This is a capstone project with Aurora Innovation. Our advisor is Varun Ramakrishna from Aurora and Kris Kitani from CMU.
Enabling the perception system to detect objects in 3D space is an important problem in autonomous driving. Existing methods can be categorized as camera-only, LiDAR-only, and multi-sensor methods. For camera-only methods, depth estimation from images struggles to compete with the precision of LiDAR points For LiDAR only methods, it is hard to detect long-range objects since the point cloud gets sparser in remote regions. Therefore, it is intuitive to leverage multi-modal information from different sensors. Interestingly, existing multi-modal methods for 3D object detection usually fail to beat lidar only methods. This reveals that more efforts should be devoted to seeking an effective way to fuse different sensor information for 3D object detection.
This project starts with a comprehensive analysis of existing 3D object detection methods. The patterns of common failure cases can be extremely informative and enlightening. After this, the project aims to explore new sensor fusion methods in pursuit of solid improvement upon current popular methods.
In the spring semester, our team members focus on reimplementing and analyzing state-of-the-art methods in multimodal 3D object detection, including AVOD, PointPillar, PointPainting and conduct experiments in nuScenes and KITTI dataset.
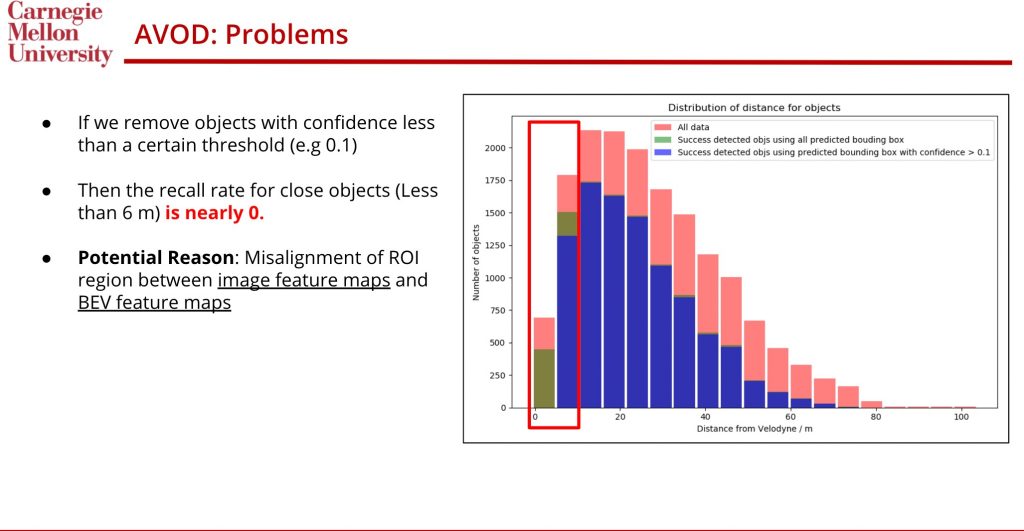
We start our experiment by first analyzing the AVOD, which is a common benchmark method that uses both image and LiDAR information. We realize that for super close objects (<10 meters), the AVOD performs surprisingly bad, and we argue that the main reason is the misalignment between frontal ROI Pooling and BEV ROI Pooling. Here is an illustrative figure:

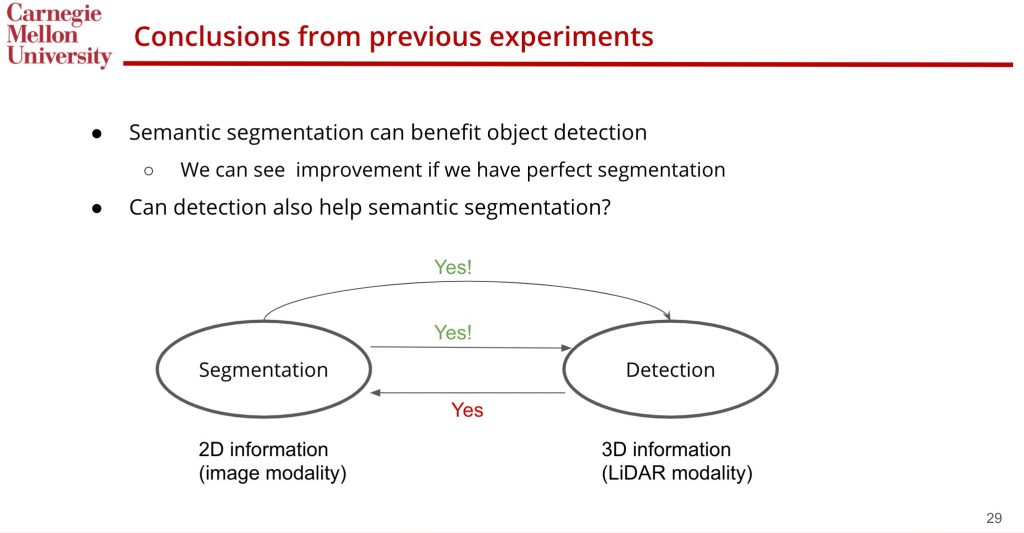
We also conduct experiments when we have perfect semantic segmentation predictions in PointPainting(PointPainting relies heavily on 2D image segmentation). Our experiment shows that the performance of 3D object detection is highly correlated to 2D image segmentation. Here is the corresponding slides:

Given this finding, we propose to improve 2D image segmentation given 3D object detection result. If that is also true, we could close the loop and let both tasks benefit each other. Here is the illustrative figure:
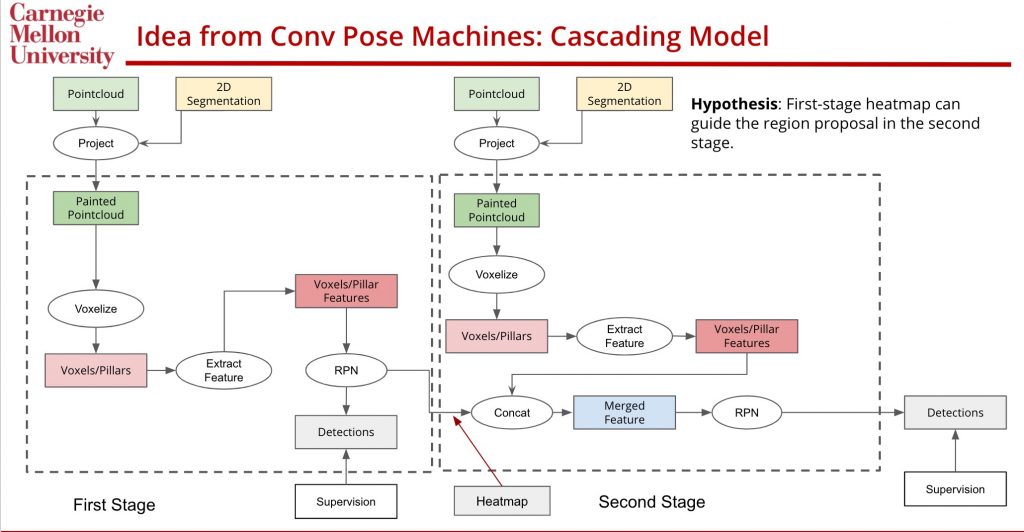
We propose to address two issues simultaneously: (1) fuse 3D information into 2D segmentation (2) sequential inference by cascading the detection model. We highlight the main process in the following two figures: