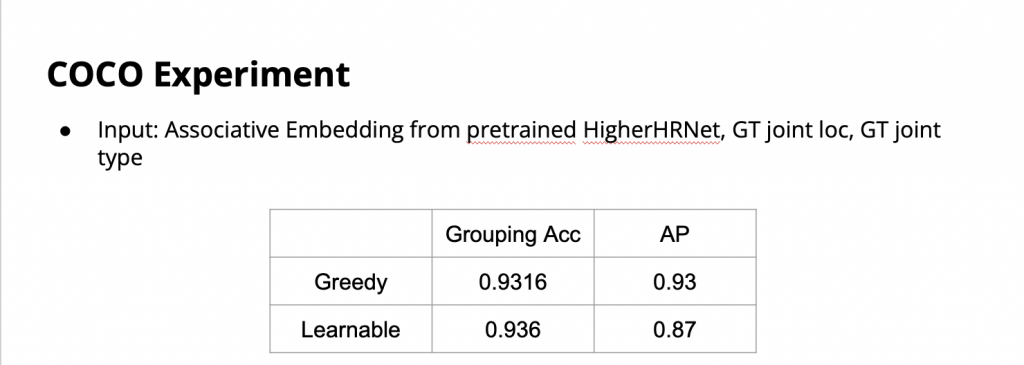
Below are the results when we re-implement the paper on MS-COCO dataset using the GT joint location, GT joint type and the AE from the pretrained HigherHRNet [5] as input. We did experiments of our reimplemented model on COCO dataset to validate how the learnable association can help. However, we found that we could not reproduce the performance claimed in the paper. From our experiment results, the reproduced model was not able to beat the greedy association method.
In first semester, we achieved the following:
- Occlusion is the major challenge for both human pose estimation & tracking
- We tried to reimplement the learnable graph association paper but did not work out
- Depth improves DeepSORT’s track association given perfect detection and depth as inputs
Given that we proved tracking with depth can almost perfectly solve the tracking problem and we could not reproduce the learnable association, we discussed this with our mentors and decided to shift our focus a little bit in the following semester.
Fall 2021
In this semester, we decided to target crowded scenes and focus more on the real-time aspect in AR glass settings. More specifically, we proposed the following light-weight pipeline for human pose estimation and tracking in crowded scenes.
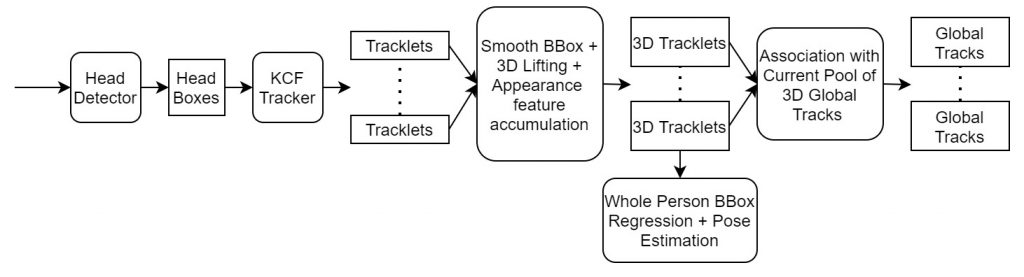
Given an input image, we will first use a head detector to get head bounding boxes. Then we do Kernelized Correlation Filter (KCF) tracking on the detections to get short tracklets. Next we smooth the tracklets and lift them to 3D using the camera parameters and the assumption that the head size of adult human are approximately the same. Based on these 3D tracklets, we will do global association of tracklets, whole person bbox regression and pose estimation. We want to do this whole pipeline in a online fashion.
Head Detection
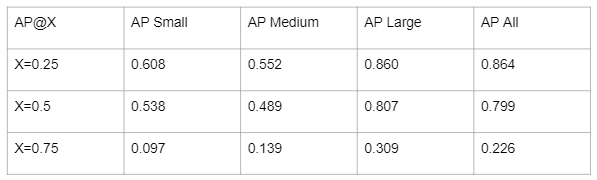
We started by collecting 6 video sequences of a person walking in crowds while holding a Gopro from youtube, and manually annotated head boxes on some frames. The collected dataset contains 66 annotated frames with 1990 annotated heads. We divide these heads into small/medium/large based on their pixel size, and use 4 sequences for training and 2 sequences for testing. We then finetuned a light-weight face detector, TinaFace, on our dataset to make it a head detector. The quantitative numbers of the finetuned head detector are shown below.
The detection results on a test video that’s not in our dataset can be found here.
Head Tracking
Given these detected bounding boxes, we then do KCF tracking on them to form short tracklets. KCF tracker is an efficient tracker that takes an initial bbox and train the kernelized correlation filter online based on the given target patch. However, the tracking will drift as the time goes. To make it more robust, we are doing a two directional fixed lag tracking, and the procedure is shown in the slides below
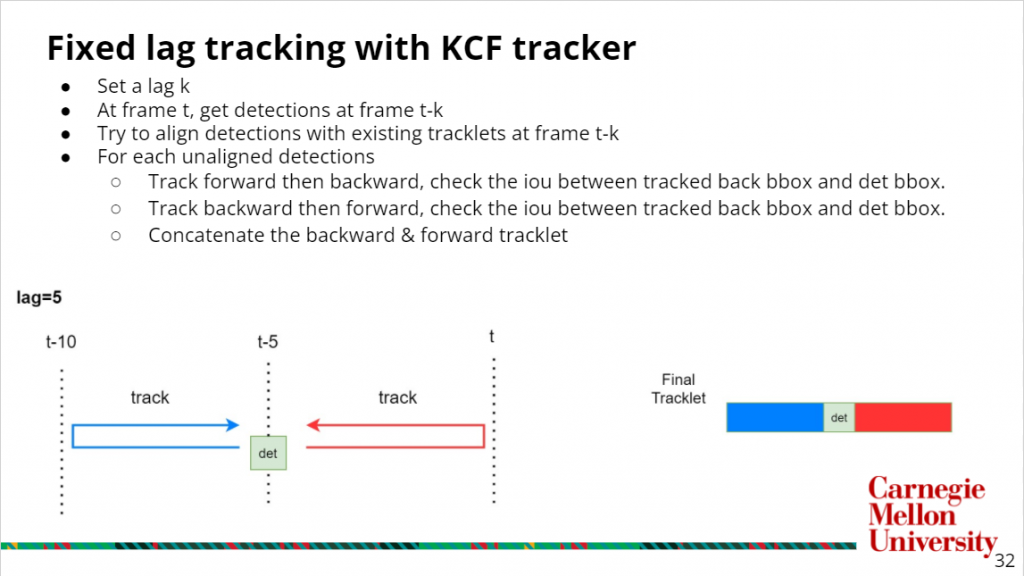
This fixed lag tracking will give us decent tracklets, but there will be tons of tracklets overlaps. The result can be found here.
To merge those overlapping tracklets and get cleaner tracklets, we use the steps shown in the slide below.
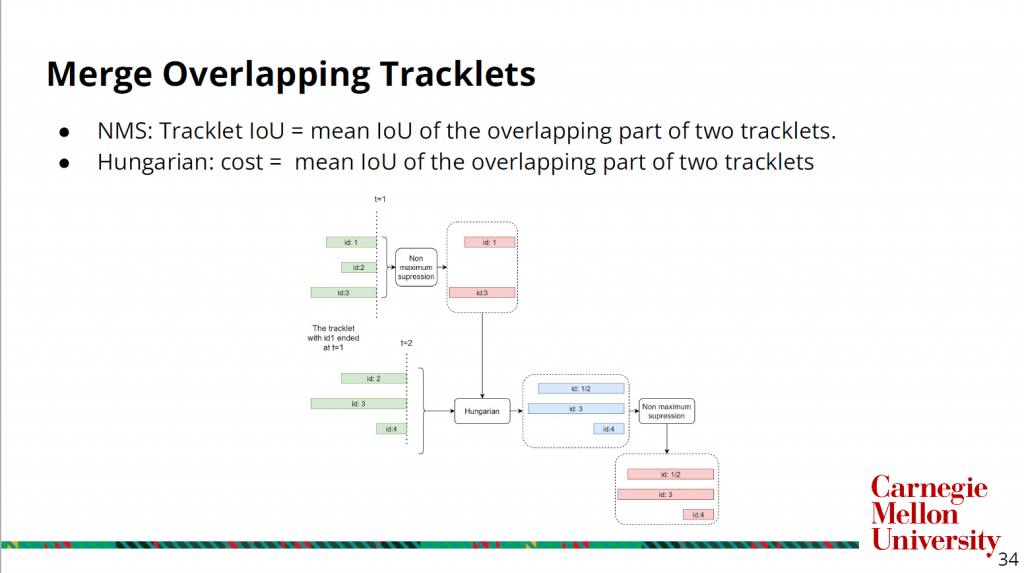
We define the IoU between two tracklets as the mean IoU of the overlapping part of two tracklets, and the use it as both the criterion for NMS between tracklets and the cost of Hungarian matching.
The tracklets in green are the output of the fixed lag tracking, and at the first frame, as an initialization step, we will just do tracklet NMS to get clean tracklets. At each of the later time stamp, we will do a Hungarian matching bewteen the fixed lag tracking output and the clean tracklets from the previous timestamp, which gives us the tracklets in blue. And we will then do the tracklet NMS to get clean tracklets for the current frame (in red). The result of this merging step can be found here.
After we have clean short tracklets, we want to lift the tracklets to 3D space for the down-stream global association and pose estimation. If camera matrix M is known, we can use the pseudo inverse of M to back project image points to 3D, up to a scale factor s. With the assumption that human head size is approximately the same and people don’t move much during the short trackle, we can optimize the equation below to get scale factors for each tracklet.
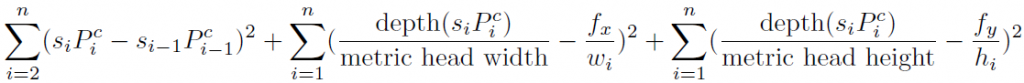
The si is the scale factor at frame i of a tracklet, and Pci is the pseudo-lifted head bounding box center at frame i of a tracklet. wi and hi are the width and height of the head bounding box at frame i of a tracklet, and fx and fy are the focal length of the camera.
Human BBox Regression and Pose Estimation
For human pose estimation, we do a simple regression using average metric human head size & body size to get the person bounding boxes, and then run HRNet on these boxes to get the human poses. By regressing the human bounding boxes from head bounding boxes, we are able to get much more human detections in heavy occlusion scenes compared to regular human detectors. An comparison of using HRNet with a human detector and HRNet with our regressed human boxes can be found here: human detector, regressed boxes.
Conclusion
In this project, we identified the major challenges in human pose estimation and tracking, demonstrated the effectiveness of tracking with depth, and proposed & implemented a light-weight pipeline for human pose estimation & tracking in heavy occlusion scenes.
References
[1] T. von Marcard, R. Henschel, M. Black, B. Rosenhahn, en G. Pons-Moll, “Recovering Accurate 3D Human Pose in The Wild Using IMUs and a Moving Camera”, in European Conference on Computer Vision (ECCV), 2018.
[2] M. Kocabas, N. Athanasiou, en M. J. Black, “VIBE: Video Inference for Human Body Pose and Shape Estimation”, in Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2020, bll 5252–5262.
[3] X. Zhou, V. Koltun, en P. Krähenbühl, “Tracking Objects as Points”, ECCV, 2020.
[4] N. Wojke, A. Bewley, en D. Paulus, “Simple Online and Realtime Tracking with a Deep Association Metric”, in 2017 IEEE International Conference on Image Processing (ICIP), 2017, bll 3645–3649.
[5] B. Cheng, B. Xiao, J. Wang, H. Shi, T. S. Huang, en L. Zhang, “HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation”, in CVPR, 2020.
[6] S. Jin et al., “Differentiable hierarchical graph grouping for multi-person pose estimation”, in European Conference on Computer Vision, 2020, bll 718–734.
[7] Y. Zhu, H. Cai, S. Zhang, C. Wang, en Y. Xiong, “Tinaface: Strong but simple baseline for face detection”, arXiv preprint arXiv:2011. 13183, 2020.